Plotting Static Maps with geopandas [Working with Geospatial data]¶
Table of Contents¶
- Introduction
- 1. GeoSeries and GeoDataFrame Data Structures
- 2. Plotting With GeoPandas
- 3. Choropleth Maps
- 4. Scatter Plots on Maps
- References
Introduction ¶
Geopandas provides easy to use interface which lets us work with geospatial data and visualize it. It lets us create high-quality static map plots. Geopandas is built on top of matplotlib, descartes, fiona and shapely libraries. It extends pandas and maintains geospatial data as data frames. It allows us to do operations using python which would otherwise require a spatial database like PostGIS. We'll explore geopandas in this tutorial and will plot various map plots like choropleth map, scatter plots on maps, etc.
Installation¶
!pip install geopandas
1. GeoSeries and GeoDataFrame Data Structures ¶
Geopandas has two main data structures which are GeoSeries and GeDataFrame which are a subclass of pandas Series and DataFrame.We'll be mostly using GeoDataFrame for most of our work but will explain both in short.
GeoSeries¶
It's a vector where each entry represents one observation which constitutes one or more shapes. There are basically three shapes that form one observation representing country, city, list of islands, etc.
- Points
- Lines
- Polygons
GeoDataFrame¶
It represents tabular data which consists of a list of GeoSeries. There is one column that holds geometric data containing shapes (shapely objects) of that observation. This column needs to be present to identify the dataframe as GeoDataFrame. This column can be accessed using the geometry attribute of the dataframe.
Let's load some datasets which are available with geopandas itself. It uses fiona for reading and writing geospatial data.
import geopandas
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
geopandas.datasets.available
geopandas has 3 datasets available. naturalearth_lowres and nybb dataset consist of Polygon shapes whereas naturalearth_cities consist of Points shape. We'll try to load the naturalearth_lowres dataset which has information about each country’s shapes. It also holds information about the estimated country population and continent.
world = geopandas.read_file(geopandas.datasets.get_path("naturalearth_lowres"))
print("Geometry Column Name : ", world.geometry.name)
print("Dataset Size : ", world.shape)
world.head()
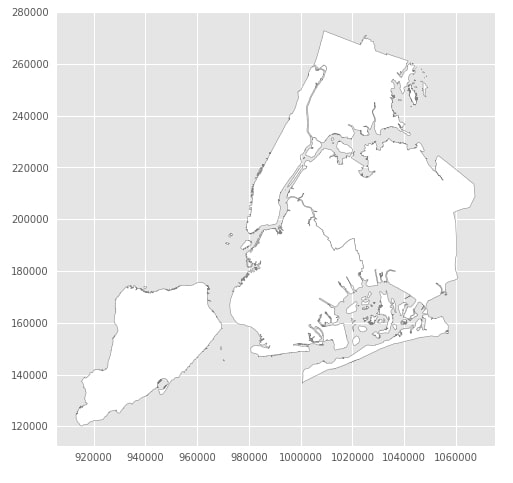
Below we are loading another dataset that holds information about new york and its districts.
nybb = geopandas.read_file(geopandas.datasets.get_path("nybb"))
nybb.head()
2. Plotting With GeoPandas ¶
We'll now explain plotting various map plots with GeoPandas. We'll also be using world happiness report dataset available from kaggle to include further data for analysis and plotting.
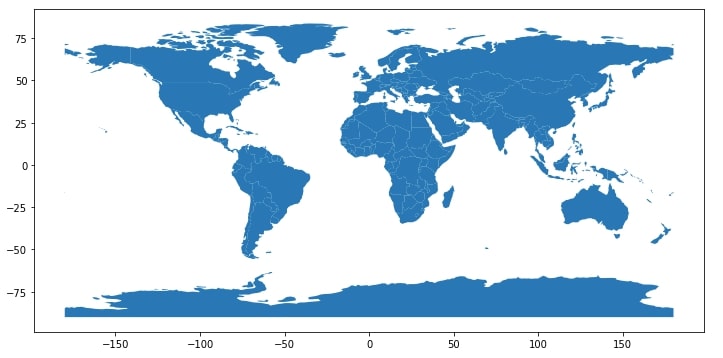
Geopandas uses matplotlib behind the scenes hence little background of matplotlib will be helpful with it as well. We'll start by just plotting the world dataframe which we loaded above to see results. We can simply call plot() on GeoDataFrame and it'll plot world countries on map. By default, it'll just print all countries with their borders. Below we are printing both world and new york maps.
world.plot(figsize=(12,8));
with plt.style.context(("seaborn", "ggplot")):
nybb.plot(figsize=(12,8), color="white", edgecolor="grey");
We'll now load our world happiness data. Please feel free to download a dataset from kaggle.
Dataset URL: World Happiness Report
Dataset also holds information about GDP per capita, social support, life expectancy, generosity, and corruption. We'll be merging this dataframe with geopandas world GeoDataFrame which we loaded above to combine data and then use combined data for plotting. Please make a note that the happiness report dataset does not have a happiness report for all countries present on earth. It has data for around 156 countries.
NOTE: Please make a note that we have manually made changes to the happiness dataset for around 10-15 countries where the country name was mismatching with name present in geopandas geodataframe. We have modified happiness report CSV to have the same country name as that of the geodataframe.
world_happiness = pd.read_csv("world_happiness_2019.csv")
print("Dataset Size : ",world_happiness.shape)
world_happiness.head()
NOTE: Please make a note that while combining normal dataframe to geodataframe we have used geodataframe first in merge operation. The main reason for doing so is that it'll output GeoDataFrame as output else it'll output normal pandas dataframe as output without geo functionalities. Please make a note that there will be few NANs present in the dataframe because we don't have happiness data for all countries of the world.
world_happiness_final = world.merge(world_happiness, how="left", left_on=['name'], right_on=['Country or region'])
print("Type of DataFrame : ", type(world_happiness_final))
world_happiness_final.head()
3. Choropleth Maps ¶
We'll now explain a few choropleth maps using the happiness dataset which we created above by combining geopandas world geodataframe with the world happiness report dataset.
3.1 Happiness Choropleth Map ¶
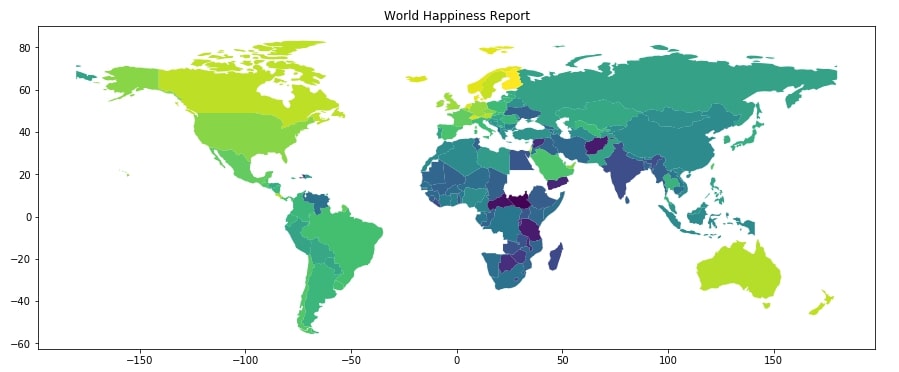
Below we are plotting our first choropleth map by simply calling the plot() method on geopandas GeoDataFrame by passing a column name as the first parameter to use for the map. We can pass other arguments like figsize, edgecolor, edgesize, etc for map. As it is a static matplotlib plot, we can call other matplotlib methods like title(), xlabel(), ylabel(), etc will work on it.
world_happiness_final.plot("Score", figsize=(15,10))
plt.title("World Happiness Report");
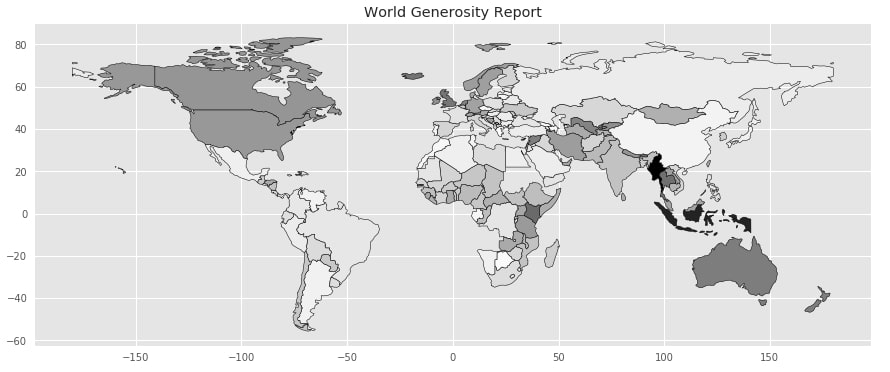
3.2 Generosity Choropleth Map ¶
Below we are generating another choropleth map using the Generosity column of the dataset. Please make a note that we are using the styling of seaborn and ggplot combined for this map as well.
with plt.style.context(("seaborn", "ggplot")):
world_happiness_final.plot("Generosity",
figsize=(15,10),
edgecolor="black",)
plt.title("World Generosity Report")
3.3 Happiness Choropleth Map with Legend ¶
We can also add legend and colormap to our choropleth map using the legend argument passed as True. We can also label our legend by passing arguments to the legend_kwds parameter.
world_happiness_final.plot("Score",
figsize=(18,10),
legend=True,
legend_kwds={"label":"Happiness by Country"})
plt.title("World Happiness Report");
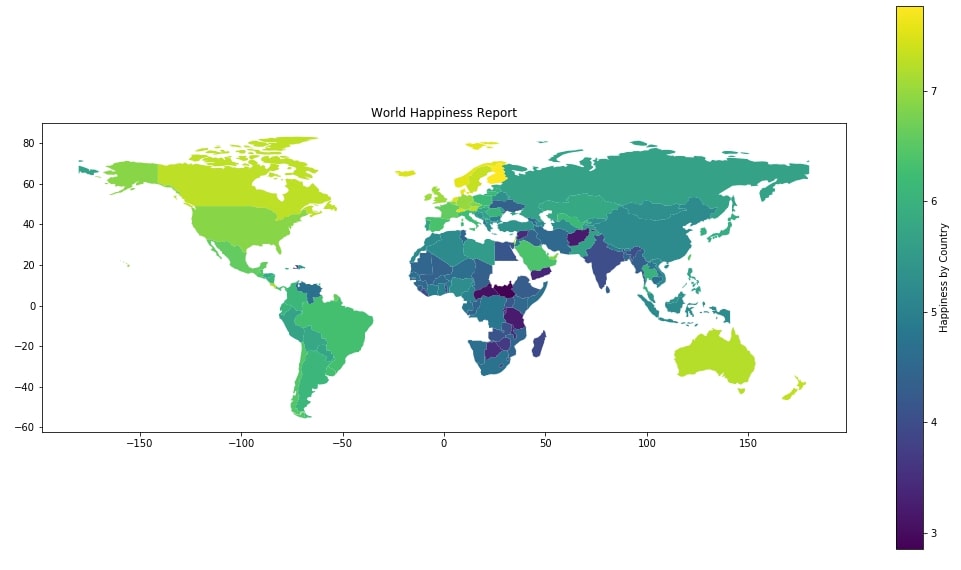
Below we are adding border as well to each country in choropleth map using edge color attribute. We are also moving colormap below by passing value orientation: horizontal to legend_kwds parameter.
world_happiness_final.plot("Score",
figsize=(18,12),
legend=True,
edgecolor="black",
legend_kwds={"label":"Happiness by Country", "orientation":"horizontal"})
plt.title("World Happiness Report");
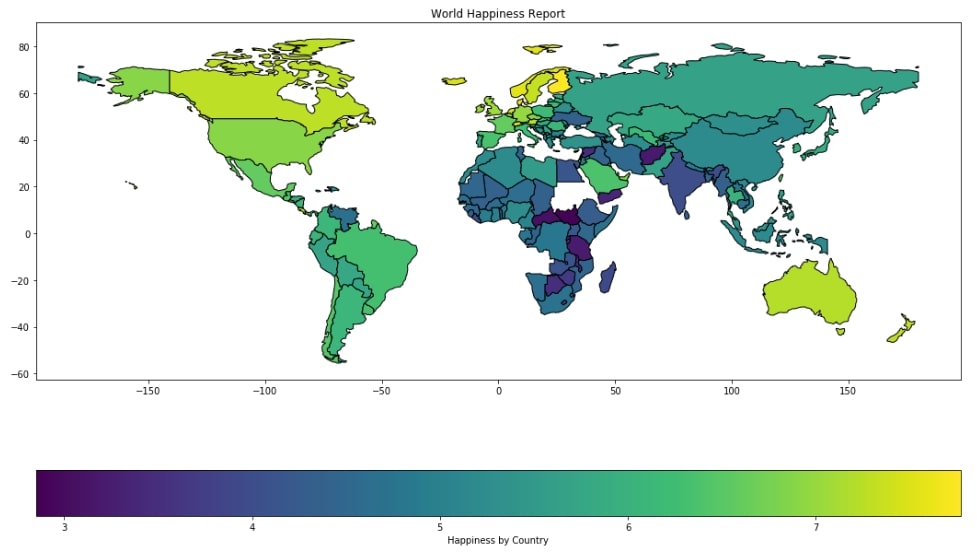
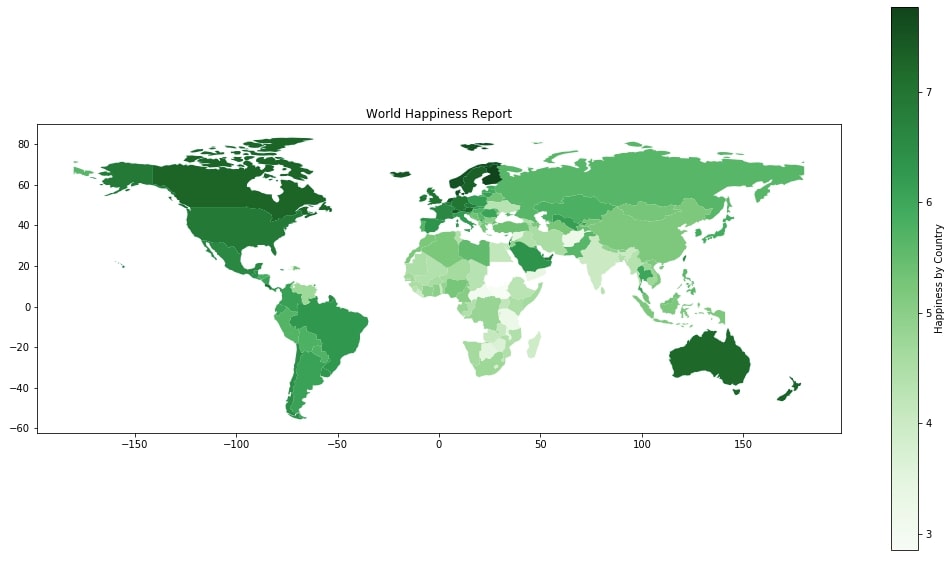
3.4 Happiness Choropleth Map with Legend & Different Colormaps ¶
We can change the default colormap of the choropleth map by passing different values for parameter cmap. It accepts a valid value from a list of available cmap values.
world_happiness_final.plot("Score",
figsize=(18,10),
legend=True,
legend_kwds={"label":"Happiness by Country"},
cmap=plt.cm.Greens,
)
plt.title("World Happiness Report");
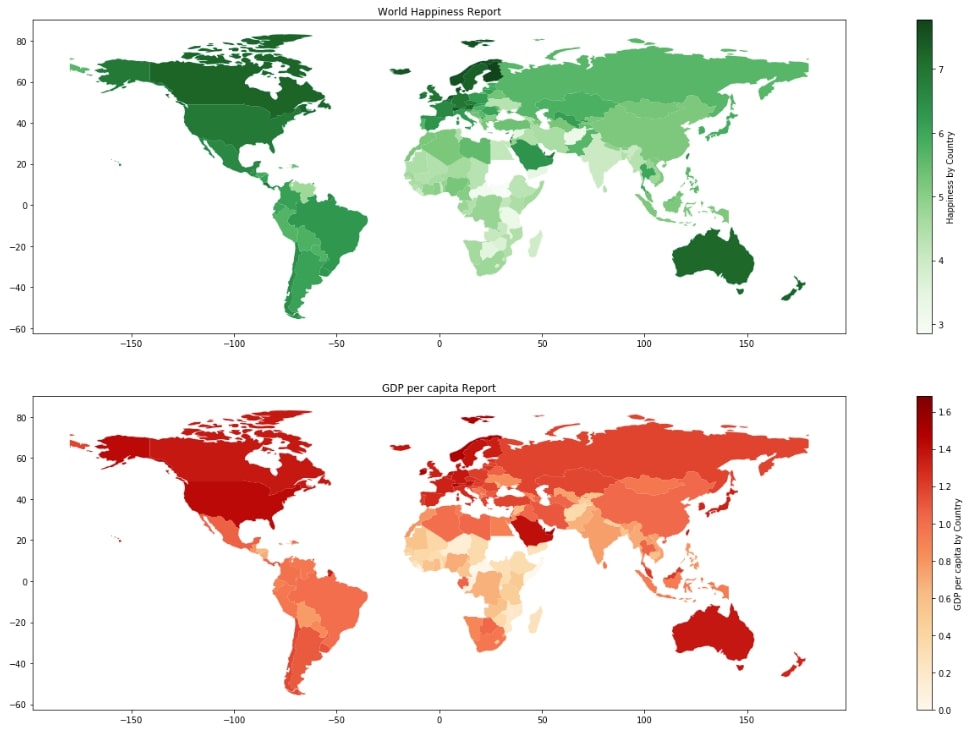
3.5 Multiple Choropleth Maps ¶
Below we are explaining another example where we can use a matplotlib axes system and can lay down more than one map plot in one image. We are plotting the choropleth map for Happiness and GDP Per Capita columns of data.
plt.figure(figsize=(30,15))
ax1 = plt.subplot(211)
world_happiness_final.plot("Score",
legend=True,
legend_kwds={"label":"Happiness by Country"},
cmap=plt.cm.Greens,
ax=ax1
)
plt.title("World Happiness Report");
ax2 = plt.subplot(212)
world_happiness_final.plot("GDP per capita",
legend=True,
legend_kwds={"label":"GDP per capita by Country"},
cmap=plt.cm.OrRd,
ax=ax2
)
plt.title("GDP per capita Report");
3.6 Happiness Choropleth Map with boundaries ¶
We can only highlight the boundaries of map plots without filling in any color. For this to work, we need to pass a special value none to parameter facecolor. Please make a note that we need to pass edgecolor as well which will be overridden with the color value of colormaps.
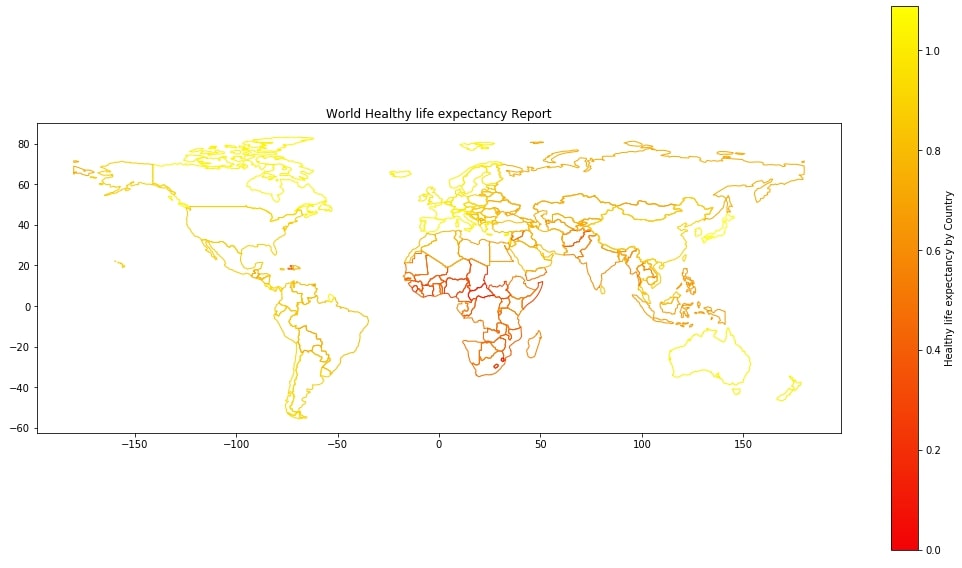
Below we are using healthy life expectancy as a column for plotting map.
world_happiness_final.plot("Healthy life expectancy",
facecolor="none",
edgecolor="black",
figsize=(18,10),
legend=True,
legend_kwds={"label":"Healthy life expectancy by Country"},
cmap=plt.cm.autumn)
plt.title("World Healthy life expectancy Report");
3.7 Choropleths Map with Missing Values handled ¶
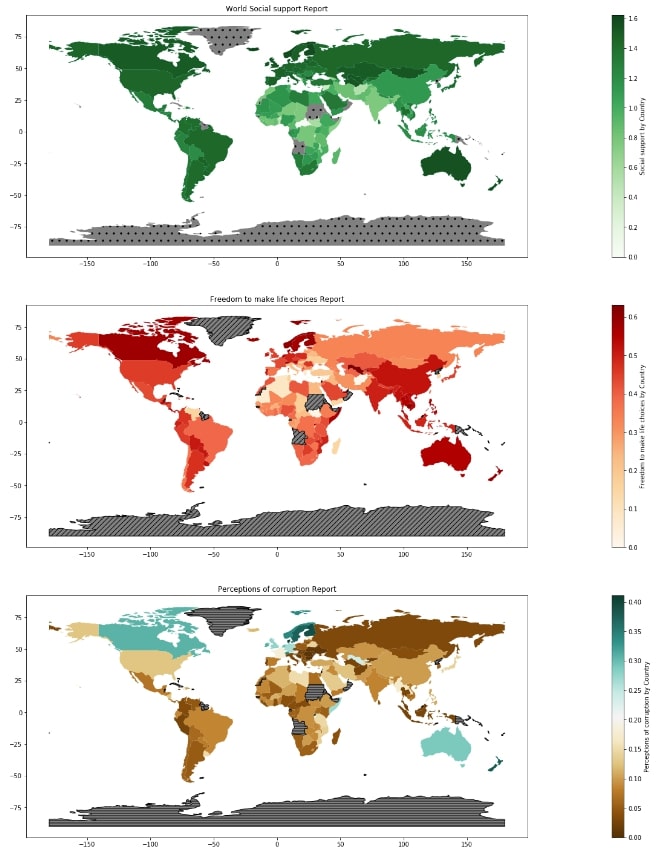
It'll happen many times that we won't have data for all observations and we might want to highlight those observations for which we do not have values with different representations. We can use a parameter called missing_kwds passing it dictionary of a parameter on handling plotting of missing observation. Please make a note that this future is available from geopandas version 0.7 onwards only.
plt.figure(figsize=(50,25))
ax1 = plt.subplot(311)
world_happiness_final.plot("Social support",
legend=True,
legend_kwds={"label":"Social support by Country"},
cmap=plt.cm.Greens,
ax=ax1,
missing_kwds={
"color": "grey",
"hatch":"."
}
)
plt.title("World Social support Report");
ax2 = plt.subplot(312)
world_happiness_final.plot("Freedom to make life choices",
legend=True,
legend_kwds={"label":"Freedom to make life choices by Country"},
cmap=plt.cm.OrRd,
ax=ax2,
missing_kwds={
"color":"grey",
"edgecolor":"black",
"hatch":"///",
"label":"Missing Values"
}
)
plt.title("Freedom to make life choices Report");
ax3 = plt.subplot(313)
world_happiness_final.plot("Perceptions of corruption",
legend=True,
legend_kwds={"label":"Perceptions of corruption by Country"},
cmap=plt.cm.BrBG,
ax=ax3,
missing_kwds={
"color":"grey",
"edgecolor":"black",
"hatch":"---",
"label":"Missing Values"
}
)
plt.title("Perceptions of corruption Report");
4. Scatter Plots on Maps ¶
We'll now explain scatter plots on maps with few examples. We'll use starbucks store location data available from kaggle for plotting these graphs. It has information about each Starbucks store locations as well as their address, city, country, phone number, latitude and longitude data.
starbucks_locations = pd.read_csv("stracbucks_store_locations.csv")
starbucks_locations.head()
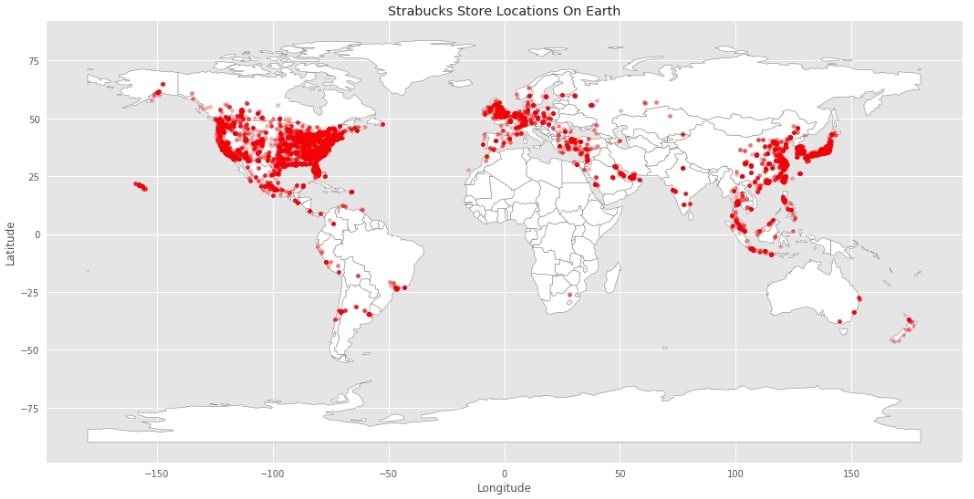
Below we are plotting a simple map plot first and then using a scatter plot available in matplotlib to plot all Starbucks locations on it. Please make a note that we have longitude and latitude data for each store available in the dataset which we are utilizing in scatter plot.
with plt.style.context(("seaborn", "ggplot")):
world.plot(figsize=(18,10),
color="white",
edgecolor = "grey");
plt.scatter(starbucks_locations.Longitude, starbucks_locations.Latitude, s=15, color="red", alpha=0.3)
plt.xlabel("Longitude")
plt.ylabel("Latitude")
plt.title("Strabucks Store Locations On Earth");
Below we are trying to get a count of Starbucks stores in each city of the world and then keeping only cities where more than 10 Starbucks are present per city. We are the first grouping data by the city to get average longitude and latitude. Then we generate another dataframe that has store count per city. We then combine dataframe with latitude & longitude with counts data. We only keep entries where more than 10 Starbucks is present.
citywise_geo_data = starbucks_locations.groupby("City").mean()[["Longitude","Latitude"]]
citywise_store_cnts = starbucks_locations.groupby("City").count()[["Store Number"]].rename(columns={"Store Number":"Count"})
citywise_store_cnts = citywise_geo_data.join(citywise_store_cnts).sort_values(by=["Count"], ascending=False)
citywise_store_cnts = citywise_store_cnts[citywise_store_cnts["Count"]>10]
citywise_store_cnts.head()
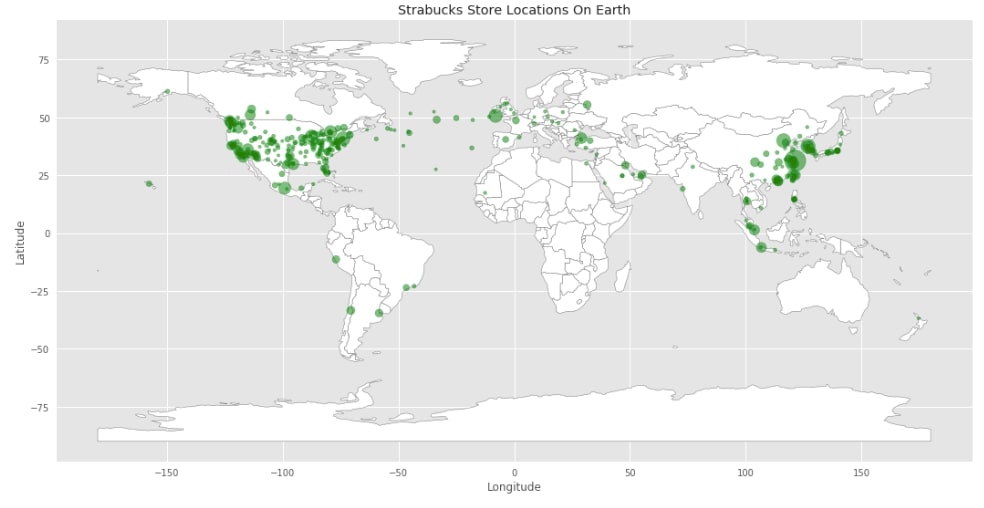
Below we are plotting world map by default first and then overlapping scatter plot of cities where more than 10 Starbucks are present. We are using a number of Starbucks as size to represent Starbucks counts per city.
with plt.style.context(("seaborn", "ggplot")):
world.plot(figsize=(18,10),
color="white",
edgecolor = "grey");
plt.scatter(citywise_store_cnts.Longitude, citywise_store_cnts.Latitude, s=citywise_store_cnts.Count, color="green", alpha=0.5)
plt.xlabel("Longitude")
plt.ylabel("Latitude")
plt.title("Strabucks Store Locations On Earth");
We'll be publishing another tutorial on working with geopandas where we'll be explaining how to use geopandas with other data file types like shape files and geojson files.
References ¶
- Maps using Folium
- Interactive Maps
- Maps using bqplot
- Maps using Cartopy
- Choropleth Maps and Scatter Maps using Cufflinks
- Plotting Maps using Bokeh
- ipyleaflet - Interactive Maps in Python based on leaflet.js
- Interactive Choropleth Maps using Bqplot
- Choropleth Maps using ipyleaflet
- Connection Maps using Plotly and Geopandas
 Sunny Solanki
Sunny Solanki
Sunny Solanki
Intro: Software Developer | Youtuber | Bonsai Enthusiast
About: Sunny Solanki holds a bachelor's degree in Information Technology (2006-2010) from L.D. College of Engineering. Post completion of his graduation, he has 8.5+ years of experience (2011-2019) in the IT Industry (TCS). His IT experience involves working on Python & Java Projects with US/Canada banking clients. Since 2020, he’s primarily concentrating on growing CoderzColumn.
His main areas of interest are AI, Machine Learning, Data Visualization, and Concurrent Programming. He has good hands-on with Python and its ecosystem libraries.
Apart from his tech life, he prefers reading biographies and autobiographies. And yes, he spends his leisure time taking care of his plants and a few pre-Bonsai trees.
Contact: sunny.2309@yahoo.in



![YouTube Subscribe]() Comfortable Learning through Video Tutorials?
Comfortable Learning through Video Tutorials?
If you are more comfortable learning through video tutorials then we would recommend that you subscribe to our YouTube channel.
![Need Help]() Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
 Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?When going through coding examples, it's quite common to have doubts and errors.
If you have doubts about some code examples or are stuck somewhere when trying our code, send us an email at coderzcolumn07@gmail.com. We'll help you or point you in the direction where you can find a solution to your problem.
You can even send us a mail if you are trying something new and need guidance regarding coding. We'll try to respond as soon as possible.
![Share Views]() Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?
 Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?If you want to
- provide some suggestions on topic
- share your views
- include some details in tutorial
- suggest some new topics on which we should create tutorials/blogs
 maps, choropleth-maps, geopandas
maps, choropleth-maps, geopandas