Python Tutorials
Python is one of the most widely used programming languages today. This section is a large archive of tutorials, based on Python programming language. We cover the basic and advanced technical aspects through coding examples and snippets.
- Parallel Computing
- Concurrent Programming
- Speed Up Python Code
- Working with Emails
- Profiling
- Jupyter Notebook Helpers
- Web Scraping
- File & Directory Access
- Work With Archives
- Generic OS Services
- Python Runtime Services
- Text Processing Services
- File Formats
- Networking & Interprocess Communication
- Image Processing
For an in-depth understanding of the above concepts, check out the sections below.
 Sunny Solanki
Sunny Solanki



![ipywidgets - An In-depth Guide to Interactive Widgets in Jupyter Notebook [Python]](/static/tutorials/python/An%20In-depth%20Guide%20about%20Interactive%20Widgets%20in%20Jupyter%20Notebook%20using%20ipywidgets%20%5BPython%5D.jpg)



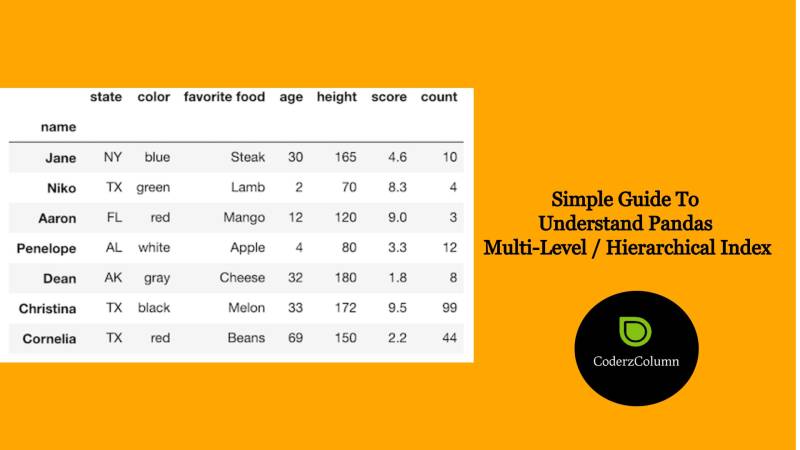

%20_%20Multi-Dimensional%20Labelled%20Arrays.jpg)
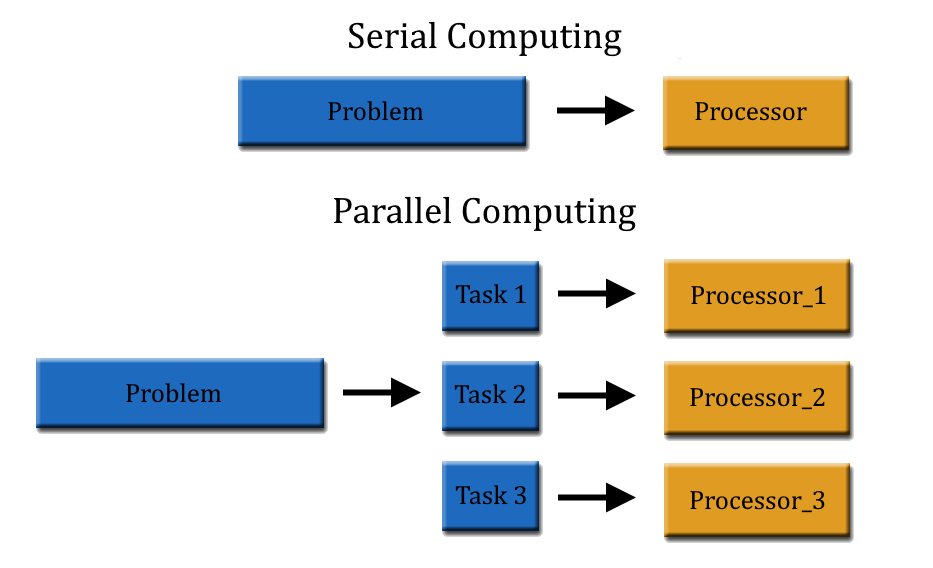






.jpg)