interpret-ml - Explain Machine Learning Models And Their Predictions¶
The interpretation of machine learning models and their predictions has become quite important lately. The interpretation of models to better understand which features actually contributed to a particular prediction gives confidence to the model creator. It also helps to better explain why the model is behaving in a particular way. The python has many libraries (like lime, shap, eli5, yellowbrick, etc) which provide different ways to explain model predictions. We have already created tutorials on these libraries (See References section). As a part of this tutorial, we'll be explaining the library named interpret-ml which is designed by the Microsoft research team. The interpret-ml is an open-source library and is built on a bunch of other libraries (plotly, dash, shap, lime, treeinterpreter, sklearn, joblib, jupyter, salib, skope-rules, gevent, and pytest). The interpret-ml creates an interactive dashboard of visualizations using plotly and dash which can explain data, model performance, and predictions from different perspectives. It has divided different explainer classes used for different purposes in different modules. Please make a note that interpret-ml is still in alpha release and constantly getting developed as of the date when this tutorial is created.
We'll be explaining the usage of three main modules as a part of this tutorial.
- data - It has classes that can help us explain our dataset from a different perspective.
- glassbox - It has classes that can help us explain our model predictions.
- perf - It has classes that can help us visualize metrics like proc curve, precision-recall curve, etc.
Data Explainers¶
Below we have given a list of classes available in the data module of interpret-ml which we'll explain.
- data
- ClassHistogram - It creates interactive visualization which shows the distribution of classes in classification problems. It also creates a histogram for individual features based on the individual class of data.
- Marginal - It creates a marginal plot for provided data.
Model Explainers¶
Below we have listed down classes available in modules glassbox, blackbox and greybox. We'll be primarily explaining only explainers available from glassbox module. We'll be covering blackbox and greybox in a separate tutorial.
- glassbox
- LinearRegression - It helps us explain the linear regression model's prediction on our data.
- LogisticRegression - It helps us explain the logistic regression model's prediction on our data.
- ClassificationTree - It helps us explain predictions generated by the decision tree-based model on classification dataset.
- RegressionTree - It helps us explain predictions generated by the decision tree-based model on the regression dataset.
- ExplainableBoostingClassifier - It helps us explain predictions generated by boosting-based model on classification dataset.
- ExplainableBoostingRegressor - It helps us explain predictions generated by a boosting-based model on the regression dataset.
blackbox
- LimeTabular
- ShapKernel
- PartialDependence
- MorrisSensitivity
greybox
- TreeInterpreter
- ShapTree
Performance Explainers¶
The perf module provides classes that will help us explain metrics like roc curve, precision-recall curve, etc.
- perf
- PR - It helps us generate precision recall curve.
- ROC - - It helps us generate ROC curve.
- RegressionPerf - It helps us explain regression metrics like RMSE and R2 score.
Steps Commonly Used to Generate Explanation¶
We'll be commonly following below mentioned steps when generating explanations explaining data, model prediction, and model performance.
- Create an
explainerinstance of one of the above classes. - Call
explain_*methods on explainer instance which will generateexplanationinstance. - Call
interpret_ml.show()passing it explanation object to create visualization. The show method accepts a single explanation object or a list of them.
We'll be using one classification dataset and one regression data to explain classes available from data, glassbox, and perf modules.
We'll start by loading useful libraries.
import interpret
from interpret import glassbox, blackbox, greybox
import pandas as pd
import numpy as np
import sklearn
Classification Problem¶
As a part of this section, we'll explain the usage of explainers available from data, glassbox, and perf to explain the classification dataset. We'll be using the breast cancer dataset available from scikit-learn as a part of this section. The target variable is whether the tumor is malignant or benign based on a list of features.
Below we have loaded the breast cancer dataset as pandas dataframe as well and printed the first few rows of data. We have even printed a description of features that are available in the dataset.
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
for line in breast_cancer.DESCR.split("\n")[5:32]:
print(line)
breast_cancer_df = pd.DataFrame(data=breast_cancer.data, columns = breast_cancer.feature_names)
breast_cancer_df["TumorType"] = [breast_cancer.target_names[cat] for cat in breast_cancer.target]
breast_cancer_df.head()
Explain Data¶
As a part of explain data section, we'll be explaining the usage of explainers available from the data module to explain the breast cancer dataset.
ClassHistogram¶
We can create an instance of this class by passing a list of feature names to the feature_names parameter. It'll create an explainer instance.
from interpret import data
class_hist = data.ClassHistogram(feature_names=breast_cancer.feature_names)
class_hist
Below we have called the explain_data() method on the explainer instance created in the previous step. We have passed actual data and target to the method. It'll create an explanation object.
hist_explanation = class_hist.explain_data(breast_cancer.data, breast_cancer.target)
hist_explanation
Below we have called the show() method passing it explanation instance created in the previous step. It'll generate an interactive dashboard with a dropdown which will let us see various features histogram per class of data.
from interpret import show
show(hist_explanation)
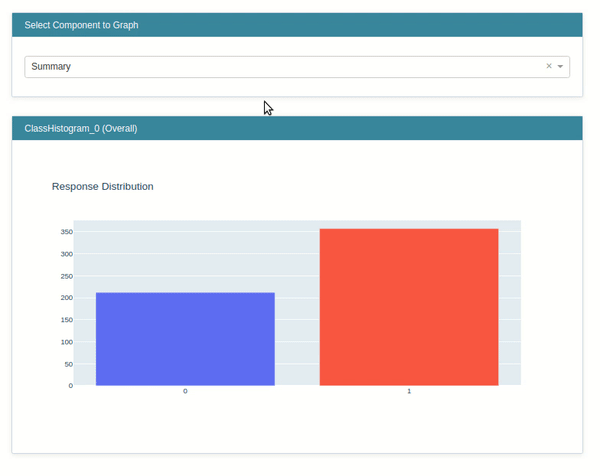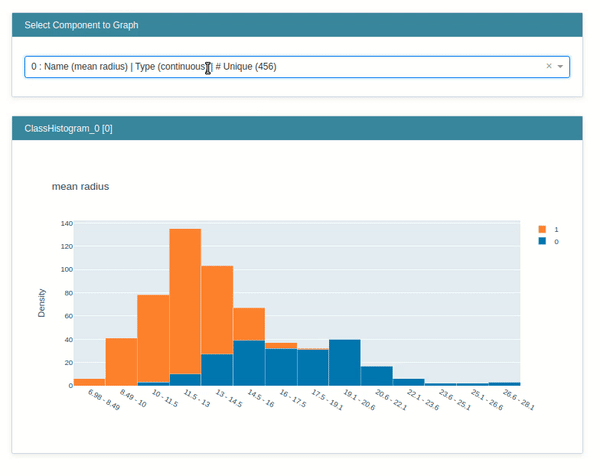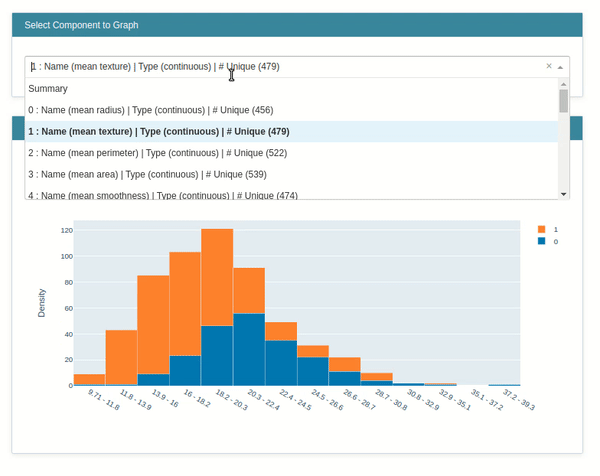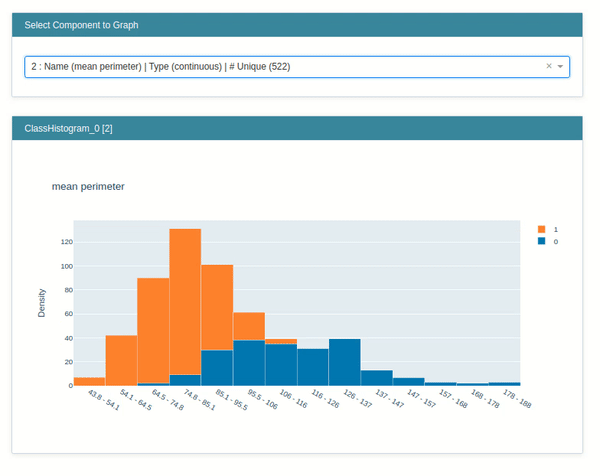
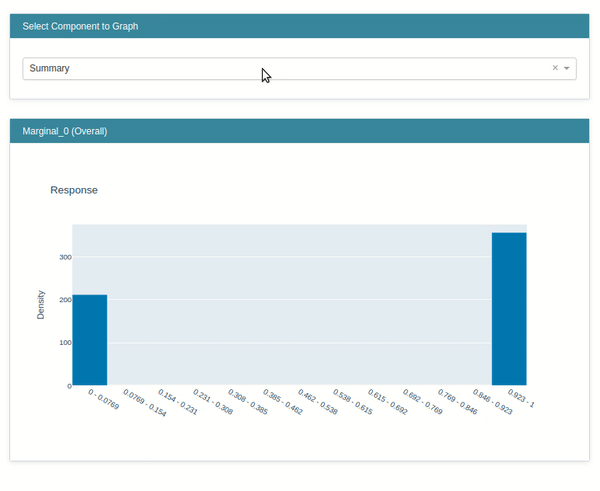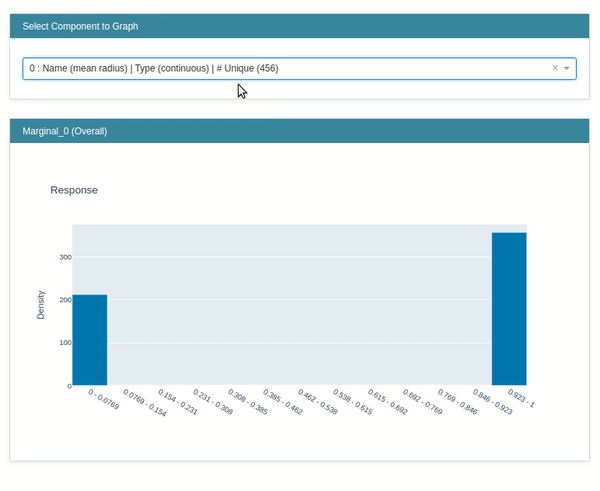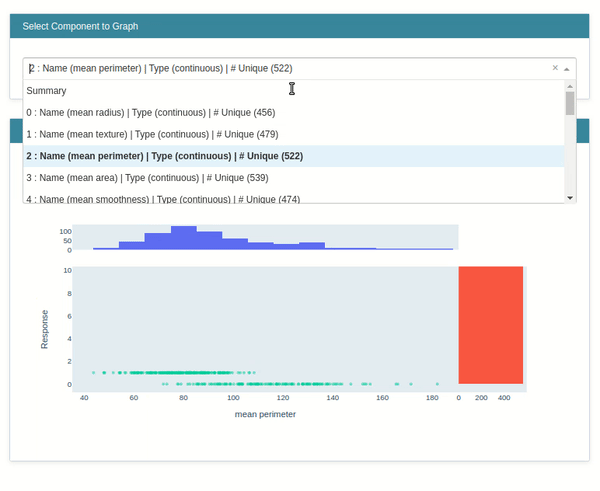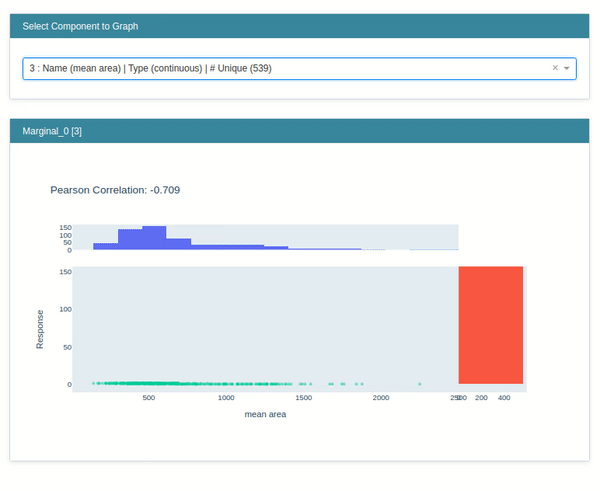
Marginal¶
This class lets us create a marginal chart. We have created an instance of the Marginal class by giving it a list of feature names. It'll create an explainer instance.
marginal = data.Marginal(feature_names=breast_cancer.feature_names)
marginal
Below we have called the explain_data() method on the explainer instance from the previous step by giving data and target to the method. It'll generate an explanation instance which we'll display using the show() method.
marginal_explanation = marginal.explain_data(breast_cancer.data, breast_cancer.target)
marginal_explanation
show(marginal_explanation)
Explain Model Predictions (Global and Local Explanations)¶
As a part of this section, we'll explain three different explainer classes available from the glassbox module. We'll first divide our dataset into train (80%) and test (20%) sets using train_test_split() method of sklearn.
from sklearn.model_selection import train_test_split
X_breast_cancer, Y_breast_cancer = breast_cancer.data, breast_cancer.target
print("Dataset Size : ", X_breast_cancer.shape, Y_breast_cancer.shape)
X_train_breast_cancer, X_test_breast_cancer, Y_train_breast_cancer, Y_test_breast_cancer = train_test_split(X_breast_cancer, Y_breast_cancer,
train_size=0.80,
stratify=Y_breast_cancer,
random_state=123)
print("Train/Test Sizes : ", X_train_breast_cancer.shape, X_test_breast_cancer.shape, Y_train_breast_cancer.shape, Y_test_breast_cancer.shape)
1. Logistic Regression¶
The first explainer that we'll explain uses sklearn's logistic regression for classifying samples. We have below created an instance of class glassbox.LogisticRegression by giving it a list of feature names of data. This is our explainer instance.
from interpret import glassbox
glassbox_lr = glassbox.LogisticRegression(feature_names=breast_cancer.feature_names)
glassbox_lr
The logistic regression explainer instance has a method named fit() and score() which lets us fit train data to model and calculate model accuracy on the test dataset.
glassbox_lr.fit(X_train_breast_cancer, Y_train_breast_cancer)
print("Train Accuracy : %.2f"%glassbox_lr.score(X_train_breast_cancer, Y_train_breast_cancer))
print("Test Accuracy : %.2f"%glassbox_lr.score(X_test_breast_cancer, Y_test_breast_cancer))
The logistic regression explainer instance has two important methods for explaining model predictions.
explain_global()explain_local()
explain_global()¶
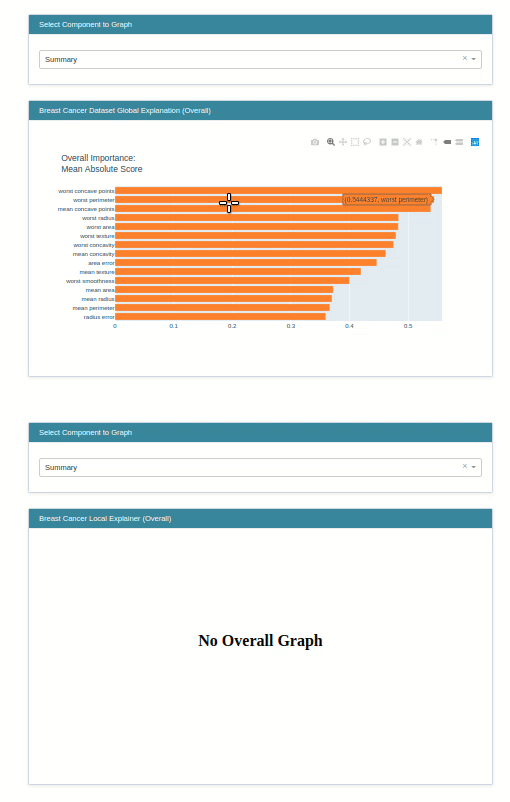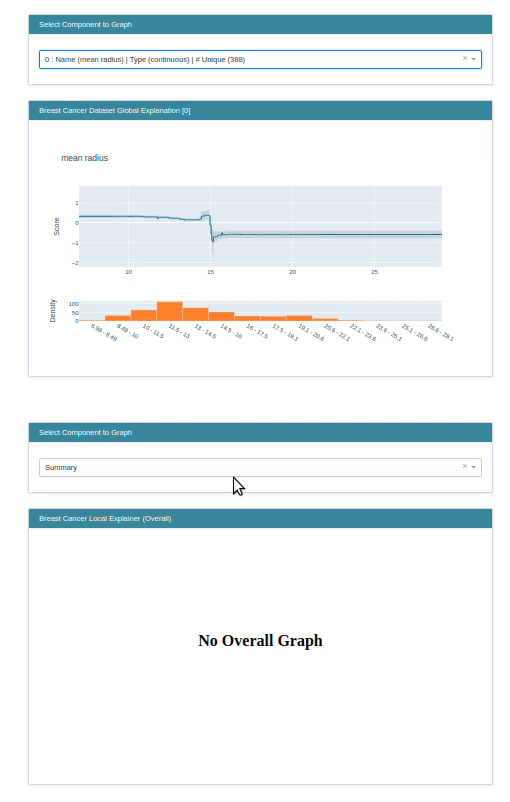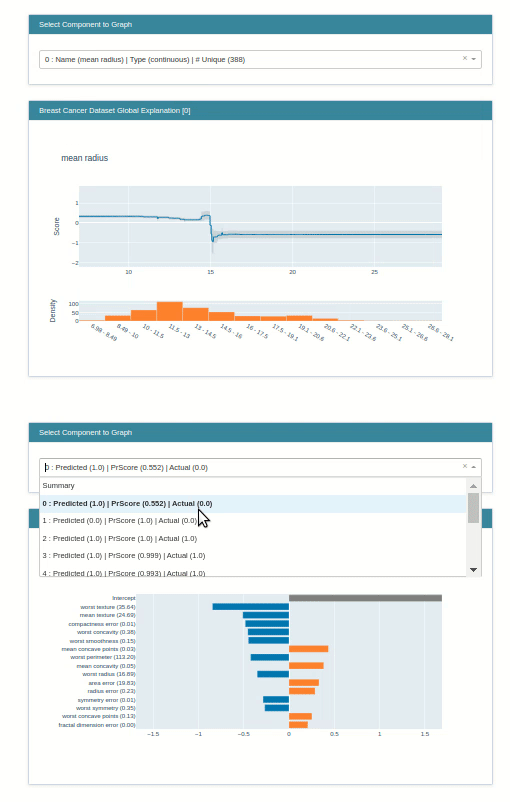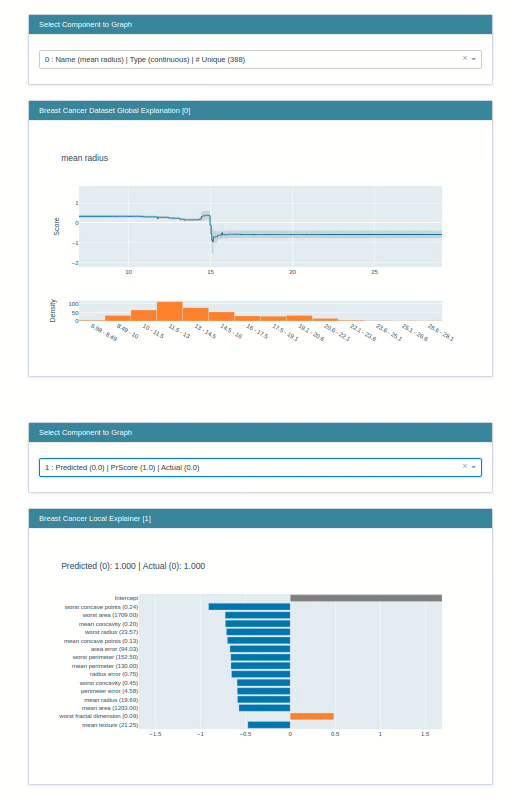
The explain global method generates global weights of the model which are generally available as coef_ and intercept_ attribute of the model.
lr_global_explanation = glassbox_lr.explain_global(name="Breast Cancer Dataset Global Explanation")
lr_global_explanation
show(lr_global_explanation)
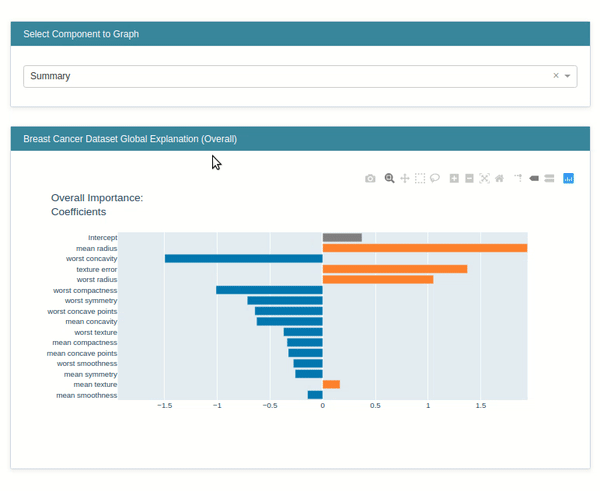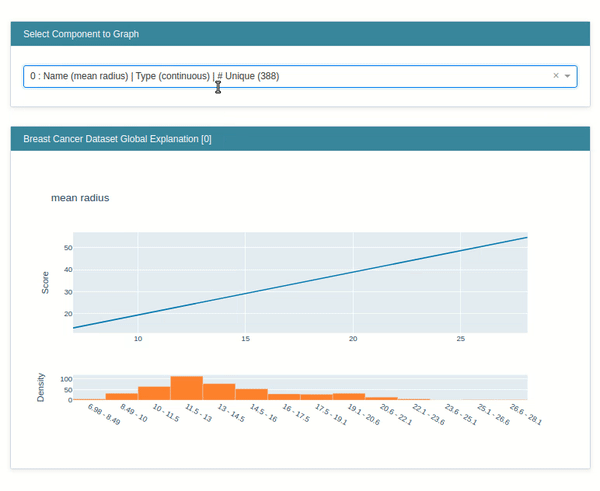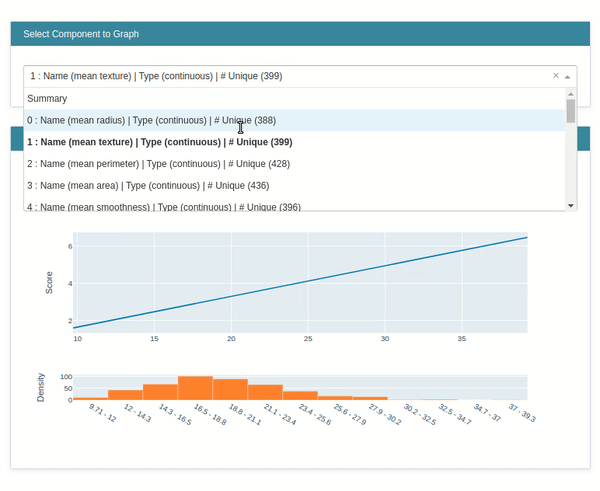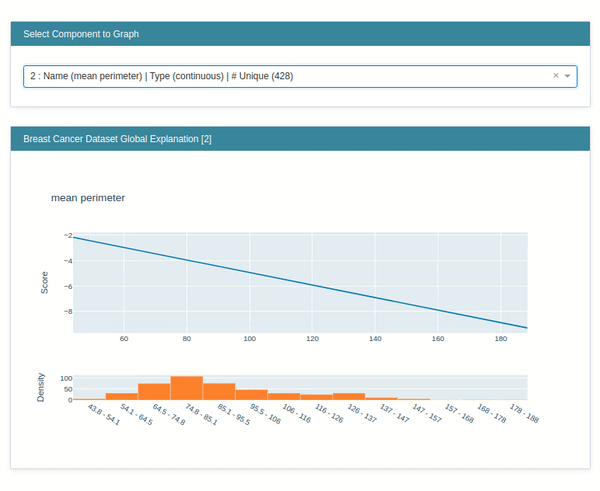
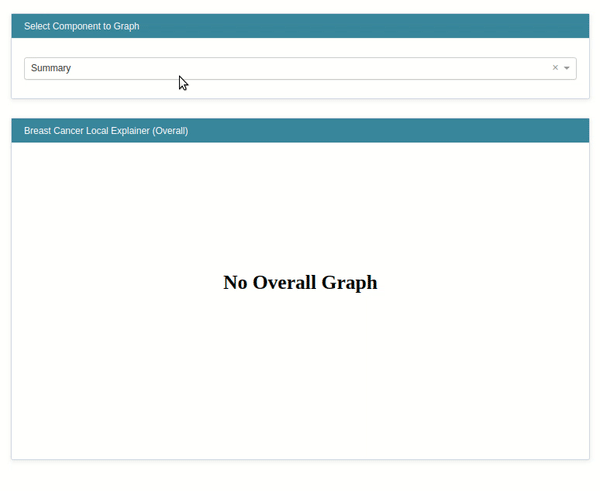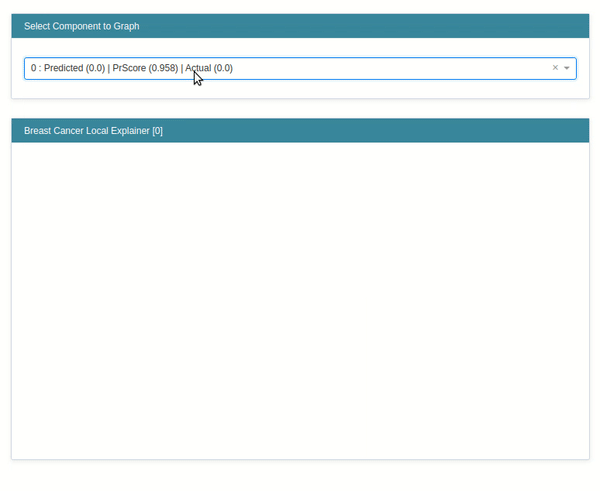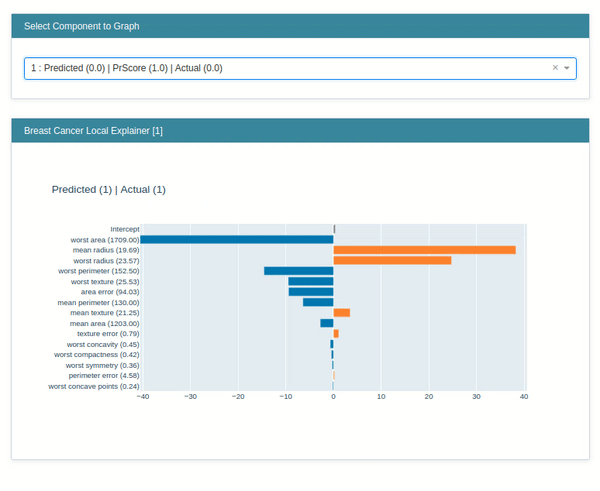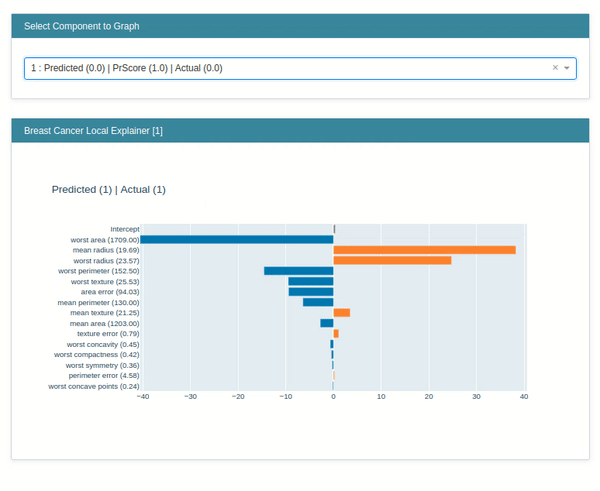
explain_local()¶
The explain_local() method lets us explain model prediction on an individual sample by showing us a bar chart of how much individual features contributed to this prediction. It accepts a list of samples and their predictions as input for generating an explanation object. Below we have generated an explanation instance on the breast cancer test dataset.
lr_local_explanation = glassbox_lr.explain_local(X_test_breast_cancer, Y_test_breast_cancer,
name="Breast Cancer Local Explainer")
lr_local_explanation
show(lr_local_explanation)
2. Decision Tree¶
The second explainer that we'll explain as a part of this section is ClassificationTree which is a decision tree-based explainer. Below we have created an explainer instance, fitted train data, evaluated the accuracy of the model, and then generated explanation instances for global and local explanations.
We have then plotted both explanation instances using the show() method.
from interpret import glassbox
glassbox_classif_tree = glassbox.ClassificationTree(feature_names=breast_cancer.feature_names)
glassbox_classif_tree
glassbox_classif_tree.fit(X_train_breast_cancer, Y_train_breast_cancer)
print("Train Accuracy : %.2f"%glassbox_classif_tree.score(X_train_breast_cancer, Y_train_breast_cancer))
print("Test Accuracy : %.2f"%glassbox_classif_tree.score(X_test_breast_cancer, Y_test_breast_cancer))
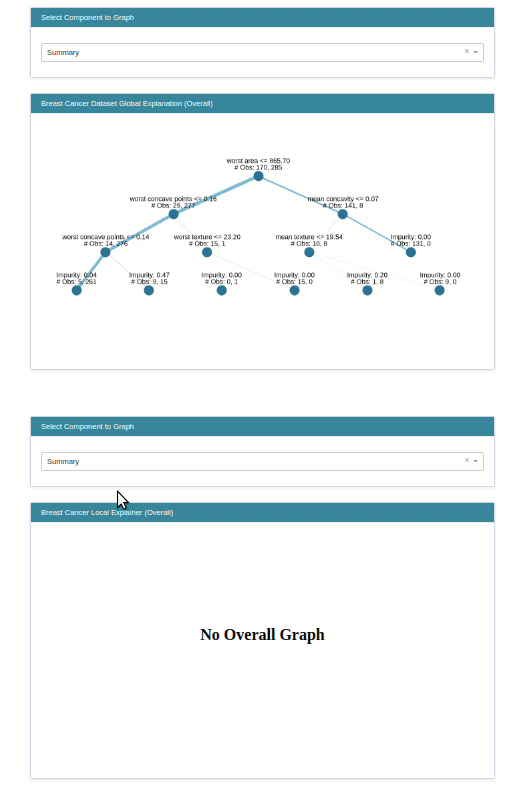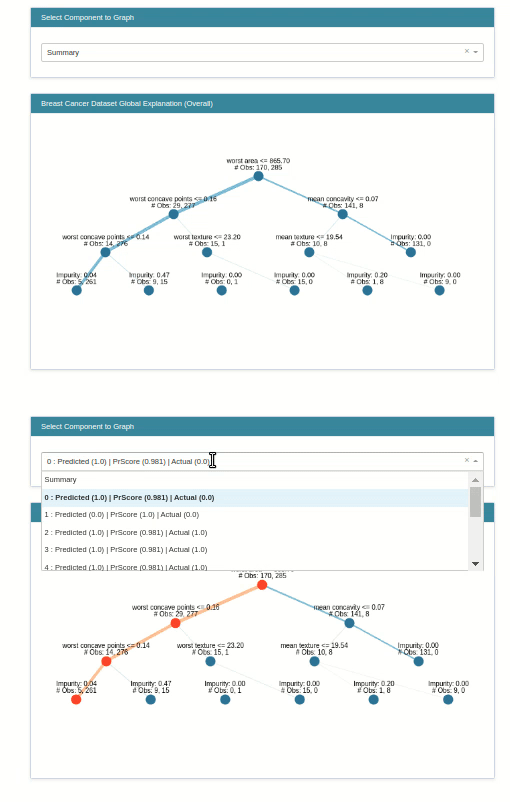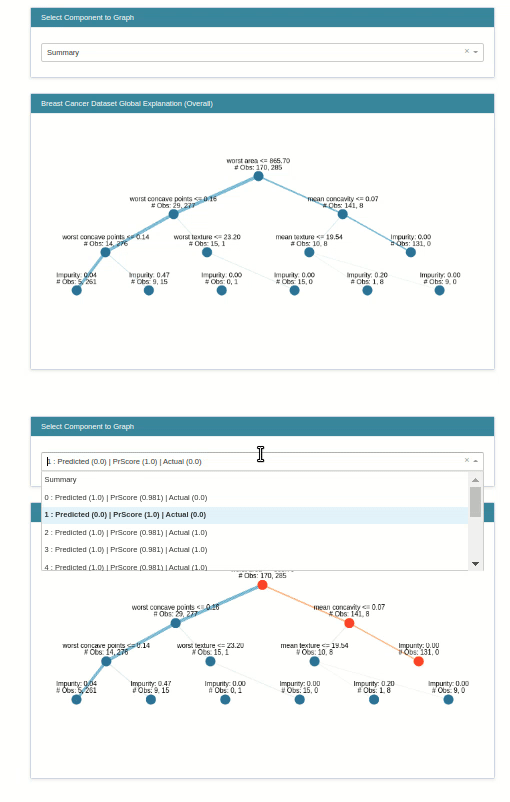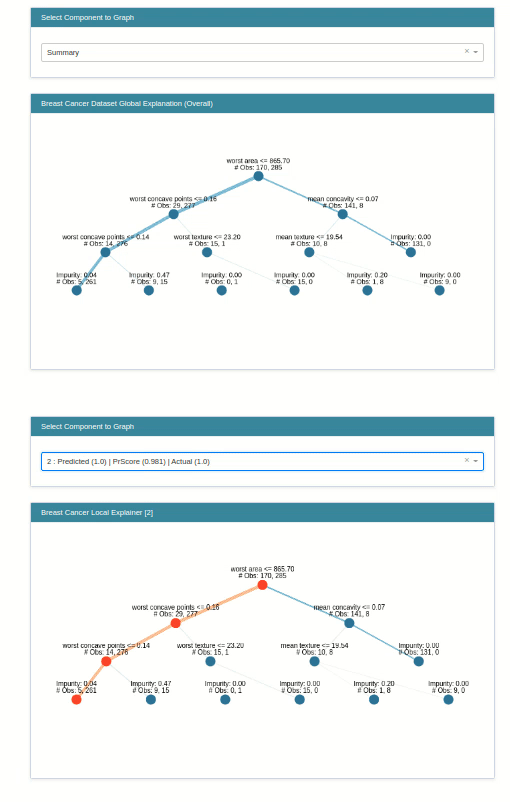
classif_tree_global_explanation = glassbox_classif_tree.explain_global(name="Breast Cancer Dataset Global Explanation")
classif_tree_local_explanation = glassbox_classif_tree.explain_local(X_test_breast_cancer, Y_test_breast_cancer,
name="Breast Cancer Local Explainer")
show(classif_tree_global_explanation)
show(classif_tree_local_explanation)
3. Boosting Machines¶
The third explanation instance that we'll explain as a part of this section is ExplainableBoostingClassifier. It’s based on gradient boosting machines. We have first created an explainer instance, fitted train data, calculated test accuracy, and then generated local/global explanations.
from interpret import glassbox
glassbox_boosting = glassbox.ExplainableBoostingClassifier(feature_names=breast_cancer.feature_names)
glassbox_boosting
glassbox_boosting.fit(X_train_breast_cancer, Y_train_breast_cancer)
print("Train Accuracy : %.2f"%glassbox_boosting.score(X_train_breast_cancer, Y_train_breast_cancer))
print("Test Accuracy : %.2f"%glassbox_boosting.score(X_test_breast_cancer, Y_test_breast_cancer))
boosting_global_explanation = glassbox_boosting.explain_global(name="Breast Cancer Dataset Global Explanation")
boosting_local_explanation = glassbox_boosting.explain_local(X_test_breast_cancer, Y_test_breast_cancer,
name="Breast Cancer Local Explainer")
show(boosting_global_explanation)
show(boosting_local_explanation)
Explain Model Performance¶
As a part of this section, we'll be explaining how to generate the ROC curve and precision-recall curve for classification problems using classes available from the perf module of interpret-ml.
from interpret import perf
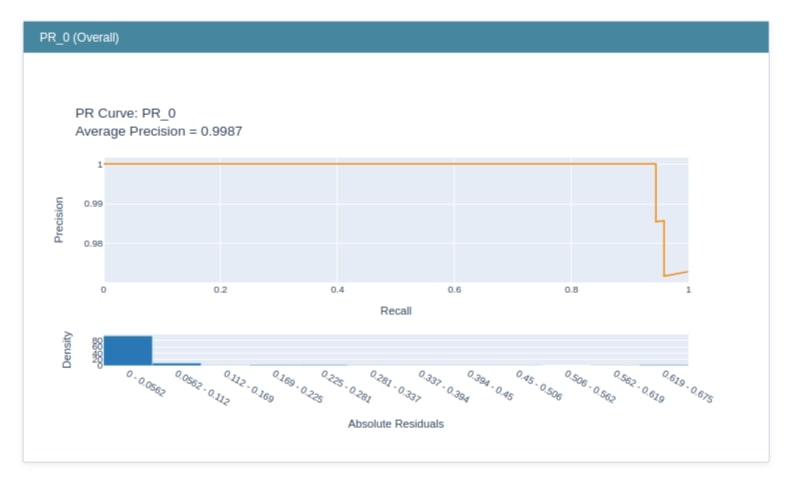
PR¶
Below we have created an explainer instance using the PR class of the perf module. It accepts prediction function and feature names. This is our explainer instance.
precicion_recall = perf.PR(glassbox_lr.predict_proba, feature_names=breast_cancer.feature_names)
precicion_recall
explain_perf()¶
The explainer instance created in the previous step has a method named explain_perf() which accepts data and target variables to generate an explanation instance which has precision-recall curve on that data.
pr_explanation = precicion_recall.explain_perf(X_test_breast_cancer, Y_test_breast_cancer)
pr_explanation
from interpret import show
show(pr_explanation)
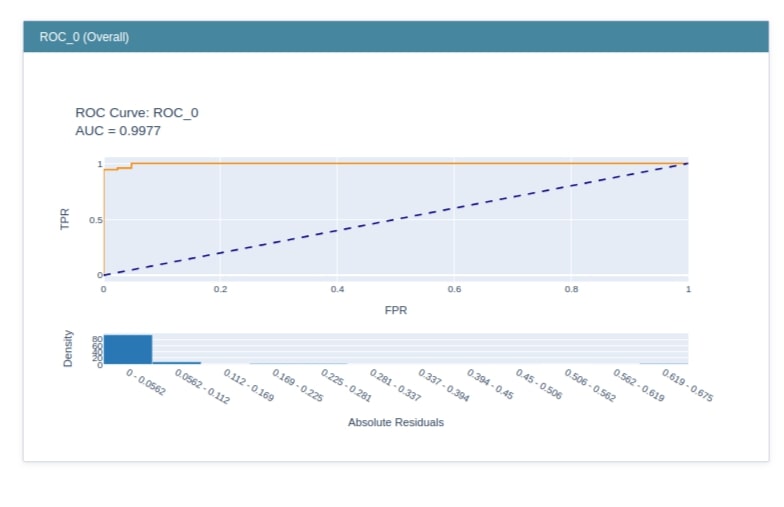
ROC¶
The ROC class will be used for creating an ROC AUC curve for our model. It accepts prediction function and feature names for creating explainer instance.
The explainer instance has a method named explain_perf() which accepts data and targets to generate an explanation instance which will have an ROC curve for that data. We'll then call the show() method passing it this explanation instance to generate the ROC curve on given data.
roc = perf.ROC(glassbox_lr.predict_proba, feature_names=breast_cancer.feature_names)
roc
roc_explanation = roc.explain_perf(X_test_breast_cancer, Y_test_breast_cancer)
roc_explanation
show(roc_explanation)
Dashboard With All Visualizations¶
The show() method which we have used till now can also accept a list of explanations and generate a dashboard of all visualizations.
Please make a note that the dashboard which you see below will be the default dashboard when you pass a list of explanations. If you don't pass explanations for any section like data or local or global then that section will be empty in the dashboard
show([hist_explanation, marginal_explanation, lr_global_explanation, lr_local_explanation, roc_explanation, pr_explanation])
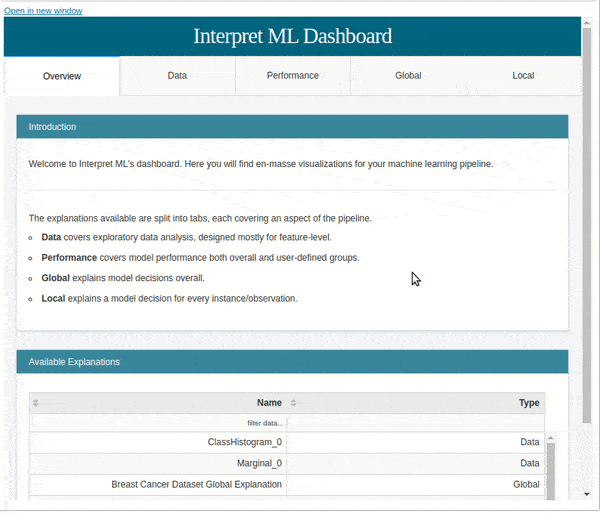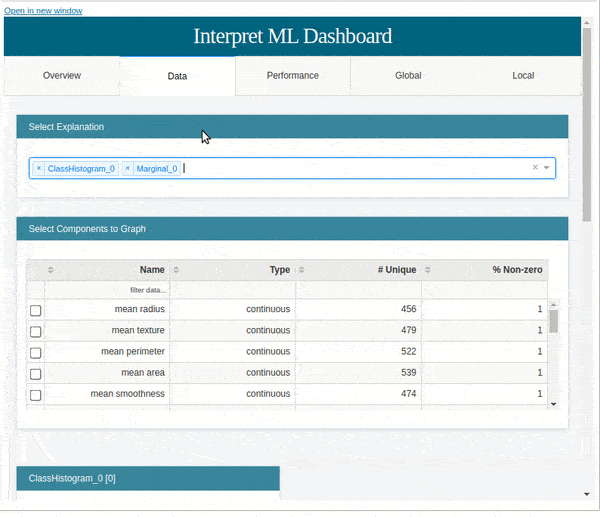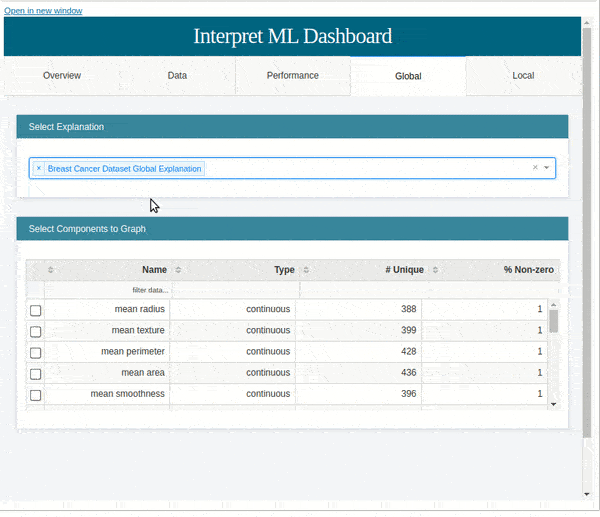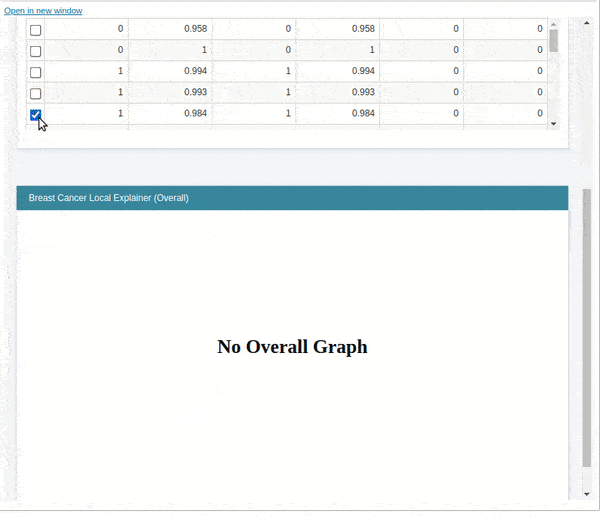
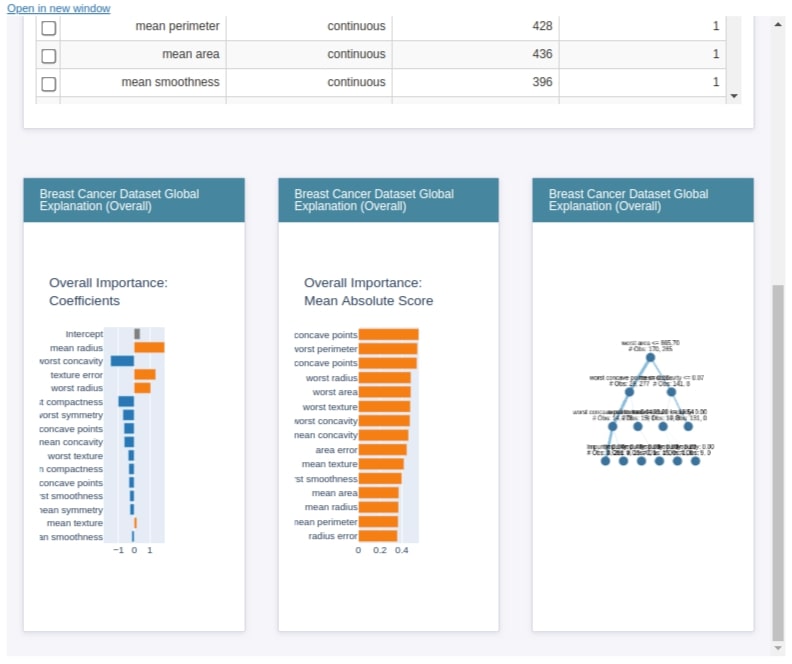
We can even pass explanations generated across different models to compare performance across models as explained below.
show([lr_global_explanation, classif_tree_global_explanation, boosting_global_explanation])
Regression Problem¶
As a part of this section, we'll be explaining modules data, glassbox, and perf for a regression problem. We'll be using the Boston housing dataset available from sklearn for this purpose. Below we have loaded the Boston housing dataset and printed feature descriptions. We have also loaded the dataset as a pandas dataframe to show the first few samples.
from sklearn.datasets import load_boston
boston = load_boston()
for line in boston.DESCR.split("\n")[5:30]:
print(line)
boston_df = pd.DataFrame(data=boston.data, columns = boston.feature_names)
boston_df["Price($)"] = boston.target
boston_df.head()
Explain Data¶
Below we have generated a marginal plot for the Boston dataset using the Marginal class by giving it feature names as a list.
from interpret import data
marginal = data.Marginal(feature_names=boston.feature_names)
marginal_explanation = marginal.explain_data(boston.data, boston.target)
show(marginal_explanation)
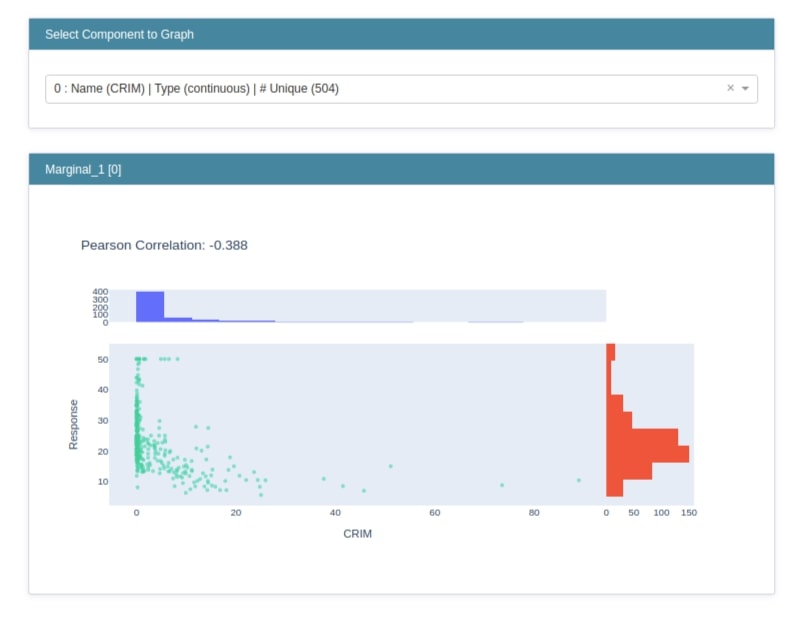
Explain Model Predictions (Global and Local Explanations)¶
As a part of this section, we'll explain local and global explanations using three different models available with the glassbox module of interpret-ml.
- LinearRegression
- RegressionTree
- ExplainableBoostingRegressor
We have first divided the dataset into the train (80%) and test (20%) sets.
from sklearn.model_selection import train_test_split
from interpret import glassbox
X_boston, Y_boston = boston.data, boston.target
print("Dataset Size : ", X_boston.shape, Y_boston.shape)
X_train_boston, X_test_boston, Y_train_boston, Y_test_boston = train_test_split(X_boston, Y_boston,
train_size=0.80,
random_state=123)
print("Train/Test Sizes : ", X_train_boston.shape, X_test_boston.shape, Y_train_boston.shape, Y_test_boston.shape)
1. Linear Regression¶
The first model that we'll use for explaining global and local explanations is Linear Regression. The Linear class of glassbox uses the LinearRegression model available from scikit-learn.
We have first created an instance of LinearRegression which is our explainer object. We have then fitted train data to it and printed the R2 score on test data. We have then created explanation objects for local and global explanations.
We have then created visualizations using the show() method.
glassbox_lr = glassbox.LinearRegression(feature_names=boston.feature_names)
print(type(glassbox_lr))
glassbox_lr.fit(X_train_boston, Y_train_boston)
print("\nTrain R2 Score : %.2f"%glassbox_lr.score(X_train_boston, Y_train_boston))
print("Test R2 Score : %.2f"%glassbox_lr.score(X_test_boston, Y_test_boston))
lr_global_explanation = glassbox_lr.explain_global(name="Boston Housing Dataset Global Explanation")
lr_local_explanation = glassbox_lr.explain_local(X_test_boston, Y_test_boston,
name="Boston Housing Dataset Global Explanation")
show(lr_global_explanation)
show(lr_local_explanation)
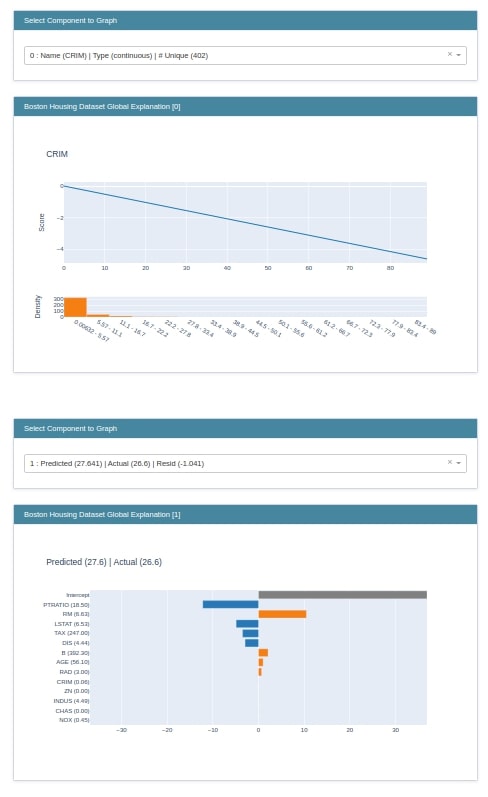
2. Decision Tree¶
The second estimator that we'll explain is RegressionTree. It’s a decision tree-based model. We have created an instance of RegressionTree, fitted train data to it, and evaluated the R2 score on test data. We have then created local and global explanations using explainer object. At last, we are displaying both explanations using the show() method.
glassbox_reg_tree = glassbox.RegressionTree(feature_names=boston.feature_names)
print(type(glassbox_reg_tree))
glassbox_reg_tree.fit(X_train_boston, Y_train_boston)
print("\nTrain R2 Score : %.2f"%glassbox_reg_tree.score(X_train_boston, Y_train_boston))
print("Test R2 Score : %.2f"%glassbox_reg_tree.score(X_test_boston, Y_test_boston))
reg_tree_global_explanation = glassbox_reg_tree.explain_global(name="Boston Housing Dataset Global Explanation")
reg_tree_local_explanation = glassbox_reg_tree.explain_local(X_test_boston, Y_test_boston,
name="Boston Housing Dataset Global Explanation")
show(reg_tree_global_explanation)
show(reg_tree_local_explanation)

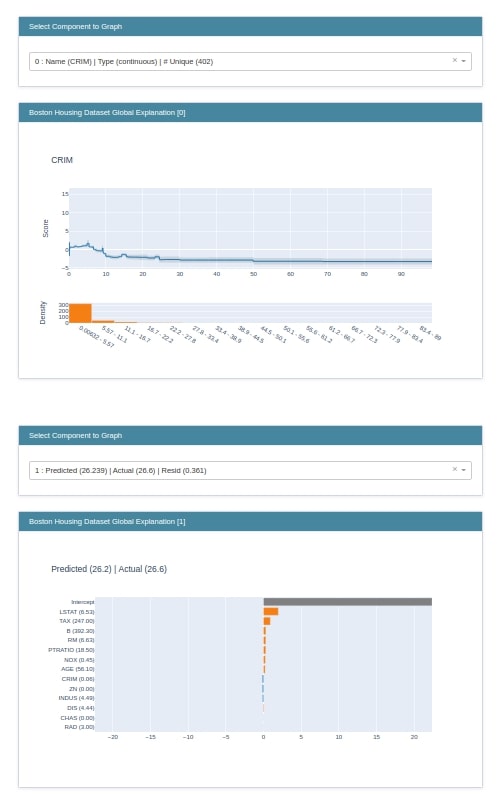
3. Boosting Machines¶
The third instance that we'll explain is ExplainableBoostingRegressor which is based on gradient boosting machines. We'll follow the same process as previous examples to create local and global explanations for the Boston dataset.
glassbox_boosting = glassbox.ExplainableBoostingRegressor(feature_names=boston.feature_names)
print(type(glassbox_boosting))
glassbox_boosting.fit(X_train_boston, Y_train_boston)
print("\nTrain R2 Score : %.2f"%glassbox_boosting.score(X_train_boston, Y_train_boston))
print("Test R2 Score : %.2f"%glassbox_boosting.score(X_test_boston, Y_test_boston))
boosting_global_explanation = glassbox_boosting.explain_global(name="Boston Housing Dataset Global Explanation")
boosting_local_explanation = glassbox_boosting.explain_local(X_test_boston, Y_test_boston,
name="Boston Housing Dataset Global Explanation")
show(boosting_global_explanation)
show(boosting_local_explanation)
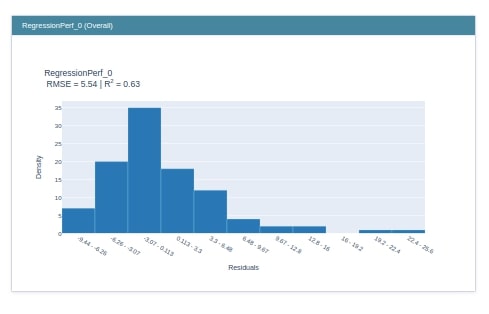
Explain Model Performance¶
As a part of this section, we'll explain performance metrics like RMSE and R2 Score calculations for samples of test data.
RegressionPerf¶
The RegressionPerf class is responsible for generating visualizations related to regression problems. Below we have generated an instance of RegressionPerf by giving it prediction function and features names as input. This is our explainer instance. We have then called the explain_perf() method on it to generate regression performance metrics explanation. At last, we have displayed an explanation using the show() method.
from interpret import perf
regression_perf = perf.RegressionPerf(glassbox_lr.predict, feature_names=boston.feature_names)
regression_explanation = regression_perf.explain_perf(X_test_boston, Y_test_boston)
show(regression_explanation)
This ends our small tutorial explaining data, glassbox, and perf modules of the interpret-ml library. Please feel free to let us know your views in the comments section.
References¶
- How to use eli5 to understand sklearn models, their performance, and their predictions?
- How to use lime to understand sklearn model's predictions?
- SHAP - Explain Machine Learning Model Predictions using Game-Theoretic Approach
- Treeinterpreter - Interpreting Tree-based Model's Prediction of Individual Sample
- Yellowbrick - Visualize Sklearn Classification & Regression Metrics in Python
- Scikit-Plot - Visualizing Machine Learning Algorithm Results & Performance
- interpret-text - Interpret NLP Models and Their Predictions
- dice-ml - Diverse Counterfactual Explanations for ML Models
- Yellowbrick - Text Data Visualizations
 Sunny Solanki
Sunny Solanki
Sunny Solanki
Intro: Software Developer | Youtuber | Bonsai Enthusiast
About: Sunny Solanki holds a bachelor's degree in Information Technology (2006-2010) from L.D. College of Engineering. Post completion of his graduation, he has 8.5+ years of experience (2011-2019) in the IT Industry (TCS). His IT experience involves working on Python & Java Projects with US/Canada banking clients. Since 2020, he’s primarily concentrating on growing CoderzColumn.
His main areas of interest are AI, Machine Learning, Data Visualization, and Concurrent Programming. He has good hands-on with Python and its ecosystem libraries.
Apart from his tech life, he prefers reading biographies and autobiographies. And yes, he spends his leisure time taking care of his plants and a few pre-Bonsai trees.
Contact: sunny.2309@yahoo.in



![YouTube Subscribe]() Comfortable Learning through Video Tutorials?
Comfortable Learning through Video Tutorials?
If you are more comfortable learning through video tutorials then we would recommend that you subscribe to our YouTube channel.
![Need Help]() Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
 Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?When going through coding examples, it's quite common to have doubts and errors.
If you have doubts about some code examples or are stuck somewhere when trying our code, send us an email at coderzcolumn07@gmail.com. We'll help you or point you in the direction where you can find a solution to your problem.
You can even send us a mail if you are trying something new and need guidance regarding coding. We'll try to respond as soon as possible.
![Share Views]() Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?
 Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?If you want to
- provide some suggestions on topic
- share your views
- include some details in tutorial
- suggest some new topics on which we should create tutorials/blogs
 interpret-ml, interpret-predictions
interpret-ml, interpret-predictions