Keras: CNNs With Conv1D For Text Classification Tasks¶
Convolutional Neural Networks (CNNs or ConvNets) are class of neural networks that uses convolution operation on input data to detect patterns in data. CNN consists of one or more convolution layers and these layers have internal kernels which are convoluted over input data to detect patterns. These kernels are commonly referred to as network parameters. The parameters of CNNs are less compared to fully connected networks and hence are faster to train. CNNs are very commonly used for computer vision tasks like object detection, image segmentation, image classification, etc, and have been proven most effective for them. When working with images, generally CNN with 2D convolution layers is used. Though, the research has shown that CNNs are very good at many NLP tasks as well. CNN with 1d convolution can be used for NLP tasks like text classification, text generation, etc.
As a part of this tutorial, we have explained how to create CNNs with 1D convolution (Conv1D) using Python deep learning library Keras for text classification tasks. The text data is encoded using word embeddings approach before giving it to the convolution layer. We have explained different approaches to creating CNNs for solving the task. After training networks we evaluated their performance by calculating various ML metrics and also explained predictions made by them using LIME (Local Interpretable Model-Agnostic Explanations) algorithm.
Below, we have listed important sections of tutorial to give an overview of the material covered.
Important Sections Of Tutorial¶
- Prepare Data
- 1.1 Load Dataset
- 1.2 Tokenize Text Examples, Populate Vocabulary And Vectorize Data
- Approach 1: CNN with Single Conv1D Layer (Max Tokens=50, Embed Length=128, Conv Output Channels=32)
- Define Network
- Compile Network
- Train Network
- Evaluate Network Performance
- Explain Network Predictions using LIME Algorithm
- Approach 2: CNN with Multiple Conv1D Layers (Max Tokens=50, Embed Length=128, Conv Output Channels=32,32)
- Results Summary And Further Suggestions
Below, we have imported the necessary Python libraries and printed the versions of them that we have used in our tutorial.
import tensorflow
from tensorflow import keras
print("Keras Version : {}".format(keras.__version__))
import torchtext
print("Torchtext Version : {}".format(torchtext.__version__))
import matplotlib.pyplot as plt
%matplotlib inline
import gc
1. Prepare Data ¶
In this section, we have prepared data to be given to the neural network for our text classification task. We have used word embeddings approach to encode text data. We have implemented this approach in the below-mentioned three steps.
- Loop through each text example, tokenize them into a list of tokens (words) and create a vocabulary of all unique tokens. The vocabulary is a simple mapping from a token to its integer index. Each token is assigned a unique index starting from 0. The vocabulary has all tokens from the corpus.
- Tokenize each text example and retrieve indexes of tokens from the vocabulary.
- Map each token index to a real-valued vector (embeddings).
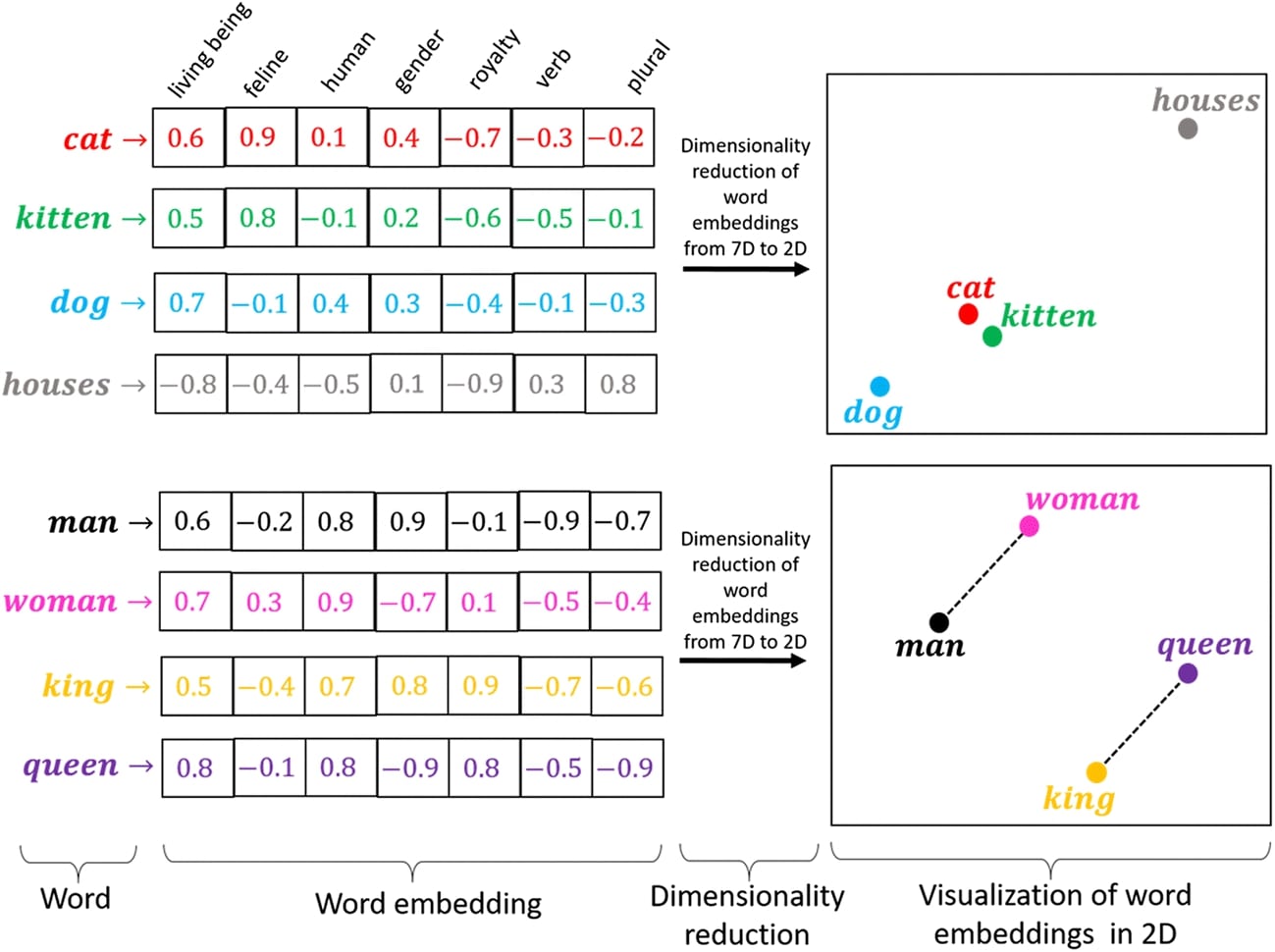
Basically, we first map text examples to token indexes and then retrieve word embeddings using these indexes.
The first two steps will be implemented in this section where we populate vocabulary and vectorize each text example using vocabulary. The third step will be implemented in the neural network through the embedding layer. The embedding layer has embeddings for each token which is retrieved using a token index.
Below, we have included an image showing word embeddings.
1.1 Load Dataset¶
In this section, we have loaded the dataset that we are going to use for our text classification task. We have loaded AG NEWS dataset available from torchtext Python library.The dataset has text documents for 4 different news categories ["World", "Sports", "Business", "Sci/Tech"].
import numpy as np
train_dataset, test_dataset = torchtext.datasets.AG_NEWS()
X_train_text, Y_train = [], []
for Y, X in train_dataset:
X_train_text.append(X)
Y_train.append(Y)
X_test_text, Y_test = [], []
for Y, X in test_dataset:
X_test_text.append(X)
Y_test.append(Y)
unique_classes = list(set(Y_train))
target_classes = ["World", "Sports", "Business", "Sci/Tech"]
## Subtracted 1 from labels to bring range from 1-4 to 0-3
Y_train, Y_test = np.array(Y_train) - 1, np.array(Y_test) - 1
len(X_train_text), len(X_test_text)
1.2 Tokenize Text Examples, Populate Vocabulary and Vectorize Text Examples¶
In this, we have implemented the first two steps we mentioned earlier to prepare data for the neural network.
We have first created an instance of Tokenizer class available from 'keras.preprocessing.text' module. This tokenizer instance will be used for populating vocabulary and generating indexes of tokens. After creating an instance, we have called fit_on_texts() method on it with train and test text examples. This step will internally loop through all text examples, tokenize them and populate vocabulary.
Next, we have called texts_to_sequences() method on Tokenizer object. We have provided a list of train and text examples for this method. This method tokenizes text examples and retrieves their token indexes from the vocabulary. We know that each text example has a different size text and we want input to a neural network with the same size. For this, we have wrapped call to texts_to_sequences() inside of call to function pad_sequences() function. We have decided to keep maximum of 50 tokens per text example. The pad_sequences() function ensures this. It truncates all text examples that have more than 50 tokens to 50 tokens and pads all text examples that have less than 50 tokens with 0s to bring them to the length of 50.
Below, we have explained with a simple example how text example is vectorized.
text = "Hello, How are you? Where are you planning to go?"
tokens = ['hello', ',', 'how', 'are', 'you', '?', 'where',
'are', 'you', 'planning', 'to', 'go', '?']
vocab = {
'hello': 0,
'bye': 1,
'how': 2,
'the': 3,
'welcome': 4,
'are': 5,
'you': 6,
'to': 7,
'<unk>': 8,
}
vector = [0,8,2,4,6,8,8,5,6,8,7,8,8]from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
max_tokens = 50 ## Hyperparameter
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X_train_text+X_test_text)
## Vectorizing data to keep 50 words per sample.
X_train_vect = pad_sequences(tokenizer.texts_to_sequences(X_train_text), maxlen=max_tokens, padding="post", truncating="post", value=0.)
X_test_vect = pad_sequences(tokenizer.texts_to_sequences(X_test_text), maxlen=max_tokens, padding="post", truncating="post", value=0.)
print(X_train_vect[:3])
X_train_vect.shape, X_test_vect.shape
## What is word 444
print(tokenizer.index_word[444])
## How many times it comes in first text document??
print(X_train_text[0]) ## 2 times
Approach 1: CNN with Single Conv1D Layer (Max Tokens=50, Embed Length=128, Conv Output Channels=32) ¶
Our first approach creates a Convolutional neural network with a single 1D convolution layer for the text classification task. The network has 3 layers namely the embedding layer, convolution layer, and dense layer. The embedding layer maps token index to embeddings which are given to Conv1D for performing convolution operation. The output of the convolution layer is given to the dense layer to generate probabilities for target classes. After training the network, we have also evaluated the performance by calculating various ML metrics.
Define Network¶
Here, we have defined a neural network that we'll be using for our text classification task. We have defined a neural network using functional API (Model) of Keras. The network consists of 3 layers.
- Embedding Layer
- 1D Convolution Layer
- Dense Layer
The first layer of the network is the embedding layer. We have created embedding layer using Embedding() constructor available from 'tensorflow.keras.layers' module. We have provided the length of vocabulary as a number. The embedding length is set at 128 which means that each token will be represented by a real-valued vector of length 128. When we initialized the embedding layer, it internally creates a weight matrix of shape (vocab_len, embed_len). This layer takes a list of token indexes as input and retrieves word embeddings for these indexes from the weight matrix using simple integer indexing. The input data shape to layer is (batch_size, max_tokens) = (batch_size, 50) and output shape is (batch_size, max_tokens, embed_len) = (batch_size, 50, 128).
The second layer in the network is Conv1D layer. We have created Conv1D layer with 32 output channels and kernel size 7. This will transform output channels to 32 and will apply kernel of size 7 to input data. The shape of input data to this layer is (batch_size, max_tokens, embed_len) and output shape is **(batch_size, max_tokens, conv_output_channels) = (batch_size, 50, 32). It transformed the embedding length dimension from 128 to 32.
To the output of convolution layer, we have called max() operation at max tokens dimension. This will transform data from shape (batch_size, 50, 32) to (batch_size, 32).
The last layer of the network is Dense layer with 4 output units (same as a number of target labels). The dense layer processes data from shape (batch_size, 32) to (batch_size, 4). It also applies softmax activation function to the output to generate 4 probabilities for each example. The output of the dense layer is the prediction of network.
After defining the network, we initialized it and printed a summary of the network parameters count.
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding, Conv1D, Dense
embed_len = 128
inputs = Input(shape=(max_tokens, ))
embeddings_layer = Embedding(input_dim=len(tokenizer.word_index)+1, output_dim=embed_len, input_length=max_tokens)
conv = Conv1D(32, 7, padding="same") ## Channels last
dense = Dense(len(target_classes), activation="softmax")
x = embeddings_layer(inputs)
x = conv(x)
x = tensorflow.reduce_max(x, axis=1)
output = dense(x)
model = Model(inputs=inputs, outputs=output)
model.summary()
Compile Network¶
Here, we have compiled our network to use Adam optimizer, cross entropy loss, and accuracy metric.
model.compile("adam", "sparse_categorical_crossentropy", metrics=["accuracy"])
Train Network¶
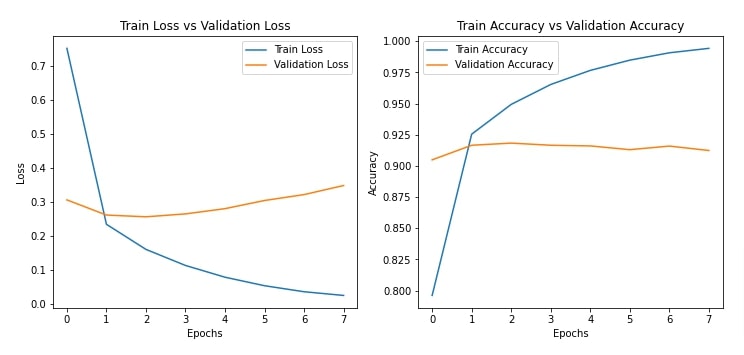
In this section, we have trained our network by calling fit() method. We have provided the method with train and validation data. We have set batch size at 1024 and trained the network for 8 epochs. We can notice from the loss and accuracy values getting printed after each epoch that our network is doing a good job at the text classification task.
After training the network, we have also plotted loss and accuracy values from history object.
history = model.fit(X_train_vect, Y_train, batch_size=1024, epochs=8, validation_data=(X_test_vect, Y_test))
gc.collect()
import matplotlib.pyplot as plt
def plot_loss_and_acc(history):
train_loss = history.history["loss"]
train_acc = history.history["accuracy"]
val_loss = history.history["val_loss"]
val_acc = history.history["val_accuracy"]
fig = plt.figure(figsize=(12,5))
ax = fig.add_subplot(121)
ax.plot(range(len(train_loss)), train_loss, label="Train Loss");
ax.plot(range(len(val_loss)), val_loss, label="Validation Loss");
plt.xlabel("Epochs"); plt.ylabel("Loss");
plt.title("Train Loss vs Validation Loss");
plt.legend(loc="best");
ax = fig.add_subplot(122)
ax.plot(range(len(train_acc)), train_acc, label="Train Accuracy");
ax.plot(range(len(val_acc)), val_acc, label="Validation Accuracy");
plt.xlabel("Epochs"); plt.ylabel("Accuracy");
plt.title("Train Accuracy vs Validation Accuracy");
plt.legend(loc="best");
plot_loss_and_acc(history)
Evaluate Network Performance¶
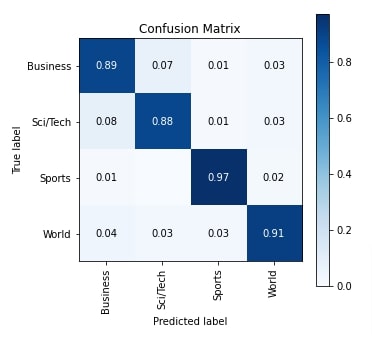
In this section, we have evaluated the performance of our trained network by calculating accuracy score, classification report (precision, recall, and f1-score per target class) and confusion matrix metrics on test predictions. We can notice from the accuracy score that our network is doing a good job at the given classification task. We have calculated these metrics using functions available from scikit-learn.
Please feel free to check the below link if you want to learn about various ML metrics available from sklearn in-depth.
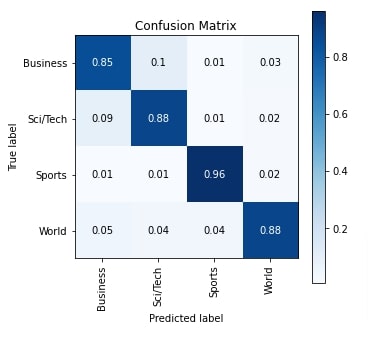
Apart from the calculation, we have also plotted the confusion matrix using Python library scikit-plot. We can notice from the visualization our network is good at classifying text documents of Sports and World categories compared to Business and Sci/Tech categories.
The scikit-plot is a Python library designed on top of matplotlib for plotting various ML metrics. If you are interested in learning about it then please check the below link as it provides visualizations for many useful ML metrics.
from sklearn.metrics import accuracy_score, classification_report
train_preds = model.predict(X_train_vect)
test_preds = model.predict(X_test_vect)
print("Train Accuracy : {}".format(accuracy_score(Y_train, np.argmax(train_preds, axis=1))))
print("Test Accuracy : {}".format(accuracy_score(Y_test, np.argmax(test_preds, axis=1))))
print("\nClassification Report : ")
print(classification_report(Y_test, np.argmax(test_preds, axis=1), target_names=target_classes))
from sklearn.metrics import confusion_matrix
import scikitplot as skplt
import matplotlib.pyplot as plt
skplt.metrics.plot_confusion_matrix([target_classes[i] for i in Y_test], [target_classes[i] for i in np.argmax(test_preds, axis=1)],
normalize=True,
title="Confusion Matrix",
cmap="Blues",
hide_zeros=True,
figsize=(5,5)
);
plt.xticks(rotation=90);
Explain Network Predictions using LIME Algorithm¶
In this section, we have explained predictions made by our network using LIME (Local Interpretable Model-Agnostic Explanations) algorithm. The algorithm helps us understand words from our text example that contributed to predicting a particular target label. We have used the Python library lime which has implemented this algorithm. It let us create visualization highlighting words in text examples that contributed to prediction.
If you are someone who is new to the concept of LIME then we recommend that you go through the below links to understand it in your free time.
- How to Use LIME to Understand sklearn Models Predictions?
- LIME: Interpret Predictions Of Keras Text Classification Networks
In order to generate explanation visualization using LIME, we first need to create an instance of LimeTextExplainer which we have done below.
from lime import lime_text
explainer = lime_text.LimeTextExplainer(class_names=target_classes, verbose=True)
explainer
Here, we have defined a function that takes a batch of text examples as input and returns their prediction probabilities using our model. This function will be used later to generate an explanation for prediction by the explainer object.
def make_predictions(X_batch_text):
X_batch = pad_sequences(tokenizer.texts_to_sequences(X_batch_text), maxlen=50, padding="post", truncating="post", value=0)
preds = model.predict(X_batch)
return preds
Here, we have selected one random text example from the test dataset and made predictions on it using our trained network. We can notice that our network correctly predicts the target label as Business for the selected example.
rng = np.random.RandomState(3)
idx = rng.randint(1, len(X_test_text))
print("Prediction : ", target_classes[model.predict(X_test_vect[idx:idx+1]).argmax(axis=-1)[0]])
print("Actual : ", target_classes[Y_test[idx]])
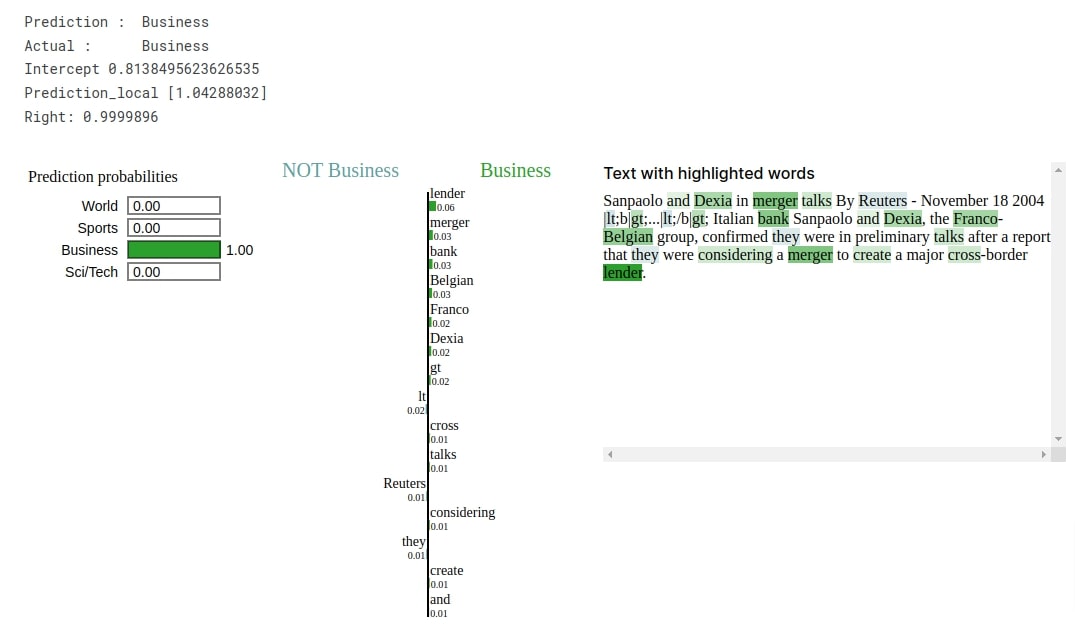
Below, we have called explain_instance() method on LimeTextExplainer instance to generate Explanation object. We have provided a selected text example, prediction function, and target label to the method to create an explanation object. Then, we have created a visualization of the explanation object by calling show_in_notebook() method on it. The visualization shows that words like 'lender', 'bank', 'merger', 'group', etc are contributing to predicting the target label as Business which makes sense as these are commonly used words in the business world.
explanation = explainer.explain_instance(X_test_text[idx], classifier_fn=make_predictions, labels=Y_test[idx:idx+1], num_features=15)
explanation.show_in_notebook()

Approach 2: CNN with Multiple Conv1D Layers (Max Tokens=50, Embed Length=128, Conv Output Channels=32,32) ¶
Our approach in this section uses multiple convolution layers instead of one for our text classification task. The majority of the code is the same as our previous section with the only change being network architecture which now uses multiple convolution layers instead.
Define Network¶
Below, we have defined the network that we'll use for our text classification task. The network consists of one embedding layer, two 1d convolution layers, and one dense layer. The embedding and dense layers are defined exactly like our previous approach. The main difference is that we have used two convolution layers after the embedding layer. Both convolution layers have 32 output channels and a kernel size of 7. The output of embedding is given to the first convolution for processing whose output is given to the second convolution for processing. The output of the second convolution is processed exactly like earlier by taking max at max tokens dimension and giving it to a dense layer for generating probabilities.
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding, Conv1D, Dense
embed_len = 128
inputs = Input(shape=(max_tokens, ))
embeddings_layer = Embedding(input_dim=len(tokenizer.word_index)+1, output_dim=embed_len, input_length=max_tokens)
conv1 = Conv1D(32, 7, padding="same") ## Channels last
conv2 = Conv1D(32, 7, padding="same") ## Channels last
dense = Dense(len(target_classes), activation="softmax")
x = embeddings_layer(inputs)
x = conv1(x)
x = conv2(x)
x = tensorflow.reduce_max(x, axis=1)
output = dense(x)
model = Model(inputs=inputs, outputs=output)
model.summary()
Compile Network¶
Here, we have compiled our network to use Adam optimizer, cross entropy loss, and accuracy metric.
model.compile("adam", "sparse_categorical_crossentropy", metrics=["accuracy"])
Train Network¶
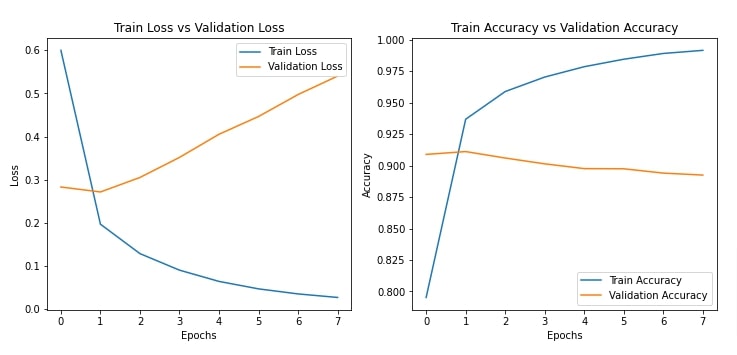
Below, we have trained our network using the same settings we had used for our previous approach which makes comparison easy. We can notice from the loss and accuracy values getting printed after each epoch that the network is doing a good job. We have also plotted loss and accuracy values per epoch.
history = model.fit(X_train_vect, Y_train, batch_size=1024, epochs=8, validation_data=(X_test_vect, Y_test))
gc.collect()
plot_loss_and_acc(history)
Evaluate Network Performance¶
In this section, we have evaluated the performance of our trained network as usual by calculating various ML metrics. We can notice from the test accuracy that it is a little less compared to our previous approach. This is surprising as we had expected that stacking more convolution layers can increase accuracy even further. We have also plotted the confusion matrix for reference purposes.
from sklearn.metrics import accuracy_score, classification_report
train_preds = model.predict(X_train_vect)
test_preds = model.predict(X_test_vect)
print("Train Accuracy : {}".format(accuracy_score(Y_train, np.argmax(train_preds, axis=1))))
print("Test Accuracy : {}".format(accuracy_score(Y_test, np.argmax(test_preds, axis=1))))
print("\nClassification Report : ")
print(classification_report(Y_test, np.argmax(test_preds, axis=1), target_names=target_classes))
from sklearn.metrics import confusion_matrix
import scikitplot as skplt
import matplotlib.pyplot as plt
skplt.metrics.plot_confusion_matrix([target_classes[i] for i in Y_test], [target_classes[i] for i in np.argmax(test_preds, axis=1)],
normalize=True,
title="Confusion Matrix",
cmap="Blues",
hide_zeros=True,
figsize=(5,5)
);
plt.xticks(rotation=90);
Explain Network Predictions using LIME Algorithm¶
In this section, we have explained predictions made by our trained network using LIME algorithm. Our network correctly predicts the target label as Business for the selected text example. The explanation visualization shows that words like 'lender', 'merger', 'bank', 'franco', 'talks', 'cross', etc are contributing to predicting target label as Business.
from lime import lime_text
explainer = lime_text.LimeTextExplainer(class_names=target_classes, verbose=True)
rng = np.random.RandomState(3)
idx = rng.randint(1, len(X_test_text))
print("Prediction : ", target_classes[model.predict(X_test_vect[idx:idx+1]).argmax(axis=-1)[0]])
print("Actual : ", target_classes[Y_test[idx]])
explanation = explainer.explain_instance(X_test_text[idx], classifier_fn=make_predictions, labels=Y_test[idx:idx+1], num_features=15)
explanation.show_in_notebook()
4. Results Summary And Further Suggestions ¶
| Approach | Max Tokens | Embedding Length | Conv1D Output Channels | Test Accuracy (%) |
|---|---|---|---|---|
| CNN with Single Conv1D Layer | 50 | 128 | 32 | 91.23 |
| CNN with Multiple Conv1D Layers | 50 | 128 | 32,32 | 89.25 |
Further Recommendations¶
- Try different max token sizes.
- Try different embedding lengths.
- Try different convolution output channels.
- Try different kernel sizes with 1D convolution layers.
- Try max-pooling/average pooling between convolution layers.
- Try operations other than max() to the output of the convolution layer (average, min, etc).
- Try stacking more convolution layers.
- Try adding more dense layers after convolution layers.
- Try different activation functions.
- Try different weight initializers.
- Try different optimizers.
- Train network for more epochs.
- Try learning rate schedulers.
This ends our small tutorial explaining how we can create CNNs with 1D convolution layers using Keras for text classification tasks. Please feel free to let us know your views in the comments section.
References¶
 Sunny Solanki
Sunny Solanki
Sunny Solanki
Intro: Software Developer | Youtuber | Bonsai Enthusiast
About: Sunny Solanki holds a bachelor's degree in Information Technology (2006-2010) from L.D. College of Engineering. Post completion of his graduation, he has 8.5+ years of experience (2011-2019) in the IT Industry (TCS). His IT experience involves working on Python & Java Projects with US/Canada banking clients. Since 2020, he’s primarily concentrating on growing CoderzColumn.
His main areas of interest are AI, Machine Learning, Data Visualization, and Concurrent Programming. He has good hands-on with Python and its ecosystem libraries.
Apart from his tech life, he prefers reading biographies and autobiographies. And yes, he spends his leisure time taking care of his plants and a few pre-Bonsai trees.
Contact: sunny.2309@yahoo.in



![YouTube Subscribe]() Comfortable Learning through Video Tutorials?
Comfortable Learning through Video Tutorials?
If you are more comfortable learning through video tutorials then we would recommend that you subscribe to our YouTube channel.
![Need Help]() Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
 Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?When going through coding examples, it's quite common to have doubts and errors.
If you have doubts about some code examples or are stuck somewhere when trying our code, send us an email at coderzcolumn07@gmail.com. We'll help you or point you in the direction where you can find a solution to your problem.
You can even send us a mail if you are trying something new and need guidance regarding coding. We'll try to respond as soon as possible.
![Share Views]() Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?
 Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?If you want to
- provide some suggestions on topic
- share your views
- include some details in tutorial
- suggest some new topics on which we should create tutorials/blogs
 keras, CNNs, conv1d, text-classification
keras, CNNs, conv1d, text-classification