How to Use GloVe Word Embeddings With PyTorch Networks?¶
Word embeddings is one of the most commonly used approaches nowadays when training text data using deep neural networks. Word embeddings let us use vectors of real values to represent a single token/word. Each word/token will have its own vector of floats. This helps improve the accuracy of models as more numbers better capture the meaning of the word/token and context compared to if we use only a single number (Word Frequency, Tf-Idf, etc.). We can generate word embeddings by ourselves if we have a big dataset that has a lot of words. We have already covered in detail how we can train a neural network using random word embeddings.
If we have a small dataset then rather than initializing and training our own word embeddings, we can use word embeddings generated by other networks as well. There are many word embeddings available like GloVe, FastText, word2vec, etc. These are embeddings trained for other tasks but they have captured the meaning of the words/tokens hence we can use the same embeddings for our task. They have embeddings for millions of words/tokens hence the majority of our words might be present in them.
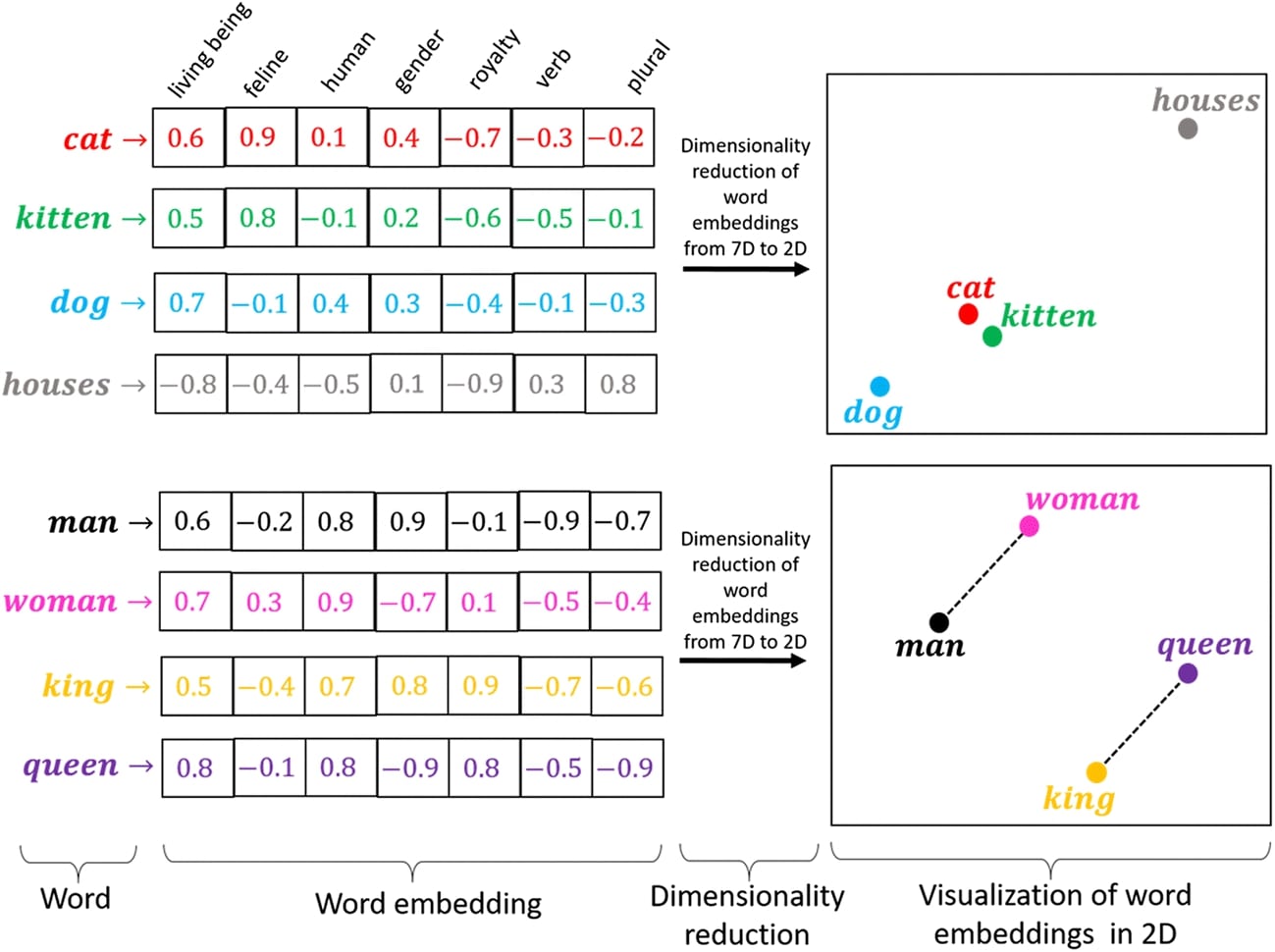
As a part of our tutorial, we'll explain how we can use Glove (Global Vectors) embeddings with our PyTorch network for classification tasks. There are various versions of GloVe embeddings that are created using an unsupervised learning algorithm that was trained on a large corpus of Wikipedia and twitter texts. We have used AG NEWS dataset for our task and will be taking embeddings for words of the dataset from GloVe.
Below, we have listed important sections of tutorial to give an overview of the material covered.
Important Sections Of Tutorial¶
- Approach 1: GloVe '840B' (Embeddings Length=300, Tokens per Text Example=25)
- Create Tokenizer
- Load GloVe '840B' Embeddings
- Load Datsets And Create Data Loaders
- Define Network
- Train Network
- Evaluate Network Performance
- Approach 2: GloVe '840B' (Embeddings Length=300, Tokens per Text Example=50)
- Approach 3: GloVe '42B' (Embeddings Length=300, Tokens per Text Example=50)
- Approach 4: GloVe '840B' Averaged (Embeddings Length=300, Tokens per Text Example=50)
- Approach 5: GloVe '840B' Summed (Embeddings Length=300, Tokens per Text Example=50)
Below, we have loaded the necessary libraries and printed the versions that we have used in our tutorial.
import torch
print("PyTorch Version : {}".format(torch.__version__))
import torchtext
print("Torch Text Version : {}".format(torchtext.__version__))
Approach 1: GloVe '840B' (Embeddings Length=300, Tokens per Text Example=25) ¶
As a part of our first approach, we'll use GloVe 840B embeddings. It has embeddings for 2.2 Million unique tokens and the length of each token is 300. There are different types of GloVe embeddings available from Stanford. Please check the below link for a list of available embeddings types.
For our approach in this section, we have decided to keep a maximum of 25 tokens/words per text example and we'll look for embeddings of these tokens in GloVe embeddings.
Create Tokenizer¶
Below, we have simply loaded a tokenizer that we'll use for our text classification task. We have loaded a simple tokenizer available from torchtext.data module. The tokenizer is a function that takes a text document as input and generates a list of tokens.
from torchtext.data import get_tokenizer
tokenizer = get_tokenizer("basic_english") ## We'll use tokenizer available from PyTorch
tokenizer("Hello, How are you?")
Load GloVe '840B' Embeddings¶
The torchtext module provides us with a class named GloVe which can be used to load GloVe embeddings. It is available from vocab module of torchttext. We need to provide the embedding name and dimensions to it. There are embeddings of different dimensions (50, 100, 200, 300, etc) available.
Once we have loaded GloVe embeddings by creating an instance of GloVe. We can call get_vecs_by_tokens() method of it by giving a list of tokens to it. It'll return embeddings for all tokens given to it. We have explained with simple examples below how to use it.
from torchtext.vocab import GloVe
global_vectors = GloVe(name='840B', dim=300)
embeddings = global_vectors.get_vecs_by_tokens(tokenizer("Hello, How are you?"), lower_case_backup=True)
embeddings.shape
global_vectors.get_vecs_by_tokens([""], lower_case_backup=True)
Load Datasets And Create Data Loaders¶
In this section, we have loaded our AG NEWS dataset and created data loaders from it. The dataset has text documents for 4 different categories (["World", "Sports", "Business", "Sci/Tech"]) of news. We can load dataset by calling AG_NEWS() function from datasets module of torchtext. It returns train and test datasets separately. After loading datasets, we have created data loaders for them that will be used during training. We have set the batch size to 1024 for data loaders.
When creating data loaders, we have given a function to collate_fn parameter of DataLoader() constructor. This function will be applied to all batches and the return value of this function will be our single dataset. The function loops through each text document of the batch and tokenizes it. During tokenization, it makes sure that we keep 25 tokens per text example. It'll pad with empty string tokens for example that has less than 25 tokens and for examples that have more than 25 tokens, it'll truncate them to 25 tokens. It then retrieves GloVe embeddings for tokens of the batch. At last, we have put embeddings for tokens of text example next to each other and returned them along with their target labels converted to torch tensors. We have also subtracted 1 from target labels because from the dataset, they are in the range 1-4 and we need them in the range 0-3.
from torch.utils.data import DataLoader
from torchtext.data.functional import to_map_style_dataset
max_words = 25
embed_len = 300
def vectorize_batch(batch):
Y, X = list(zip(*batch))
X = [tokenizer(x) for x in X]
X = [tokens+[""] * (max_words-len(tokens)) if len(tokens)<max_words else tokens[:max_words] for tokens in X]
X_tensor = torch.zeros(len(batch), max_words, embed_len)
for i, tokens in enumerate(X):
X_tensor[i] = global_vectors.get_vecs_by_tokens(tokens)
return X_tensor.reshape(len(batch), -1), torch.tensor(Y) - 1 ## Subtracted 1 from labels to bring in range [0,1,2,3] from [1,2,3,4]
target_classes = ["World", "Sports", "Business", "Sci/Tech"]
train_dataset, test_dataset = torchtext.datasets.AG_NEWS()
train_dataset, test_dataset = to_map_style_dataset(train_dataset), to_map_style_dataset(test_dataset)
train_loader = DataLoader(train_dataset, batch_size=1024, collate_fn=vectorize_batch)
test_loader = DataLoader(test_dataset, batch_size=1024, collate_fn=vectorize_batch)
for X, Y in train_loader:
print(X.shape, Y.shape)
break
Define Network¶
In this section, we have defined a network that we'll use for classifying our text documents. The network consists of 4 linear layers. The linear layers have 256, 128, 64, and 4 output units respectively. We have applied relu activation after each linear layer except the last linear layer. We have defined the network using Sequential API of PyTorch.
Please feel free to check the below tutorial if you want some background on how to create neural networks using PyTorch.
from torch import nn
from torch.nn import functional as F
class EmbeddingClassifier(nn.Module):
def __init__(self):
super(EmbeddingClassifier, self).__init__()
self.seq = nn.Sequential(
nn.Linear(max_words*embed_len, 256),
nn.ReLU(),
nn.Linear(256,128),
nn.ReLU(),
nn.Linear(128,64),
nn.ReLU(),
nn.Linear(64, len(target_classes)),
)
def forward(self, X_batch):
return self.seq(X_batch)
Train Network¶
In this section, we have trained our network. To train the network, we have defined a helper function. The function takes the model, loss function, optimizer, train loader, validation loader, and a number of epochs as input. It then executes the training process for a number of epochs. During each epoch, it loops through training data in batches using the training data loader we created earlier. For each batch, it performs a forward pass to make predictions, calculates loss (using predictions and actual target labels), calculate gradients, and updates network parameter at last using gradients. It records loss for each batch and prints the average loss of all batches at the end of each epoch. We have also created another helper function that calculates the loss and accuracy of the trained model on the validation dataset at the end of each epoch.
from tqdm import tqdm
from sklearn.metrics import accuracy_score
import gc
def CalcValLossAndAccuracy(model, loss_fn, val_loader):
with torch.no_grad():
Y_shuffled, Y_preds, losses = [],[],[]
for X, Y in val_loader:
preds = model(X)
loss = loss_fn(preds, Y)
losses.append(loss.item())
Y_shuffled.append(Y)
Y_preds.append(preds.argmax(dim=-1))
Y_shuffled = torch.cat(Y_shuffled)
Y_preds = torch.cat(Y_preds)
print("Valid Loss : {:.3f}".format(torch.tensor(losses).mean()))
print("Valid Acc : {:.3f}".format(accuracy_score(Y_shuffled.detach().numpy(), Y_preds.detach().numpy())))
def TrainModel(model, loss_fn, optimizer, train_loader, val_loader, epochs=10):
for i in range(1, epochs+1):
losses = []
for X, Y in tqdm(train_loader):
Y_preds = model(X)
loss = loss_fn(Y_preds, Y)
losses.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%5==0:
print("Train Loss : {:.3f}".format(torch.tensor(losses).mean()))
CalcValLossAndAccuracy(model, loss_fn, val_loader)
Below, we have trained our network using the function we designed in the previous cell. We have initialized a number of epochs to 25 and the learning rate to 0.001. Then, we have initialized Cross entropy loss, our text classification network, and Adam optimizer. At last, we have called our training routine with the necessary parameters to perform training. We can notice from the loss and accuracy value getting printed at the end of each epoch that our model is doing a good job.
from torch.optim import Adam
epochs = 25
learning_rate = 1e-3
loss_fn = nn.CrossEntropyLoss()
embed_classifier = EmbeddingClassifier()
optimizer = Adam(embed_classifier.parameters(), lr=learning_rate)
TrainModel(embed_classifier, loss_fn, optimizer, train_loader, test_loader, epochs)
Evaluate Network Performance¶
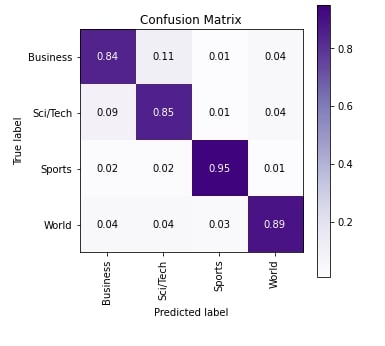
Here, we have evaluated the network performance by calculating accuracy, classification report (precision, recall, and f1-score per target class) and confusion matrix metrics for test predictions. We have created a helper function that takes the model and loader objects as input and returns predictions. We can notice from the accuracy that our model is doing quite a good job at classifying text documents.
In the cell after below cell, we have also plotted the confusion matrix for test predictions using scikit-plot library. From the plot, we can notice that our model is doing good for categories Sports and World compared to categories Business and Sci/Tech. If you are interested in learning about various ML metrics plots available from scikit-plot then please feel free to check the below link.
def MakePredictions(model, loader):
Y_shuffled, Y_preds = [], []
for X, Y in loader:
preds = model(X)
Y_preds.append(preds)
Y_shuffled.append(Y)
gc.collect()
Y_preds, Y_shuffled = torch.cat(Y_preds), torch.cat(Y_shuffled)
return Y_shuffled.detach().numpy(), F.softmax(Y_preds, dim=-1).argmax(dim=-1).detach().numpy()
Y_actual, Y_preds = MakePredictions(embed_classifier, test_loader)
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
print("Test Accuracy : {}".format(accuracy_score(Y_actual, Y_preds)))
print("\nClassification Report : ")
print(classification_report(Y_actual, Y_preds, target_names=target_classes))
print("\nConfusion Matrix : ")
print(confusion_matrix(Y_actual, Y_preds))
from sklearn.metrics import confusion_matrix
import scikitplot as skplt
import matplotlib.pyplot as plt
import numpy as np
skplt.metrics.plot_confusion_matrix([target_classes[i] for i in Y_actual], [target_classes[i] for i in Y_preds],
normalize=True,
title="Confusion Matrix",
cmap="Purples",
hide_zeros=True,
figsize=(5,5)
);
plt.xticks(rotation=90);
Approach 2: GloVe '840B' (Embeddings Length=300, Tokens per Text Example=50) ¶
Our approach in this section is almost the same as our approach in the previous section with the only difference that we are using 50 tokens per text example here unlike our previous approach where we had used 25 per text example. We are still using the same GloVe 840B word embedding as our previous approach. The majority of the code in this section is almost the same as our previous section code.
Load Datasets And Create Data Loaders¶
Below, we have loaded datasets and defined data loaders. We have set the max tokens per text example at the beginning to 50.
from torch.utils.data import DataLoader
from torchtext.data.functional import to_map_style_dataset
max_words = 50
embed_len = 300
train_dataset, test_dataset = torchtext.datasets.AG_NEWS()
train_dataset, test_dataset = to_map_style_dataset(train_dataset), to_map_style_dataset(test_dataset)
train_loader = DataLoader(train_dataset, batch_size=1024, collate_fn=vectorize_batch)
test_loader = DataLoader(test_dataset, batch_size=1024, collate_fn=vectorize_batch)
for X, Y in train_loader:
print(X.shape, Y.shape)
break
Define Network¶
Below, we have again defined our network which has exactly the same structure as our network from the previous section. The only difference is the input length to the first layer which is 15000 (50 * 300) this time.
from torch import nn
from torch.nn import functional as F
class EmbeddingClassifier(nn.Module):
def __init__(self):
super(EmbeddingClassifier, self).__init__()
self.seq = nn.Sequential(
nn.Linear(max_words*embed_len, 256),
nn.ReLU(),
nn.Linear(256,128),
nn.ReLU(),
nn.Linear(128,64),
nn.ReLU(),
nn.Linear(64, len(target_classes)),
)
def forward(self, X_batch):
return self.seq(X_batch)
Train Network¶
Here, we have trained our network using exactly the same settings that we have used in our previous section. We can notice from the loss and accuracy getting printed after each epoch that the model is doing a good job.
from torch.optim import Adam
epochs = 25
learning_rate = 1e-3
loss_fn = nn.CrossEntropyLoss()
embed_classifier = EmbeddingClassifier()
optimizer = Adam(embed_classifier.parameters(), lr=learning_rate)
TrainModel(embed_classifier, loss_fn, optimizer, train_loader, test_loader, epochs)
Evaluate Network Performance¶
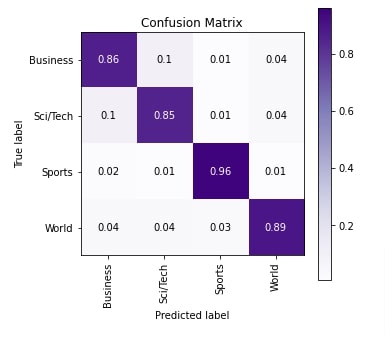
In this section, we have evaluated the network performance by calculating various metrics like our previous approach. We can notice from the test accuracy that there is very little improvement in accuracy by changing the approach to use 50 words per text example compared to 25 words.
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
Y_actual, Y_preds = MakePredictions(embed_classifier, test_loader)
print("Test Accuracy : {}".format(accuracy_score(Y_actual, Y_preds)))
print("\nClassification Report : ")
print(classification_report(Y_actual, Y_preds, target_names=target_classes))
print("\nConfusion Matrix : ")
print(confusion_matrix(Y_actual, Y_preds))
from sklearn.metrics import confusion_matrix
import scikitplot as skplt
import matplotlib.pyplot as plt
import numpy as np
skplt.metrics.plot_confusion_matrix([target_classes[i] for i in Y_actual], [target_classes[i] for i in Y_preds],
normalize=True,
title="Confusion Matrix",
cmap="Purples",
hide_zeros=True,
figsize=(5,5)
);
plt.xticks(rotation=90);
Approach 3: GloVe '42B' (Embeddings Length=300, Tokens per Text Example=50) ¶
Our approach in this section is almost exactly the same as our approach in the previous section with the only difference that we are using GloVe 42B word embeddings this time instead of 840B embeddings. We have used 50 words per text example again this time as well. The GloVe 42B embeddings have embeddings for 1.9 Million unique tokens.
Load Glove '42B' Embeddings¶
Below, we have loaded GloVe 42B word embeddings using GloVe() constructor.
from torchtext.vocab import GloVe
global_vectors = GloVe(name='42B', dim=300)
embeddings = global_vectors.get_vecs_by_tokens(tokenizer("Hello, How are you?"), lower_case_backup=True)
embeddings.shape
Load Datasets And Create Data Loaders¶
In this section, we have again loaded datasets and created data loaders from them. The new data loaders will now use GloVe 42B word embeddings to vectorize text data.
from torch.utils.data import DataLoader
from torchtext.data.functional import to_map_style_dataset
max_words = 50
embed_len = 300
train_dataset, test_dataset = torchtext.datasets.AG_NEWS()
train_dataset, test_dataset = to_map_style_dataset(train_dataset), to_map_style_dataset(test_dataset)
train_loader = DataLoader(train_dataset, batch_size=1024, collate_fn=vectorize_batch)
test_loader = DataLoader(test_dataset, batch_size=1024, collate_fn=vectorize_batch)
Define Network¶
Below, we have again defined a network that we'll use for our text classification task. It has exactly the same code as our previous example.
from torch import nn
from torch.nn import functional as F
class EmbeddingClassifier(nn.Module):
def __init__(self):
super(EmbeddingClassifier, self).__init__()
self.seq = nn.Sequential(
nn.Linear(max_words*embed_len, 256),
nn.ReLU(),
nn.Linear(256,128),
nn.ReLU(),
nn.Linear(128,64),
nn.ReLU(),
nn.Linear(64, len(target_classes)),
)
def forward(self, X_batch):
return self.seq(X_batch)
Train Network¶
Here, we have trained our network again using the same settings we had used in our previous approaches. The loss and accuracy getting printed after each epoch points out that our model is doing a good job.
from torch.optim import Adam
epochs = 25
learning_rate = 1e-3
loss_fn = nn.CrossEntropyLoss()
embed_classifier = EmbeddingClassifier()
optimizer = Adam(embed_classifier.parameters(), lr=learning_rate)
TrainModel(embed_classifier, loss_fn, optimizer, train_loader, test_loader, epochs)
Evaluate Network Performance¶
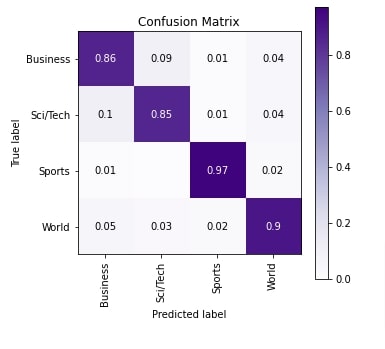
Below, we have calculated various ML metrics to evaluate the performance of our network as usual and we have also plotted the confusion matrix. We can notice from the results that there is a slight improvement in accuracy even though we have used only GloVe 42B embeddings which have embeddings for fewer tokens compared to GloVe 840B embeddings.
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
Y_actual, Y_preds = MakePredictions(embed_classifier, test_loader)
print("Test Accuracy : {}".format(accuracy_score(Y_actual, Y_preds)))
print("\nClassification Report : ")
print(classification_report(Y_actual, Y_preds, target_names=target_classes))
print("\nConfusion Matrix : ")
print(confusion_matrix(Y_actual, Y_preds))
from sklearn.metrics import confusion_matrix
import scikitplot as skplt
import matplotlib.pyplot as plt
import numpy as np
skplt.metrics.plot_confusion_matrix([target_classes[i] for i in Y_actual], [target_classes[i] for i in Y_preds],
normalize=True,
title="Confusion Matrix",
cmap="Purples",
hide_zeros=True,
figsize=(5,5)
);
plt.xticks(rotation=90);
Approach 4: GloVe '840B' Averaged (Embeddings Length=300, Tokens per Text Example=50) ¶
Our approach in this again uses GloVe 840B embeddings and 50 tokens per text example. The main difference in this approach is the way we have handled embeddings per text example. Till now, all our approaches kept embeddings for all tokens and laid them next to each other to create a single big tensor for each text example. As for our previous example, where we had kept 50 tokens per text example and the embedding length was 300 per token, hence the flattened vector will have 50x300 = 15000 embeddings.
But in this approach, we have made a minor change in the way we handle embeddings per text example. We have taken the average of embeddings of all tokens per text example. In this section, we have averaged embeddings of length 300 for 50 tokens hence we'll have a vector of length 300 after averaging.
Load GloVe '840B' Embeddings¶
Below, we have again loaded GloVe 840B word embeddings which we'll use in this section.
from torchtext.vocab import GloVe
global_vectors = GloVe(name='840B', dim=300)
Load Datasets And Create Data Loaders¶
Here, we have again loaded our datasets and created data loaders. The only difference is in the last line of the vectorization function which we are giving to collate_fn parameter. We have called mean() function to take an average of embeddings of tokens of each text example. The rest of the code is the same as earlier. This will return averaged embeddings for each batch.
from torch.utils.data import DataLoader
from torchtext.data.functional import to_map_style_dataset
max_words = 50
embed_len = 300
def vectorize_batch(batch):
Y, X = list(zip(*batch))
X = [tokenizer(x) for x in X]
X = [tokens+[""] * (max_words-len(tokens)) if len(tokens)<max_words else tokens[:max_words] for tokens in X]
X_tensor = torch.zeros(len(batch), max_words, embed_len)
for i, tokens in enumerate(X):
X_tensor[i] = global_vectors.get_vecs_by_tokens(tokens)
return X_tensor.mean(dim=1), torch.tensor(Y) - 1 ## Averaging Embedding accross all words of text document
train_dataset, test_dataset = torchtext.datasets.AG_NEWS()
train_dataset, test_dataset = to_map_style_dataset(train_dataset), to_map_style_dataset(test_dataset)
train_loader = DataLoader(train_dataset, batch_size=1024, collate_fn=vectorize_batch)
test_loader = DataLoader(test_dataset, batch_size=1024, collate_fn=vectorize_batch)
for X, Y in train_loader:
print(X.shape, Y.shape)
break
Define Network¶
Below, we have defined a network that we'll use for our task in this section. The network has the same structure as the networks we are using till now. The only difference is the input shape.
from torch import nn
from torch.nn import functional as F
class EmbeddingClassifier(nn.Module):
def __init__(self):
super(EmbeddingClassifier, self).__init__()
self.seq = nn.Sequential(
nn.Linear(embed_len, 256),
nn.ReLU(),
nn.Linear(256,128),
nn.ReLU(),
nn.Linear(128,64),
nn.ReLU(),
nn.Linear(64, len(target_classes)),
)
def forward(self, X_batch):
return self.seq(X_batch)
Train Network¶
Here, we have trained our neural network using the same settings that we are using for all our previous approaches. We can notice from the loss and accuracy getting printed after each epoch that the model is getting quite good at the text classification task.
from torch.optim import Adam
epochs = 25
learning_rate = 1e-3
loss_fn = nn.CrossEntropyLoss()
embed_classifier = EmbeddingClassifier()
optimizer = Adam(embed_classifier.parameters(), lr=learning_rate)
TrainModel(embed_classifier, loss_fn, optimizer, train_loader, test_loader, epochs)
Evaluate Network Performance¶
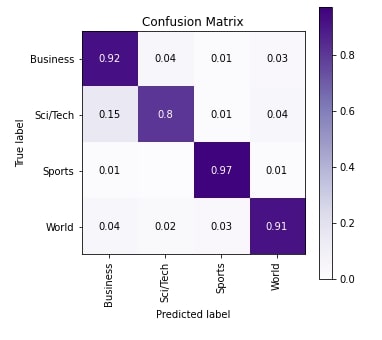
Here, we have evaluated various ML metrics as usual to check network performance. We can notice from the results that test accuracy is the highest of all the approaches we tried till now.
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
Y_actual, Y_preds = MakePredictions(embed_classifier, test_loader)
print("Test Accuracy : {}".format(accuracy_score(Y_actual, Y_preds)))
print("\nClassification Report : ")
print(classification_report(Y_actual, Y_preds, target_names=target_classes))
print("\nConfusion Matrix : ")
print(confusion_matrix(Y_actual, Y_preds))
from sklearn.metrics import confusion_matrix
import scikitplot as skplt
import matplotlib.pyplot as plt
import numpy as np
skplt.metrics.plot_confusion_matrix([target_classes[i] for i in Y_actual], [target_classes[i] for i in Y_preds],
normalize=True,
title="Confusion Matrix",
cmap="Purples",
hide_zeros=True,
figsize=(5,5)
);
plt.xticks(rotation=90);
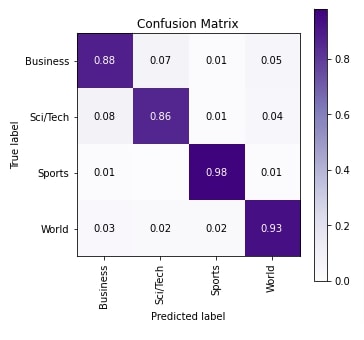
Approach 5: GloVe '840B' Summed (Embeddings Length=300, Tokens per Text Example=50) ¶
Our approach in this section is almost exactly the same as our approach in the previous section with one minor change. We have again used GloVe 840B words embeddings and 50 tokens per text example. The main difference this approach has is that we sum up embeddings of tokens of each text example. In our previous approach, we have taken average and here, we are summing up embeddings.
Load Datasets And Create Data Loaders¶
Below, we have again loaded datasets and created data loaders from them. There is a minor change in the definition of the vectorization function. The last line of the function uses sum() function to sum up embeddings. The rest of the code is the same as earlier.
from torch.utils.data import DataLoader
from torchtext.data.functional import to_map_style_dataset
max_words = 50
embed_len = 300
def vectorize_batch(batch):
Y, X = list(zip(*batch))
X = [tokenizer(x) for x in X]
X = [tokens+[""] * (max_words-len(tokens)) if len(tokens)<max_words else tokens[:max_words] for tokens in X]
X_tensor = torch.zeros(len(batch), max_words, embed_len)
for i, tokens in enumerate(X):
X_tensor[i] = global_vectors.get_vecs_by_tokens(tokens)
return X_tensor.sum(dim=1), torch.tensor(Y) - 1 ## Summing Embedding accross all words of text document
train_dataset, test_dataset = torchtext.datasets.AG_NEWS()
train_dataset, test_dataset = to_map_style_dataset(train_dataset), to_map_style_dataset(test_dataset)
train_loader = DataLoader(train_dataset, batch_size=1024, collate_fn=vectorize_batch)
test_loader = DataLoader(test_dataset, batch_size=1024, collate_fn=vectorize_batch)
for X, Y in train_loader:
print(X.shape, Y.shape)
break
Define Network¶
Below, we have again defined the network that we'll use for our task. It has exactly the same structure as our network from the previous section.
from torch import nn
from torch.nn import functional as F
class EmbeddingClassifier(nn.Module):
def __init__(self):
super(EmbeddingClassifier, self).__init__()
self.seq = nn.Sequential(
nn.Linear(embed_len, 256),
nn.ReLU(),
nn.Linear(256,128),
nn.ReLU(),
nn.Linear(128,64),
nn.ReLU(),
nn.Linear(64, len(target_classes)),
)
def forward(self, X_batch):
return self.seq(X_batch)
Train Network¶
Below, we have trained our network using the same settings we have used for all our previous approaches. The loss and accuracy getting printed at the end of each epoch point that the model is doing quite a good job at classifying text documents.
from torch.optim import Adam
epochs = 25
learning_rate = 1e-3
loss_fn = nn.CrossEntropyLoss()
embed_classifier = EmbeddingClassifier()
optimizer = Adam(embed_classifier.parameters(), lr=learning_rate)
TrainModel(embed_classifier, loss_fn, optimizer, train_loader, test_loader, epochs)
Evaluate Network Performance¶
Here, we have again calculated various ML metrics on test predictions and plotted the confusion matrix as usual to evaluate network performance. The accuracy hints that it's better than our first three approaches but a little less compared to our previous approach which averaged embeddings.
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
Y_actual, Y_preds = MakePredictions(embed_classifier, test_loader)
print("Test Accuracy : {}".format(accuracy_score(Y_actual, Y_preds)))
print("\nClassification Report : ")
print(classification_report(Y_actual, Y_preds, target_names=target_classes))
print("\nConfusion Matrix : ")
print(confusion_matrix(Y_actual, Y_preds))
from sklearn.metrics import confusion_matrix
import scikitplot as skplt
import matplotlib.pyplot as plt
import numpy as np
skplt.metrics.plot_confusion_matrix([target_classes[i] for i in Y_actual], [target_classes[i] for i in Y_preds],
normalize=True,
title="Confusion Matrix",
cmap="Purples",
hide_zeros=True,
figsize=(5,5)
);
plt.xticks(rotation=90);
This ends our small tutorial explaining how we can use pre-trained embeddings like GloVe for text classification tasks using PyTorch networks. Please feel free to let us know your views in the comments section.
References¶
 Sunny Solanki
Sunny Solanki
Sunny Solanki
Intro: Software Developer | Youtuber | Bonsai Enthusiast
About: Sunny Solanki holds a bachelor's degree in Information Technology (2006-2010) from L.D. College of Engineering. Post completion of his graduation, he has 8.5+ years of experience (2011-2019) in the IT Industry (TCS). His IT experience involves working on Python & Java Projects with US/Canada banking clients. Since 2020, he’s primarily concentrating on growing CoderzColumn.
His main areas of interest are AI, Machine Learning, Data Visualization, and Concurrent Programming. He has good hands-on with Python and its ecosystem libraries.
Apart from his tech life, he prefers reading biographies and autobiographies. And yes, he spends his leisure time taking care of his plants and a few pre-Bonsai trees.
Contact: sunny.2309@yahoo.in



![YouTube Subscribe]() Comfortable Learning through Video Tutorials?
Comfortable Learning through Video Tutorials?
If you are more comfortable learning through video tutorials then we would recommend that you subscribe to our YouTube channel.
![Need Help]() Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
 Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?When going through coding examples, it's quite common to have doubts and errors.
If you have doubts about some code examples or are stuck somewhere when trying our code, send us an email at coderzcolumn07@gmail.com. We'll help you or point you in the direction where you can find a solution to your problem.
You can even send us a mail if you are trying something new and need guidance regarding coding. We'll try to respond as soon as possible.
![Share Views]() Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?
 Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?If you want to
- provide some suggestions on topic
- share your views
- include some details in tutorial
- suggest some new topics on which we should create tutorials/blogs
 glove-embeddings, pytorch, text-classification
glove-embeddings, pytorch, text-classification