XGBoost - An In-Depth Guide [Python API]¶
> What is XGBoost (Extreme Gradient Boosting)?¶
Xgboost is a machine learning library that implements the gradient boosting algorithms (gradient boosted decision trees). The gradient boosted decision trees is a type of gradient boosting machines algorithm that has many decision trees in an ensemble. All these decision trees are generally weak predictors and their predictions are combined to make final prediction.
> Why Choose "XGBoost" Over Other Gradient Boosting Trees Implementations?¶
XGBoost is designed to be quite fast compared to the implementation available in sklearn.
XGBoost lets us handle a large amount of data that can have samples in billions with ease.
It can run in parallel and distributed environments to speed up the training process. The distributed algorithm can be useful if data does not fit into to main memory of the machine. Currently, it has support for dask to run the algorithm in a distributed environment.
Xgboost even supports running an algorithm on GPU with a simple configuration which will complete quite fast compared to when run on CPU.
Xgboost provides API in C, C++, Python, R, Java, Julia, Ruby, and Swift.
Xgboost code can be run on a distributed environment like AWS YARN, Hadoop, etc.
It even provides an interface (CLI) to run the algorithm from the command line/shell.
Apart from this, xgboost provides support for controlling feature interactions, custom evaluation functions, callbacks during training, monotonic constraints, etc.
> What Can You Learn From This Article?¶
As a part of this tutorial, we have explained how to use Python library XGBoost to solve machine learning tasks (Classification & Regression). We have explained majority of Python API with simple and easy-to-understand examples.
Apart from training models & making predictions, we have covered concepts like cross-validation, saving & loading models, visualizing features importances, early stop training to avoid overfitting, creating custom object/loss function, creating custom evaluation metrics, callbacks during training, distributed training using dask, GPU training, etc.
All our examples are trained on toy datasets (structured - tabular) available from scikit-learn to keep things simple and easy to grasp
We have tried to cover the majority of features available from xgboost to make this tutorial a short reference to master xgboost Python API.
> Which Other Python Libraries Provides Implementation Of Gradient Boosted Trees?¶
> How to Install XGBoost?¶
- PIP
- pip install -U xgboost
- Conda
- conda install py-xgboost
Below, we have listed important sections of tutorial to give an overview of the material covered. We know that the list below is big but you can skip some sections of tutorial which has a theory or repeat example of some concepts. We have included NOTE in those sections so you can skip them to complete tutorial faster. You can then refer to those sections in your free time or as per need.
Important Sections Of Tutorial¶
- Load Datasets for Tutorial
- Boston Housing Dataset
- Breast Cancer Dataset
- Wine Dataset
- XGBoost Estimators at High-Level (High-Level API)
- Core API: Booster Estimator
- Booster: Regression Example
- Divide Data into Train and Test Sets
- DMatrix: XGBoost Data Structure to Represent Data
- "train()": Train Model
- "predict()": Make Predictions
- Evaluate Model Performance
- Visualize Features Importances using "plot_importance()"
- Important Parameters of Boosting (train())
- Booster: Tweedie Regression Example
- Booster: Binary Classification Example
- Booster: Multi-Class Classification Example
- Saving and Loading Trained Model
- Cross Validation
- Booster: Regression Example
- Sklearn Like API
- XGBRegressor
- Train Model, Make Predictions & Evaluate Model Performance
- Hyperparameters Tuning using Grid Search
- XGBClassifier
- XGBRFRegressor
- XGBRFClassifier
- XGBRegressor
- Early Stop Training to Avoid Overfitting
- Feature Interaction Constraints
- Monotonic Constraints
- Custom Objective/Loss Function
- Custom Evaluation Functions
- Callbacks
- Dask Backend for Distributed Training
- GPU Support
- GPU & Dask Together For Parallel GPUs
We'll start by importing the necessary libraries which we'll use as a part of this tutorial.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
pd.set_option("display.max_columns", 50)
import xgboost as xgb
import sklearn
print("XGB Version : ", xgb.__version__)
print("Scikit-Learn Version : ", sklearn.__version__)
1. Load Datasets¶
We'll be using the below-mentioned three different datasets which are available from sklearn as a part of this tutorial for explanation purposes.
- Boston Housing Dataset: It's a regression problem dataset which has information about a various attribute of houses in Boston and their price in dollar. This will be used for regression tasks.
- Breast Cancer Dataset: It's a classification dataset which has information about two different types of tumor. It'll be used for explaining binary classification tasks.
- Wine Dataset - It's a classification dataset which has information about ingredients used in three different types of wines. It'll be used for explaining multi-class classification tasks.
We have loaded all three datasets mentioned one by one below. We are printing descriptions of datasets which gives us an overview of dataset features and size. We have even loaded each dataset as a pandas data frame and displayed the first few samples of data.
Boston Housing Dataset¶
from sklearn.datasets import load_boston
boston = load_boston()
for line in boston.DESCR.split("\n")[5:29]:
print(line)
boston_df = pd.DataFrame(data=boston.data, columns = boston.feature_names)
boston_df["Price"] = boston.target
boston_df.head()
Breast Cancer Dataset¶
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
for line in breast_cancer.DESCR.split("\n")[5:31]:
print(line)
breast_cancer_df = pd.DataFrame(data=breast_cancer.data, columns = breast_cancer.feature_names)
breast_cancer_df["TumorType"] = breast_cancer.target
breast_cancer_df.head()
Wine Dataset¶
from sklearn.datasets import load_wine
wine = load_wine()
for line in wine.DESCR.split("\n")[5:29]:
print(line)
wine_df = pd.DataFrame(data=wine.data, columns = wine.feature_names)
wine_df["WineType"] = wine.target
wine_df.head()
2. XGBoost Estimators at High-Level (High-Level API)¶
Below, we have listed important estimators provided by XGBoost to perform classification and regression tasks.
- Booster - It's a universal estimator which can handle both classification and regression datasets with settings. We can create it by calling train() function of XGBoost library.
- XGBRegressor - It is an estimator with scikit-learn like API designed to work with regression datasets.
- XGBClassifier - It is an estimator with scikit-learn like API designed to work with classification datasets.
- XGBRFRegressor - It is an estimator with scikit-learn like API and random forest implementation designed to work with regression datasets.
- XGBRFClassifier - It is an estimator with scikit-learn like API and random forest implementation designed to work with classification datasets.
We'll now explain estimators one by one with examples.
3. Core API: Booster Estimator ¶
As a part of this section, we'll explain the core API of xgboost which will have an explanation for different machine learning estimators available with the library. We'll even explain the parameters of these estimators as well as important attributes and methods available through them.
3.1 Booster: Regression Example ¶
We'll start with the creation of a simple estimator for the regression task of predicting prices of houses in Boston. We'll explain how we can use API to create an estimator with default parameters which will just work fine. We'll then explain various parameters available for different purposes.
3.1.1 Divide Data into Train and Test Sets¶
We'll first divide Boston dataset into train (90%) and test (10%) datasets using sklearn's function train_test_split().
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
X_train.shape, X_test.shape, Y_train.shape, Y_test.shape
3.1.2 DMatrix: XGBoost Data Structure to Represent Data¶
Xgboost default API only accepts a dataset that is wrapped in DMatrix. DMatrix is an internal data structure of xgboost that wraps data features and labels both into it. It's designed to be efficient and fastens the training process.
We can create a DMatrix instance by setting a list of the below parameters. Only the data parameter is required and all others are optional.
- data - This parameter accepts one of the below as input which has values for data features.
- pandas dataframe
- numpy array
- scipy sparse matrix
- path to libsvm format text file
- libsvm format text
- label - It accepts a numpy array of pandas data frame containing labels of the dataset.
- missing - It accepts float value in the dataset which should be treated as a missing value. The default is "None" meaning that "np.nan" is considered missing.
- feature_names - It accepts a list of string specifying feature names of data.
- feature_types - It accepts a list of string specifying feature data types.
- nthread - It accepts integer specifying the number of threads to use when loading data. The value of -1 uses all available threads on the system.
Below we have created train DMatrix and test DMatrix using numpy arrays of features data and labels. We have also passed feature names to the constructor.
dmat_train = xgb.DMatrix(X_train, Y_train, feature_names=boston.feature_names)
dmat_test = xgb.DMatrix(X_test, Y_test, feature_names=boston.feature_names)
dmat_train, dmat_test
3.1.3 "train()": Train Model¶
The simplest way of creating a booster using xgboost is by calling the train() method of xgboost. The train() method returns an instance of class xgboost.core.Booster after training is completed. We need to pass parameters for boosting algorithm as a dictionary to train method.
Below we have given a list of important parameters of the train() method. Only params and dtrain are required and all other parameters are optional and have default values set to them.
- params - It accepts a dictionary of gradient boosting algorithm parameters. We can give it an even empty dictionary and it'll take the default value for all parameters. By default, it'll consider the task to be a regression task and will calculate RMSE loss. We need to specify at least an objective function if we want it to consider a classification task for the data.
- dtrain - It accepts DMatrix instances of train data.
- num_boost_round - It accepts integer specifying the number of rounds of the training process. The algorithm will iterate over whole training data many times.
- evals - We can provide a list of tuples specifying datasets to be used for evaluation when performing training. We have passed our train and test datasets as evaluation sets hence RMSE for each will be printed after all iterations.
- obj - We can give customized objective function which will be maximized/minimized when training algorithm.
- feval - We can give a customized evaluation function that will be used to evaluate datasets given to evals.
- maximize - It accepts a boolean specifying whether to maximize or minimize our objective/loss function.
- early_stopping_rounds - It accepts an integer that instructs the algorithm to stop training if the last eval set in the list has not improved for that many rounds. If the objective/loss of the last eval dataset has not improved for that many consecutive rounds of training then the training process will stop. This parameter requires us to provide an evals parameter for it to work.
- evals_result - We can provide an empty dictionary to this parameter and it'll store evaluation results in it.
- verbose_eval - It accepts bool or integer specifying whether to print evaluation results. The integer value greater than 0 will print evaluation results at every that many iterations.
- callbacks - It accepts a list of callbacks that are applied at the end of each iteration of the training process.
Below we have called the train() method of xgboost by passing it a few parameters for boosting algorithm, train data for training, and evaluation set of training and test dataset on which evaluation after each iteration will happen.
booster = xgb.train({'max_depth': 3, 'eta': 1, 'objective': 'reg:squarederror'},
dmat_train,
evals=[(dmat_train, "train"), (dmat_test, "test")])
booster
3.1.4 "predict()": Make Predictions¶
We can use the predict() method of booster instance to predict labels for data passed to it. The predict() method requires us to pass the DMatrix instance only.
The predict method provides a list of the below important parameters that can be useful in different situations.
- data - It accepts DMatrix of feature values.
- ntree_limit - It accepts an integer specifying the number of trees to use from the total tree to make a prediction. The default is 0 which means to use all trees.
- pred_leaf - It accepts boolean which is set to True returns array of size n_samples x n_trees where each entry is an index of leaf in a tree which was used for prediction. The entry (0,1) refers to an index of leaf for the 2nd tree which was used to make a prediction for the first sample. The default is False.
- pred_contribs - It accepts boolean which if set to True returns an array of size n_sample x n_features+1 where each entry specifies contributions of features in making a final prediction for that sample. It's referred to as SHAP values. If we add all values for a particular sample then we can get the actual prediction. The default is False.
- pred_interactions - It accepts boolean which if set to True returns array of size n_sample x n_features+1 xn_features+1 indicating features SHAP interaction values for each sample.
Below we have created a data frame showing the first 10 actual test labels and 10 predicted labels for test data.
pd.DataFrame({ "Actuals":Y_test[:10], "Prediction":booster.predict(dmat_test)[:10]})
Below we have retrieved shap values for our test samples. We have even summed up shap values for each sample to calculate the final prediction which is the same as the actual prediction printed above.
If you are interested in learning about the SHAP python library which provides various methods for calculating SHAP values and different types of plots to interpret them then please feel free to check our tutorial on the same.
shap_values = booster.predict(dmat_test, pred_contribs=True)
print("SHAP Values Size : ", shap_values.shape)
print("\nSample SHAP Values : ",shap_values[0])
print("\nSumming SHAP Values for Prediction : ",shap_values.sum(axis=1)[:5]) # First 5 preds are only printed
booster.predict(dmat_test, pred_leaf=True)[:5]
shap_interactions = booster.predict(dmat_test, pred_interactions=True)
print("SHAP Interactions Size : ", shap_interactions.shape)
3.1.5 Evaluate Model Performance¶
We can explicitly evaluate the dataset using a trained booster instance with the help of the eval() method. It'll evaluate the dataset and return an objective function value for it. below we are using the eval() method on the train and test DMatrix to get RMSE for both.
print("Train RMSE : ",booster.eval(dmat_train))
print("Test RMSE : ",booster.eval(dmat_test))
Below we have evaluated the R2 score for train and test datasets using the r2_score() function of sklearn. We have then evaluated the R2 score based on using only 5 trees from the ensemble rather than using all trees.
Scikit-learn provides many commonly used machine learning metrics for evaluating model performance on regression, classification, and clustering tasks. Please feel free to check below link if you want to learn about them.
from sklearn.metrics import r2_score
print("Test R2 Score : %.2f"%r2_score(Y_test, booster.predict(dmat_test)))
print("Train R2 Score : %.2f"%r2_score(Y_train, booster.predict(dmat_train)))
print("Number of Trees in Ensemble : ",booster.best_ntree_limit)
print("\nTest R2 Score : %.2f"%r2_score(Y_test, booster.predict(dmat_test, ntree_limit=5)))
print("Train R2 Score : %.2f"%r2_score(Y_train, booster.predict(dmat_train, ntree_limit=5)))
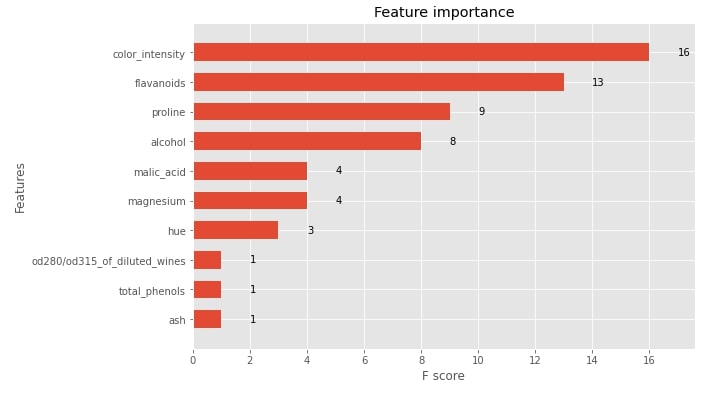
3.1.6 Visualize Features Importances using "plot_importance()"¶
The xgboost provides functionality that lets us print feature importance. We need to pass our booster instance to the method and it'll plot feature importance bar chart using matplotlib. The plot_importance() method has an important parameter named importance_type which accepts one of the below-mentioned 3 string values to plot feature importance in three different ways.
- weight - It plots the number of times a feature appears in a tree. This is the default value.
- gain - It plots the average gain of splits that uses the feature.
- cover - It plots the average coverage of splits for each feature.
with plt.style.context("ggplot"):
fig = plt.figure(figsize=(9,6))
ax = fig.add_subplot(111)
xgb.plotting.plot_importance(booster, ax=ax, height=0.6, importance_type="weight")
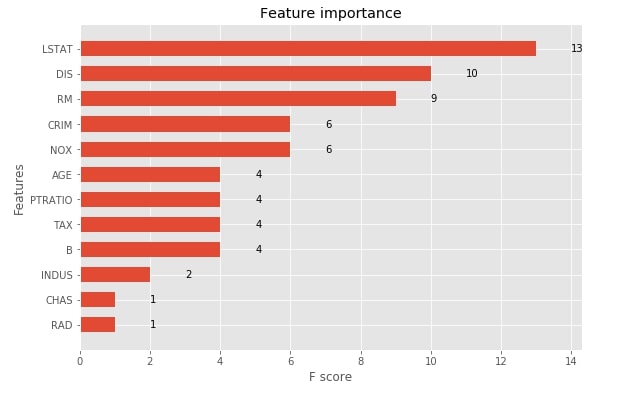
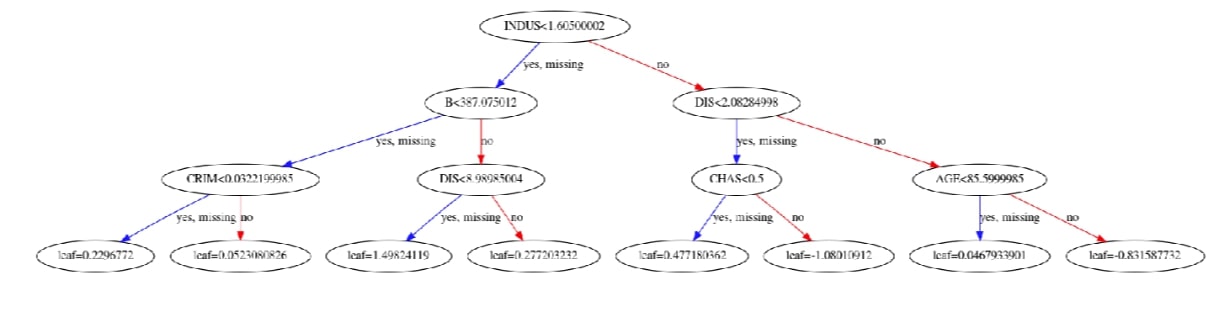
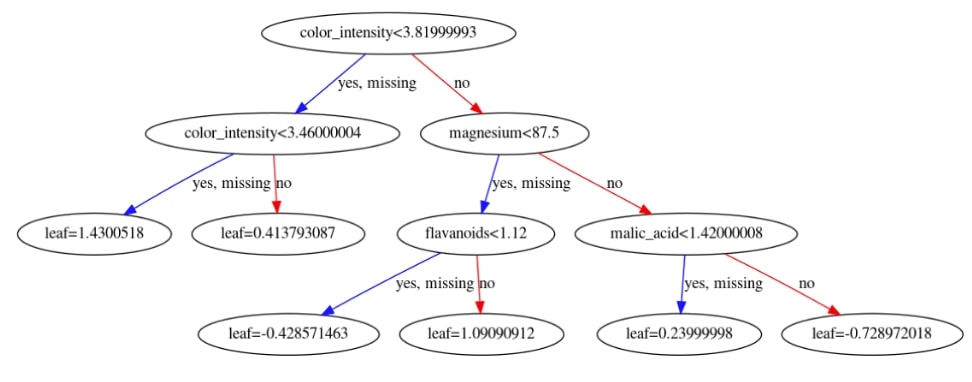
Visualize Individual Boosted Tree using "plot_tree()"¶
Xgboost also lets us plot the individual trees in the ensemble of trees using the plot_tree() method. It accepts booster instance and index of a tree which we want to plot. Below we have plotted the 10th tree of an ensemble. Please make a note that indexing starts at 0.
with plt.style.context("ggplot"):
fig = plt.figure(figsize=(25,10))
ax = fig.add_subplot(111)
xgb.plotting.plot_tree(booster, ax=ax, num_trees=9)
Visualize Feature Values Split Histogram using "get_split_value_histogram()"¶
The get_split_value_histogram() method returns histogram of splits for feature values. Below we have created split values histogram for feature LSTAT of data. It gives us value and how many times a split has happened at that value.
booster.get_split_value_histogram("LSTAT")
Convert Trees to Dataframe using "trees_to_dataframe()"¶
The trees_to_dataframe() method will dump information on trees used in an ensemble as a pandas dataframe. It'll have information on each tree-like individual node ids, feature name, and its values used for a split at each node, gain at each node, cover at each node, etc.
booster.trees_to_dataframe()
3.2 Important Parameters of Boosting (train()) ¶
NOTE: Please feel free to skip this section if you are in hurry. It is a theoretical section listing parameters of "train()" function. You can refer to them later as you need to tweak model.
Below we have given a list of important parameters of the boosting algorithm which we can pass as a dictionary to the params parameter of "train()" function as well as other XGBoost models (XGBRegressor, XGBClassifier, etc) explained below.
- booster - It specifies which gradient boosting algorithm to use for training. Below is a list of possible options.
- gbtree - It’s a tree-based algorithm. Default.
- gblinear - It’s a linear function based algorithm.
- dart - It’s a tree-based algorithm.
- eta - It accepts float [0,1] specifying learning rate for training process. Default = 0.3
tree_method - It accepts string specifying tree construction algorithm. Below is a list of possible options.
- auto - It automatically decides the algorithm based on dataset size. For the small datasets, it uses exact and for larger datasets approx.
- exact - It specifies the exact greedy algorithm. It tries all possible splits to create trees.
- approx - It’s an approximate greedy algorithm that uses quantile sketch and gradient histogram.
- hist - It’s an approximate greedy algorithm optimized using a faster histogram.
- gpu_hist - Its a GPU implementation of hist.
max_depth - It accepts an integer specifying the maximum depth of the tree. The default is 6.
- gamma - It accepts float specifying minimum loss required to make a further partition on a particular node of the tree during training. The default is 0.
- subsample - It accepts float in the range (0,1] specifying sub-sample ratio of training samples. The value of 0.5 will result in taking half of the sample randomly before training starts which can help prevent overfitting.
sampling_method - This parameter accepts one of the below string as a sampling method to draw sub-samples.
- uniform - Default
- gradient_based
lambda - It accepts float specifying L2 regularization term on weights. The default is 1.
- alpha - It accepts float specifying L1 regularization term on weights. The default is 0.
- max_bin - It accepts an integer specifying the number of bins to bucket continuous features. The default is 256. The more value improves split quality at the expense of more computation time.
- monotone_constraints - It accepts tuple of integers of length n_features. Each entry in tuple has a value of either 1,0 or -1 specifying increasing, none, or decreasing monotone relation of a feature with the target. It only works with tree_method set to one of the exact, hist or gpu_hist.
- interaction_constraints - It accepts a list of the list each individual list represents indexes of features that are allowed to interact when creating a tree to make the final prediction. If we don't provide this constraint then all features are allowed to interact with one another. We can restrict feature interaction using this parameter.
- tweedie_variance_power - It accepts float in the range (1,2) that controls variance of Tweedie distribution. The default value is 1.5.
objective - It accepts string specifying objective/loss function to use for training. The default value is reg:squarederror. Below are some of the commonly used values. Please visit this link to check a list of all objective functions available.
- reg:squarederror
- reg:squaredlogerror
- reg:logistic - Logistic Regression
- binary:logistic - Logistic Regression for Binary Classification. Outputs probability.
- multi:softmax - Multi-Class classification using softmax function.
- multi:softprob - It’s the same as softmax but outputs probability.
- reg:tweedie - It’s tweedie regression with log-link.
eval_metric - It accepts string value specifying metric which will be used to evaluate evaluation sets passed to evals parameter. Below is a list of commonly used values. Please visit this link to check a list of all evaluation metrics available.
- rmse - Root Mean Squared Error
- rmsle - Root Mean Squared Log Error
- mae - Mean Absolute Error
- logloss - Negative Log-likelihood
- auc - Area Under Curve ROC
- error - Binary Classification error rate (no_wrong_preds/total_samples).
- num_class - It's an integer specifying number of class for multi-class classification problem. We need to provide this when the objective is set to multi:softmax or multi:softprob.
- nthread - It specifies the number of threads to use to run xgboost.
- verbosity - It accepts one of the below integers for printing messages during training.
- 0 - Silent
- 1 - Warning
- 2 - Info
- 3 - Debug
Please make a NOTE that this is not a list of all parameters for estimator but a list of important parameters that are commonly tuned by practitioners. Please visit the below link to know about all possible parameters available with xgboost.
3.3 Booster: Tweedie Regression Example ¶
NOTE: Please feel free to skip this section if you are in hurry and have understood how to perform regression from previous section. It is explaining usage of different objective/loss function.
Below we have explained an example of how we can use tweedie regression on Boston housing data. We have trained the model using tweedie regression and then evaluated RMSE and R2 scores on both train and test datasets.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
dmat_train = xgb.DMatrix(X_train, Y_train, feature_names=boston.feature_names)
dmat_test = xgb.DMatrix(X_test, Y_test, feature_names=boston.feature_names)
tweedie_booster = xgb.train({'max_depth': 3, 'eta': 1, 'objective': 'reg:tweedie', 'tree_method':'hist', 'nthread':4},
dmat_train,
evals=[(dmat_train, "train"), (dmat_test, "test")])
print("\nTrain RMSE : ",tweedie_booster.eval(dmat_train))
print("Test RMSE : ",tweedie_booster.eval(dmat_test))
from sklearn.metrics import r2_score
print("\nTest R2 Score : %.2f"%r2_score(Y_test, tweedie_booster.predict(dmat_test)))
print("Train R2 Score : %.2f"%r2_score(Y_train, tweedie_booster.predict(dmat_train)))
3.4 Booster: Binary Classification Example ¶
As a part of this section, we have explained how we can use the train() method to train booster for the binary classification task of classifying breast cancer tumor types. Please make a note that we have used binary:logistic as our objective function hence the output of the predict() method of the booster will be a probability. We have included logic to convert probabilities into class. We have then calculated accuracy, confusion matrix, and classification report for test data.
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target, train_size=0.90, stratify=breast_cancer.target, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
dmat_train = xgb.DMatrix(X_train, Y_train, feature_names=breast_cancer.feature_names)
dmat_test = xgb.DMatrix(X_test, Y_test, feature_names=breast_cancer.feature_names)
booster = xgb.train({'max_depth': 2, 'eta': 1, 'objective': 'binary:logistic'},
dmat_train,
evals=[(dmat_train, "train"), (dmat_test, "test")])
print("\nTrain RMSE : ",booster.eval(dmat_train))
print("Test RMSE : ",booster.eval(dmat_test))
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
train_preds = [1 if pred>0.5 else 0 for pred in booster.predict(data=dmat_train)]
test_preds = [1 if pred>0.5 else 0 for pred in booster.predict(data=dmat_test)]
print("\nTest Accuracy : %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy : %.2f"%accuracy_score(Y_train, train_preds))
print("\nConfusion Matrix : ")
print(confusion_matrix(Y_test, test_preds))
print("\nClassification Report : ")
print(classification_report(Y_test, test_preds))
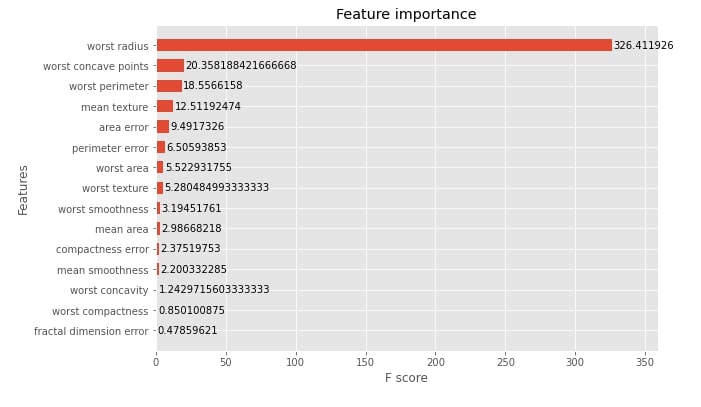
Below we have plotted feature importance for booster trained on breast cancer dataset. We have plotted the average gain of splits that uses the feature. Please feel free to look at the data frame retrieved using the trees_to_dataframe() method.
with plt.style.context("ggplot"):
fig = plt.figure(figsize=(9,6))
ax = fig.add_subplot(111)
xgb.plotting.plot_importance(booster, ax=ax, height=0.6, importance_type="gain")
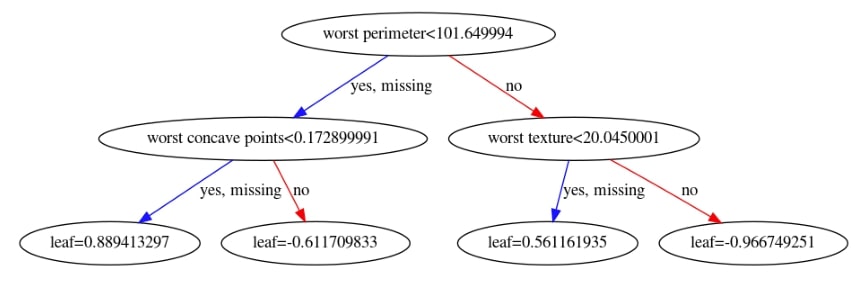
We have now plotted 3rd tree from the ensemble below.
with plt.style.context("ggplot"):
fig = plt.figure(figsize=(15,10))
ax = fig.add_subplot(111)
xgb.plotting.plot_tree(booster, ax=ax, num_trees=2)
3.5 Booster: Multi-Class Classification Example ¶
NOTE: Please feel free to skip this section if you are in hurry and have understood how to perform classification from previous binary classification section.
As a part of this section, we have explained how we can use the train() method for multi-class classification problems. We have used it to generate booster trained on wine classification train dataset. We have then evaluated the accuracy, confusion matrix, and classification report on the test dataset.
We have then plotted the feature importance bar chart and first decision tree.
X_train, X_test, Y_train, Y_test = train_test_split(wine.data, wine.target, train_size=0.80, stratify=wine.target, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
dmat_train = xgb.DMatrix(X_train, Y_train, feature_names=wine.feature_names)
dmat_test = xgb.DMatrix(X_test, Y_test, feature_names=wine.feature_names)
booster = xgb.train({'max_depth': 5, 'eta': 1, 'objective': 'multi:softmax', 'num_class':3},
dmat_train,
evals=[(dmat_train, "train"), (dmat_test, "test")])
print("\nTrain RMSE : ",booster.eval(dmat_train))
print("Test RMSE : ",booster.eval(dmat_test))
from sklearn.metrics import accuracy_score
print("\nTest Accuracy : %.2f"%accuracy_score(Y_test, booster.predict(data=dmat_test)))
print("Train Accuracy : %.2f"%accuracy_score(Y_train, booster.predict(data=dmat_train)))
print("\nConfusion Matrix : ")
print(confusion_matrix(Y_test, booster.predict(data=dmat_test)))
print("\nClassification Report : ")
print(classification_report(Y_test, booster.predict(data=dmat_test)))
with plt.style.context("ggplot"):
fig = plt.figure(figsize=(9,6))
ax = fig.add_subplot(111)
xgb.plotting.plot_importance(booster, ax=ax, height=0.6, importance_type="weight")
with plt.style.context("ggplot"):
fig = plt.figure(figsize=(20,10))
ax = fig.add_subplot(111)
xgb.plotting.plot_tree(booster, ax=ax, num_trees=1)
3.6 Saving and Loading Trained Model ¶
As a part of this section, we have explained how we can save the trained xgboost model to disk and then load it to make predictions again in the future.
Below is a list of available methods that can be used to save the model in a different format.
- save_model(file_name) - It saves model in xgboost internal format.
- save_config() - It outputs booster configuration as JSON string which can be saved to json file. We can load the booster later using the same parameter configuration using this file.
- save_raw() - It returns the byte array object which is the current memory representation of a booster instance.
Below is a list of available methods that can be used to load the saved model.
- load_model(file_name) - It accepts file name or byte array from which trained model can be loaded.
- load_config() - It accepts JSON string generated by save_config() to load model with same configuration.
Below we have saved our multi-class classification model which we created in the previous example. We have then reloaded the model and made predictions using it for verification.
booster.save_model("multiclass_classification.model")
loaded_booster = xgb.Booster()
loaded_booster
loaded_booster.load_model("multiclass_classification.model")
pd.DataFrame({"Preds":booster.predict(dmat_test)[:5], "Loaded Model Preds":loaded_booster.predict(dmat_test)[:5]})
We can even load the model by using the Booster() class giving it the file name as a part of the model_file parameter.
loaded_booster1 = xgb.Booster(model_file="multiclass_classification.model")
pd.DataFrame({"Preds":booster.predict(dmat_test)[:5], "Loaded Model Preds":loaded_booster1.predict(dmat_test)[:5]})
3.7 Cross Validation ¶
Xgboost lets us perform cross-validation on our dataset as well using the cv() method. The cv() method has almost the same parameters as that of the train() method with few extra parameters as mentioned below.
- nfold - It accepts an integer specifying the number of folds to create from the dataset. The default is 3.
- folds - It accepts sklearn KFold, StratifiedKFold, ShuffleSplitor StratifiedShuffleSplit instance.
- metrics - It accepts list of metrics to evaluate.
Below we have performed cross-validation on the full Boston dataset for 10 rounds and 5 folds.
dmat_train = xgb.DMatrix(boston.data, boston.target, feature_names=boston.feature_names)
xgb.cv({'max_depth': 5, 'eta': 1, 'objective': 'reg:squarederror'}, dmat_train, num_boost_round=10, nfold=5)
Below we have again performed cross-validation on the Boston dataset but this time we have passed sklearn ShufflSplit for creating folds. It creates 10 fold of randomly shuffled data.
from sklearn.model_selection import KFold, ShuffleSplit
shuffle_split = ShuffleSplit(random_state=123)
dmat_train = xgb.DMatrix(boston.data, boston.target, feature_names=boston.feature_names)
xgb.cv({'max_depth': 5, 'eta': 1, 'objective': 'reg:squaredlogerror'}, dmat_train, folds=shuffle_split)
Below we have performed cross-validation on the breast cancer dataset. We have informed the cv() method to evaluate log loss, AUC, and error metrics for each iteration.
dmat_train = xgb.DMatrix(breast_cancer.data,
breast_cancer.target,
feature_names=breast_cancer.feature_names)
xgb.cv({'max_depth': 3, 'eta': 1, 'objective': 'binary:logitraw'},
dmat_train, stratified=breast_cancer.target, nfold=5, metrics=["auc", "logloss", "error"])
4. Sklearn Like API ¶
Xgboost provides estimators that have almost the same API like that of sklearn estimators. This helps developers with sklearn background to grasp the usage of xgboost faster. It even lets us use the xgboost model with sklearn's grid search functionality. As a part of this section, we'll explain 4 estimators available from xgboost which has the same API as sklearn's estimators.
- XGBRegressor
- XGBClassifier
- XGBRFRegressor
- XGBRFClassifier
4.1 XGBRegressor ¶
The XGBRegressor is an estimator that is used for regression problems. It has a default objective function as reg:squarederror. It has a list of parameters that we gave as a dictionary to the train() method. We pass those parameters to the constructor of XGBRegressor directly.
4.1.1 Train Model, Make Predictions & Evaluate Model Performance¶
Below we have trained XGBRegressor on Boston train data and then calculated R2 score on test and train dataset both. The score() method is available as a part of estimators which has sklearn like API. The score() method will return the R2 score for regression tasks and accuracy for classification tasks.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
xgb_regressor = xgb.XGBRegressor()
xgb_regressor.fit(X_train, Y_train, eval_set=[(X_test, Y_test)], eval_metric="mae", verbose=10)
print("Test R2 Score : %.2f"%xgb_regressor.score(X_test, Y_test))
print("Train R2 Score : %.2f"%xgb_regressor.score(X_train, Y_train))
xgb_regressor.predict(X_test)[:5]
Below we have printed the number of estimators which model used by default, max depth of each tree, and feature importance of individual features.
print("Default Number of Estimators : ",xgb_regressor.n_estimators)
print("Default Max Depth of Trees : ", xgb_regressor.max_depth)
print("Feature Importances : ")
pd.DataFrame([xgb_regressor.feature_importances_], columns=boston.feature_names)
4.1.2 Hyperparameters Tuning using Grid Search¶
We have now explained how we perform a grid search with XGBRegressor. We have tried different values of parameters n_estimators, max_depth, and eta to find the best performing values. We have then plotted grid search results as well.
%%time
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators': [50,100],
'max_depth': [None, 3, 5, 7, 9],
'eta': [0.5, 1, 2, 3]
}
grid_search = GridSearchCV(xgb.XGBRegressor(), params, n_jobs=-1)
grid_search.fit(X_train, Y_train)
print("Test R2 Score : %.2f"%grid_search.score(X_test, Y_test))
print("Train R2 Score : %.2f"%grid_search.score(X_train, Y_train))
print("Best Params : ", grid_search.best_params_)
print("Feature Importances : ")
pd.DataFrame([grid_search.best_estimator_.feature_importances_], columns=boston.feature_names)
grid_search_results = pd.DataFrame(grid_search.cv_results_)
print("Grid Search Size : ", grid_search_results.shape)
grid_search_results.head()
xgb_regressor.get_booster() ## We can get Booster object using this method from sklearn estimators
4.2 XGBClassifier ¶
The XGBClassifier is an estimator that is used for classification tasks. It has the default objective function binary:logistic. We can pass the same parameters which we can pass to the train() method's params parameter as a dictionary to the constructor of XGBClassifier. We can get actual predictions using predict() method and probabilities using predict_proba() method. It even provides a score() method which lets us calculate the accuracy of the model on given data.
4.2.1 Train Model, Make Predictions & Evaluate Model Performance¶
Below we have trained XGBClassifier on the breast cancer train dataset. We have then evaluated accuracy on train and test datasets. We have also printed the first few predictions and probabilities.
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target,
stratify=breast_cancer.target,
train_size=0.90, random_state=42)
xgb_classif = xgb.XGBClassifier()
xgb_classif.fit(X_train, Y_train, eval_set=[(X_test, Y_test)], eval_metric="auc" , verbose=10)
print("Test Accuracy Score : %.2f"%xgb_classif.score(X_test, Y_test))
print("Train Accuracy Score : %.2f"%xgb_classif.score(X_train, Y_train))
xgb_classif.predict(X_test)[:5]
print("Probabilities : ")
print(xgb_classif.predict_proba(X_test)[:5])
print("\nPrediction From Probabilities : ")
print(np.argmax(xgb_classif.predict_proba(X_test)[:5], axis=1))
print("Default Number of Estimators : ",xgb_classif.n_estimators)
print("Default Max Depth of Trees : ", xgb_classif.max_depth)
print("Feature Importances : ")
pd.DataFrame([xgb_classif.feature_importances_], columns=breast_cancer.feature_names)
4.2.2 Hyperparameters Tuning using Grid Search¶
Below we have explained how we can use XGBClassifier with sklearn's grid search functionality to try a list of parameters to find the best parameter settings.
%%time
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators': [50,100,150,200,300,500],
'max_depth': [None, 3, 5, 7, 9],
'eta': [0.5, 1, 2, 3]
}
grid_search = GridSearchCV(xgb.XGBClassifier(), params, n_jobs=-1, cv=5)
grid_search.fit(X_train, Y_train)
print("Test Accuracy Score : %.2f"%grid_search.score(X_test, Y_test))
print("Train Accuracy Score : %.2f"%grid_search.score(X_train, Y_train))
print("Best Params : ", grid_search.best_params_)
print("Feature Importances : ")
pd.DataFrame([grid_search.best_estimator_.feature_importances_], columns=breast_cancer.feature_names)
4.3 XGBRFRegressor ¶
4.3.1 Train Model, Make Predictions & Evaluate Model Performance¶
The XGBRFRegressor is a random forest implementation based on decision trees for regression tasks. It has almost exactly the same API as that of XGBRegressor. We have explained below the usage of it on the Boston housing dataset.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
xgb_rf_regressor = xgb.XGBRFRegressor()
xgb_rf_regressor.fit(X_train, Y_train)
print("Test R2 Score : %.2f"%xgb_rf_regressor.score(X_test, Y_test))
print("Train R2 Score : %.2f"%xgb_rf_regressor.score(X_train, Y_train))
print("Default Number of Estimators : ",xgb_rf_regressor.n_estimators)
print("Default Max Depth of Trees : ", xgb_rf_regressor.max_depth)
print("Feature Importances : ")
pd.DataFrame([xgb_rf_regressor.feature_importances_], columns=boston.feature_names)
4.3.2 Hyperparameters Tuning using Grid Search¶
%%time
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators': [50,100,150,200,300,500],
'max_depth': [None, 3, 5, 7, 9],
'eta': [0.5, 1, 2, 3]
}
grid_search = GridSearchCV(xgb.XGBRFRegressor(), params, n_jobs=-1, cv=5)
grid_search.fit(X_train, Y_train)
print("Test R2 Score : %.2f"%grid_search.score(X_test, Y_test))
print("Train R2 Score : %.2f"%grid_search.score(X_train, Y_train))
print("Best Params : ", grid_search.best_params_)
print("Feature Importances : ")
pd.DataFrame([grid_search.best_estimator_.feature_importances_], columns=boston.feature_names)
4.4 XGBRFClassifier ¶
4.4.1 Train Model, Make Predictions & Evaluate Model Performance¶
The XGBRFClassifier is a random forest implementation based on decision trees for classification tasks. It has almost exactly the same API as that of XGBClassifier. We have explained below the usage of it on the breast cancer dataset.
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target,
stratify=breast_cancer.target,
train_size=0.90, random_state=42)
xgb_rf_classif = xgb.XGBRFClassifier()
xgb_rf_classif.fit(X_train, Y_train)
print("Test Accuracy Score : %.2f"%xgb_rf_classif.score(X_test, Y_test))
print("Train Accuracy Score : %.2f"%xgb_rf_classif.score(X_train, Y_train))
print("Default Number of Estimators : ",xgb_rf_classif.n_estimators)
print("Default Max Depth of Trees : ", xgb_rf_classif.max_depth)
print("Feature Importances : ")
pd.DataFrame([xgb_rf_classif.feature_importances_], columns=breast_cancer.feature_names)
4.4.2 Hyperparameters Tuning using Grid Search¶
%%time
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators': [50,100,150,200,300,500],
'max_depth': [None, 3, 5, 7, 9],
'eta': [0.5, 1, 2, 3]
}
grid_search = GridSearchCV(xgb.XGBRFClassifier(), params, n_jobs=-1, cv=5)
grid_search.fit(X_train, Y_train)
print("Test Accuracy Score : %.2f"%grid_search.score(X_test, Y_test))
print("Train Accuracy Score : %.2f"%grid_search.score(X_train, Y_train))
print("Best Params : ", grid_search.best_params_)
print("Feature Importances : ")
pd.DataFrame([grid_search.best_estimator_.feature_importances_], columns=breast_cancer.feature_names)
5. Early Stop Training to Avoid Overfitting ¶
Xgboost provides us with an option that lets us stop the training process if training loss is not improving for some specified number of iterations. We can specify the early_stopping_rounds parameter in the train() method to some integer and it'll stop training if training loss is not improved for that many rounds of training.
Below we have instructed train() method to train for 20 rounds using num_boost_round parameter and early_stopping_rounds is set to 5. The train() method will stop training if training loss is not improved for 5 sequential rounds of training.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
dmat_train = xgb.DMatrix(X_train, Y_train, feature_names=boston.feature_names)
dmat_test = xgb.DMatrix(X_test, Y_test, feature_names=boston.feature_names)
tweedie_booster = xgb.train({'max_depth': 3, 'eta': 1, 'objective': 'reg:tweedie'},
dmat_train,
evals=[(dmat_train, "train"), (dmat_test, "test")],
num_boost_round=20,
early_stopping_rounds=5)
print("\nTrain RMSE : ",tweedie_booster.eval(dmat_train))
print("Test RMSE : ",tweedie_booster.eval(dmat_test))
from sklearn.metrics import r2_score
print("\nTest R2 Score : %.2f"%r2_score(Y_test, tweedie_booster.predict(dmat_test)))
print("Train R2 Score : %.2f"%r2_score(Y_train, tweedie_booster.predict(dmat_train)))
We have below explained how we can early stop training with XGBRegressor.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
xgb_regressor = xgb.XGBRegressor(max_depth=3, eta=1, objective='reg:tweedie')
xgb_regressor.fit(X_train, Y_train,
eval_set=[(X_test, Y_test)], eval_metric="rmse",
early_stopping_rounds=5, verbose=5)
print("Test R2 Score : %.2f"%xgb_regressor.score(X_test, Y_test))
print("Train R2 Score : %.2f"%xgb_regressor.score(X_train, Y_train))
6. Feature Interaction Constraints ¶
When xgboost creates a tree during the training process it takes into consideration all feature interactions. In a decision tree, we have nodes where each node represents a decision to be made based on a particular value of the feature. The next node will be based on the feature value mentioned in the previous node. By default, all features can be present in any node of the decision tree. We can force xgboost to keep a list of features in subsequent nodes by giving it a list of indices of features in the dataset. We can give list of list to interaction_constraints parameter of train() method. Here an individual list is a list of feature indices that should only interact with one another and not with other features.
Please feel free to go through this link to get in-depth details about feature interaction constraints in xgboost.
Below we have kept features 0,1,2,11 and 12 into one list hence these features will interact with one another when creating a tree but not with other features hence tree will have only these features. The Same goes for other lists.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
dmat_train = xgb.DMatrix(X_train, Y_train, feature_names=boston.feature_names)
dmat_test = xgb.DMatrix(X_test, Y_test, feature_names=boston.feature_names)
tweedie_booster = xgb.train({'max_depth': 3, 'eta': 1, 'objective': 'reg:tweedie',
'tree_method':'hist', 'nthread':4,
'interaction_constraints':[[0,1,2,11,12], [3, 4],[6,10], [5,9], [7,8]]},
dmat_train,
evals=[(dmat_train, "train"), (dmat_test, "test")])
print("\nTrain RMSE : ",tweedie_booster.eval(dmat_train))
print("Test RMSE : ",tweedie_booster.eval(dmat_test))
from sklearn.metrics import r2_score
print("\nTest R2 Score : %.2f"%r2_score(Y_test, tweedie_booster.predict(dmat_test)))
print("Train R2 Score : %.2f"%r2_score(Y_train, tweedie_booster.predict(dmat_train)))
Below we have explained how we can use feature interaction constraint with XGBRegressor.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
xgb_regressor = xgb.XGBRegressor(max_depth=3, eta=1, objective='reg:tweedie',
interaction_constraints=[[0,1,2,11,12], [3, 4],[6,10], [5,9], [7,8]])
xgb_regressor.fit(X_train, Y_train,
eval_set=[(X_test, Y_test)], eval_metric="rmse",
early_stopping_rounds=5, verbose=1)
print("Test R2 Score : %.2f"%xgb_regressor.score(X_test, Y_test))
print("Train R2 Score : %.2f"%xgb_regressor.score(X_train, Y_train))
7. Monotonic Constraints ¶
The monotonic constraints let us specify increasing, decreasing, or no monotone relation of the feature with the target. We can specify a monotone value of 1,0 or -1 for each feature to show the increasing, none, and decreasing relation of the feature with the target by setting the monotone_constraints parameter. Below we have explained the usage of monotonic constraints for regression problems using the Boston dataset.
Please feel free to check this link to better understand monotonic constraints.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
dmat_train = xgb.DMatrix(X_train, Y_train, feature_names=boston.feature_names)
dmat_test = xgb.DMatrix(X_test, Y_test, feature_names=boston.feature_names)
tweedie_booster = xgb.train({'max_depth': 3, 'eta': 1, 'objective': 'reg:tweedie',
'tree_method':'hist', 'nthread':4,
'monotone_constraints':(1,0,1,-1,1,0,1,0,-1,1,1, -1, 1)},
dmat_train,
evals=[(dmat_train, "train"), (dmat_test, "test")])
print("\nTrain RMSE : ",tweedie_booster.eval(dmat_train))
print("Test RMSE : ",tweedie_booster.eval(dmat_test))
from sklearn.metrics import r2_score
print("\nTest R2 Score : %.2f"%r2_score(Y_test, tweedie_booster.predict(dmat_test)))
print("Train R2 Score : %.2f"%r2_score(Y_train, tweedie_booster.predict(dmat_train)))
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
xgb_regressor = xgb.XGBRegressor(max_depth=3, eta=1, objective='reg:tweedie',
monotone_constraints=(1,0,1,-1,1,0,1,0,-1,1,1, -1, 1))
xgb_regressor.fit(X_train, Y_train,
eval_set=[(X_test, Y_test)], eval_metric="rmse",
early_stopping_rounds=5, verbose=1)
print("Test R2 Score : %.2f"%xgb_regressor.score(X_test, Y_test))
print("Train R2 Score : %.2f"%xgb_regressor.score(X_train, Y_train))
8. Custom Objective/Loss Function ¶
As a part of this section, we have explained how we can use a custom objective/loss function with xgboost. We'll be giving input to loss function list of predicted values and actual target values. It'll then return a list of the first derivative and second derivative of loss function for that values. Below we have created the mean squared error loss function and explained its usage with a simple example. We need to pass a reference to function to the objective parameter of an estimator.
def first_grad(predt, dtrain):
'''Compute the first derivative for mean squared error.'''
y = dtrain.get_label() if isinstance(dtrain, xgb.DMatrix) else dtrain
return 2*(y-predt)
def second_grad(predt, dtrain):
'''Compute the second derivative for mean squared error.'''
y = dtrain.get_label() if isinstance(dtrain, xgb.DMatrix) else dtrain
return [1] * len(predt)
def mean_sqaured_error(predt, dtrain):
''''Mean squared error function.'''
predt[predt < -1] = -1 + 1e-6
grad = first_grad(predt, dtrain)
hess = second_grad(predt, dtrain)
return grad, hess
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
xgb_regressor = xgb.XGBRegressor(max_depth=3, eta=1, objective=mean_sqaured_error) ## Custom Evaluation Function
xgb_regressor.fit(X_train, Y_train,
eval_set=[(X_test, Y_test)], eval_metric="mae",
early_stopping_rounds=5,
verbose=10)
print("\nTest R2 Score : %.2f"%xgb_regressor.score(X_test, Y_test))
print("Train R2 Score : %.2f"%xgb_regressor.score(X_train, Y_train))
9. Custom Evaluation Functions ¶
Xgboost lets us create our custom evaluation function as well. The function should accept predictions and DMatrix instances as parameters and then calculate metrics based on predictions and actual target values. We have created simple mean_absolute_error() for explanation purpose.
We can pass function reference to the feval parameter of train() to use it on the evaluation dataset.
def mean_absolute_error(preds, dmat):
actuals = dmat.get_label()
err = (actuals - preds).sum()
return "MAE", err
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
dmat_train = xgb.DMatrix(X_train, Y_train, feature_names=boston.feature_names)
dmat_test = xgb.DMatrix(X_test, Y_test, feature_names=boston.feature_names)
booster = xgb.train({'max_depth': 3, 'eta': 1, 'objective': 'reg:squarederror'},
dmat_train,
evals=[(dmat_test, "test")],
feval=mean_absolute_error, ## Custom Evaluation Function
num_boost_round=10,
early_stopping_rounds=5)
print("\nTrain RMSE : ",booster.eval(dmat_train))
print("Test RMSE : ",booster.eval(dmat_test))
from sklearn.metrics import r2_score
print("\nTest R2 Score : %.2f"%r2_score(Y_test, booster.predict(dmat_test)))
print("Train R2 Score : %.2f"%r2_score(Y_train, booster.predict(dmat_train)))
Below we have explained how we can use custom evaluation metrics with XGBRegressor. We need to set the eval_metric parameter of the fit() method with reference to the custom evaluation function.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
xgb_regressor = xgb.XGBRegressor(max_depth=3, eta=1, objective='reg:squarederror')
xgb_regressor.fit(X_train, Y_train,
eval_set=[(X_test, Y_test)], eval_metric=mean_absolute_error,
early_stopping_rounds=5,
verbose=5)
print("Test R2 Score : %.2f"%xgb_regressor.score(X_test, Y_test))
print("Train R2 Score : %.2f"%xgb_regressor.score(X_train, Y_train))
10. Callbacks ¶
Xgboost provides us with a list of callback functions for a different purpose which gets executed after each iteration of training. Below is a list of available callbacks with xgboost as a part of the callback module.
- early_stop - It accepts integer specifying whether to stop training if evaluation metric results on last evaluation set are not improved for that many iterations.
- print_evaluation - It accepts integer values specifying how often to print evaluation results. Evaluation metric results are printed at every that many iterations as specified.
- record_evaluation - It accepts a dictionary in which evaluation results will be recorded.
- reset_learning_rate - It lets us reset the learning rate after each iteration of training. It accepts an array of size the same as the number of iterations or callback returning the new learning rate for each iteration.
We need to provide a list of callbacks to the callbacks parameter for their execution after each iteration.
Below we have explained usage of early_stop(), print_evaluation() and record_evaluation() callbacks for regression task.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
dmat_train = xgb.DMatrix(X_train, Y_train, feature_names=boston.feature_names)
dmat_test = xgb.DMatrix(X_test, Y_test, feature_names=boston.feature_names)
early_stop_execution = xgb.callback.early_stop(5)
print_eval = xgb.callback.print_evaluation(1)
eval_results = {}
eval_results_callback = xgb.callback.record_evaluation(eval_results)
tweedie_booster = xgb.train({'max_depth': 3, 'eta': 1, 'objective': 'reg:tweedie'},
dmat_train,
evals=[(dmat_test, "test")],
num_boost_round=25,
verbose_eval=False,
callbacks=[early_stop_execution, print_eval, eval_results_callback])
print("Evaluation Results : ", eval_results)
print("\nTest R2 Score : %.2f"%r2_score(Y_test, tweedie_booster.predict(dmat_test)))
print("Train R2 Score : %.2f"%r2_score(Y_train, tweedie_booster.predict(dmat_train)))
Below we have again explained the same three callbacks with XGBRegressor. This time we need to pass a list of callback functions to the callbacks parameter of the fit() method.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
xgb_regressor = xgb.XGBRegressor(max_depth=3, eta=1, objective='reg:squarederror')
early_stop_execution = xgb.callback.early_stop(5)
print_eval = xgb.callback.print_evaluation(5)
eval_results = {}
eval_results_callback = xgb.callback.record_evaluation(eval_results)
xgb_regressor.fit(X_train, Y_train,
eval_set=[(X_test, Y_test)],
verbose=False,
callbacks = [early_stop_execution, print_eval, eval_results_callback]
)
print("Evaluation Results : ", eval_results)
print("\nTest R2 Score : %.2f"%xgb_regressor.score(X_test, Y_test))
print("Train R2 Score : %.2f"%xgb_regressor.score(X_train, Y_train))
As a part of this example, we have explained how we can use the reset_learning_rate() callback. We have first called the reset_learning_rate() function with an array of size 15 which is the same as the number of iterations of our training process. The array starts from 0.1 till 1.5 increasing the learning rate by 0.1 each time.
reset_learning_rate = xgb.callback.reset_learning_rate(list(np.linspace(0.1,1.5, num=15)))
tweedie_booster = xgb.train({'max_depth': 3, 'eta': 1, 'objective': 'reg:tweedie'},
dmat_train,
evals=[(dmat_test, "test")],
num_boost_round=15,
callbacks=[reset_learning_rate])
print("\nTest R2 Score : %.2f"%r2_score(Y_test, tweedie_booster.predict(dmat_test)))
print("Train R2 Score : %.2f"%r2_score(Y_train, tweedie_booster.predict(dmat_train)))
We have now explained another example demonstrating usage of the reset_learning_rate() callback. This time we have created a function named calculate_learning_rate() which will be passed to reset_learning_rate() callback. The function takes as input two integers (current boosting round index and a total number of boosting rounds) and returns the learning rate for that boosting round. We have then passed the callback created to the callbacks parameter.
def calculate_learning_rate(boosting_round, num_boost_round):
lrs = list(np.linspace(0.1,1.5, num=num_boost_round))
return lrs[boosting_round]
reset_learning_rate = xgb.callback.reset_learning_rate(calculate_learning_rate)
tweedie_booster = xgb.train({'max_depth': 3, 'eta': 1, 'objective': 'reg:tweedie'},
dmat_train,
evals=[(dmat_test, "test")],
num_boost_round=15,
callbacks=[reset_learning_rate])
print("\nTest R2 Score : %.2f"%r2_score(Y_test, tweedie_booster.predict(dmat_test)))
print("Train R2 Score : %.2f"%r2_score(Y_train, tweedie_booster.predict(dmat_train)))
11. Dask Backend for Distributed Training Of XGBoost Models ¶
Xgboost provides support for using dask as a backend for training gradient boosting algorithm in a distributed environment. Xgboost has a module named dask which has a list of data structures and estimators for using with dask.
Dask has a simple structure where we have below mentioned three main components.
- Scheduler - Dask distributed environment has one scheduler which handles communication between clients and workers. It’s even responsible for distributing work to worker nodes.
- Clients - We can have more than one client instances which can be used to submit tasks to the scheduler.
- Workers - These are actual nodes(processes/machines) which runs task.
In order to use dask, we need to create a client that will be used to communicate with the scheduler. This tutorial is run on a single PC and not on a distributed environment with multiple nodes. When we create an instance of dask client without giving the IP address and port of scheduler, it'll create a cluster on the local machine itself. Below we have created a small cluster of 4 workers using the Client() constructor.
If you are interested in learning about dask then please feel free to check our tutorials on the same. It has information about creating a dask distributed environment as well on an actual cluster with multiple machines.
- dask.distributed - Parallel Processing in Python
- dask.delayed - Parallel Computing in Python
- dask.bag - Parallel Computing in Python
Please make a note that using xgboost on the dask distributed environment requires a little background of dask to make it work correctly.
print("Dask Installed ?", xgb.dask.DASK_INSTALLED)
client = xgb.dask.Client(n_workers=4, threads_per_worker=4)
client
xgb.dask.get_client()
Below we have divided the Boston housing dataset into the train (90%) and test (10%) sets. We have then converted the normal numpy array to the dask array using the da module of the xgboost.dask module. The da module provides access to the dask.array module. We can even use the dask.array module to create arrays and it'll work fine. The xgboost estimators are available through the xgboost.dask module accepts either the dask array or dask dataframe. The dask.dataframe module is available in xgboost as xgboost.dask.dd.
Please feel free to check below links if you are looking for some guidance on dask.array and dask.dataframe.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
X_train_d, X_test_d, Y_train_d, Y_test_d = xgb.dask.da.array(X_train), xgb.dask.da.array(X_test), xgb.dask.da.array(Y_train), xgb.dask.da.array(Y_test)
X_train_d
Below we have explained how we can run the xgboost algorithm in a dask distributed environment. The dask module has its own DaskDMatrix data structure which is almost the same as DMatrix but requires client instance as the first argument followed by data arrays containing features values and target labels.
The train() method available through the dask module requires us to pass the client instance first before the parameters dictionary. Everything else is the same as the train() method available directly. It runs training in a distributed environment and returns a dictionary with two components (Booster instance and training history). We can then call the predict() method of the dask module by giving it the client, booster instance, and DaskDMatrix dataset. It'll return a lazy instance on which we need to call compute() to evaluate it and return the actual result. We have calculated the R2 score on train and test datasets at last.
dmat_train_dask = xgb.dask.DaskDMatrix(client, X_train_d, Y_train_d, feature_names=boston.feature_names)
dmat_test_dask = xgb.dask.DaskDMatrix(client, X_test_d, Y_test_d, feature_names=boston.feature_names)
reg_booster = xgb.dask.train(client, {'max_depth': 3, 'eta': 1, 'objective': 'reg:squarederror'},
dmat_train_dask,
evals=[(dmat_train_dask, "train"), (dmat_test_dask, "test")])
print(reg_booster)
from sklearn.metrics import r2_score
test_preds = xgb.dask.predict(client, reg_booster["booster"], dmat_test_dask)
train_preds = xgb.dask.predict(client, reg_booster["booster"], dmat_train_dask)
print("\nType of Predictions : ",test_preds)
print("\nTest R2 Score : %.2f"%r2_score(Y_test, test_preds.compute()))
print("Train R2 Score : %.2f"%r2_score(Y_train, train_preds.compute()))
dmat_train = xgb.DMatrix(X_train, Y_train, feature_names=boston.feature_names)
dmat_test = xgb.DMatrix(X_test, Y_test, feature_names=boston.feature_names)
print("\nTrain RMSE : ",reg_booster["booster"].eval(dmat_train))
print("Test RMSE : ",reg_booster["booster"].eval(dmat_test))
print("\nTest R2 Score : %.2f"%r2_score(Y_test, reg_booster["booster"].predict(dmat_test)))
print("Train R2 Score : %.2f"%r2_score(Y_train, reg_booster["booster"].predict(dmat_train)))
Below we have explained how we can use the DaskXGBRegressor() estimator for regression task with the Boston housing dataset. It has the same API as that of XGBRegressor(). We have first created a client instance and then used it as context to call all other methods which will require the usage of dask distributed environment.
client = xgb.dask.Client(n_workers=4, threads_per_worker=4)
with client:
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
X_train_d, X_test_d, Y_train_d, Y_test_d = xgb.dask.da.array(X_train), xgb.dask.da.array(X_test), xgb.dask.da.array(Y_train), xgb.dask.da.array(Y_test)
xgb_dask_regressor = xgb.dask.DaskXGBRegressor()
xgb_dask_regressor.fit(X_train_d, Y_train_d)
print("Test R2 Score : %.2f"%xgb_dask_regressor.score(X_test_d, Y_test_d))
print("Train R2 Score : %.2f"%xgb_dask_regressor.score(X_train_d, Y_train_d))
As the last example of using xgboost with dask, we have explained how we can use the DaskXGBClassifier() estimator for classification tasks. The majority of things are almost the same as normal API with differences like using the client to communicate to dask cluster, wrapping data into dask data structures, and calling compute() on lazy instances to actually run a task on a cluster to get results.
client = xgb.dask.Client(n_workers=4, threads_per_worker=4)
with client:
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target, train_size=0.90,
stratify=breast_cancer.target,
random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
X_train_d, X_test_d, Y_train_d, Y_test_d = xgb.dask.da.array(X_train), xgb.dask.da.array(X_test), xgb.dask.da.array(Y_train, dtype="int64"), xgb.dask.da.array(Y_test, dtype="int64")
xgb_dask_classif = xgb.dask.DaskXGBClassifier()
xgb_dask_classif.fit(X_train_d, Y_train_d)
train_preds = xgb_dask_classif.predict(X_train_d)
test_preds = xgb_dask_classif.predict(X_test_d)
print("Test Accuracy Score : %.2f"%accuracy_score(Y_test, test_preds.compute()))
print("Train Accuracy Score : %.2f"%accuracy_score(Y_train, train_preds.compute()))
test_preds_proba = xgb_dask_classif.predict_proba(X_test_d)
print("\nType of Preds Proba Result : ",type(test_preds_proba))
test_preds_proba = test_preds_proba.compute()
test_preds_proba[:5]
12. GPU Support ¶
Xgboost provides support for running algorithms on GPU as well. It takes the addition of two simple parameters in order to instruct xgboost to shift training from CPU to GPU. The tree_method parameter has a value named gpu_hist which will let us run our same code on GPU. We can also provide GPU id by setting the gpu_id parameter if we have more than one GPU available.
Below we have run the same code from our previous example but now on GPU by setting tree_method asgpu_hist and gpu_id to 0.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
print("Train/Test Sizes : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape, "\n")
dmat_train = xgb.DMatrix(X_train, Y_train, feature_names=boston.feature_names)
dmat_test = xgb.DMatrix(X_test, Y_test, feature_names=boston.feature_names)
tweedie_booster = xgb.train({'max_depth': 3, 'eta': 1, 'objective': 'reg:tweedie',
'tree_method':'gpu_hist', 'gpu_id':0},
dmat_train,
evals=[(dmat_train, "train"), (dmat_test, "test")])
print("\nTrain RMSE : ",tweedie_booster.eval(dmat_train))
print("Test RMSE : ",tweedie_booster.eval(dmat_test))
from sklearn.metrics import r2_score
print("\nTest R2 Score : %.2f"%r2_score(Y_test, tweedie_booster.predict(dmat_test)))
print("Train R2 Score : %.2f"%r2_score(Y_train, tweedie_booster.predict(dmat_train)))
Below we have explained how we can inform XGBClassifier to run training on GPU. The same will work for XGBRegressor, XGBRFClassifier, and XGBRFRegressor as well.
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target,
stratify=breast_cancer.target,
train_size=0.90, random_state=42)
xgb_classif = xgb.XGBClassifier(tree_method="gpu_hist", gpu_id=0)
xgb_classif.fit(X_train, Y_train)
print("Test Accuracy Score : %.2f"%xgb_classif.score(X_test, Y_test))
print("Train Accuracy Score : %.2f"%xgb_classif.score(X_train, Y_train))
13. GPU & Dask Together For Parallel GPUs ¶
Xgboost lets us run our code in parallel on multi GPUs as well by using dask. We can use dask for distributed training of our dataset and we can tree_method to gpu_hist to instruct each worker of dask to run the training process on GPU. This way we can run a training process on all workers of dask where each worker will run training on GPU of its own.
This ends our small tutorial explaining an in-depth guide to the majority of API of xgboost. Please feel free to let us know your views in the comments section.
References ¶
Other Gradient Boosted Decision Trees Implementations¶
- CatBoost - An In-Depth Guide
- LightGBM - An In-Depth Guide
- Scikit-Learn - Ensemble Learning: Boosting
XGBoost Doc¶
Dask Distributed Training Framework¶
- dask.distributed - Parallel Processing in Python
- dask.delayed - Parallel Computing in Python
- dask.bag - Parallel Computing in Python
- dask.array: Guide to Work with Large Arrays in Parallel
- dask.dataframe: Simple Guide to Work with Large Tabular Datasets
Other Useful Libraries¶
 Sunny Solanki
Sunny Solanki
Sunny Solanki
Intro: Software Developer | Youtuber | Bonsai Enthusiast
About: Sunny Solanki holds a bachelor's degree in Information Technology (2006-2010) from L.D. College of Engineering. Post completion of his graduation, he has 8.5+ years of experience (2011-2019) in the IT Industry (TCS). His IT experience involves working on Python & Java Projects with US/Canada banking clients. Since 2020, he’s primarily concentrating on growing CoderzColumn.
His main areas of interest are AI, Machine Learning, Data Visualization, and Concurrent Programming. He has good hands-on with Python and its ecosystem libraries.
Apart from his tech life, he prefers reading biographies and autobiographies. And yes, he spends his leisure time taking care of his plants and a few pre-Bonsai trees.
Contact: sunny.2309@yahoo.in



![YouTube Subscribe]() Comfortable Learning through Video Tutorials?
Comfortable Learning through Video Tutorials?
If you are more comfortable learning through video tutorials then we would recommend that you subscribe to our YouTube channel.
![Need Help]() Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
 Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?When going through coding examples, it's quite common to have doubts and errors.
If you have doubts about some code examples or are stuck somewhere when trying our code, send us an email at coderzcolumn07@gmail.com. We'll help you or point you in the direction where you can find a solution to your problem.
You can even send us a mail if you are trying something new and need guidance regarding coding. We'll try to respond as soon as possible.
![Share Views]() Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?
 Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?If you want to
- provide some suggestions on topic
- share your views
- include some details in tutorial
- suggest some new topics on which we should create tutorials/blogs
 xgboost
xgboost