Keras: RNNs (LSTM) for Time Series Data (Regression Tasks)¶
Time Series is a type of data where we capture one or more data variables at specified time intervals. The data is indexed by date, time, or date-time. The most common example of time-series datasets are stock prices every second/minute/hour/day, temperature captured every minute/hour/day, etc. This extra time component is referred to as a temporal component. For time-series data, the order of data is very important and we can not shuffle time-series dataset examples as we do with other tasks. The time-series dataset can be univariate or multi-variate. When working with time-series datasets to make predictions at a particular time, the best available data features will be a single example measured at a previous timestamp or multiple examples measured earlier. It is generally the hyperparameter of the network that we need to find out how many previous examples should be used by the network to make predictions of the current example. Time-series datasets have an inner sequence that we need to capture and research has proven that Recurrent Neural Networks are quite good at capturing sequences. They can easily capture univariate or multi-variate sequences.
As a part of this tutorial, we have explained how to create Recurrent Neural Networks (RNNs) consisting of LSTM Layers using Python Deep Learning library Keras that can be used to solve time-series regression tasks involving multi-variate dataset. The tutorial uses Tetouan City Power Consumption dataset available from UCI ML Datasets Repository. The dataset has variables like temperature, humidity, wind speed, diffuse flows, power consumption, etc measured every 10 minutes. We'll train the network to predict power consumption for the future. It'll be a regression task as we are predicting continuous variable. We have also explained how we should organize data for RNNs. After completion of network training and performance evaluation, we have also given a few suggestions on what can be tried further to improve network performance.
Below, we have listed important sections of the Tutorial to give an overview of the material covered.
Important Sections Of Tutorial¶
- Prepare Data
- 1.1 Download Data
- 1.2 Load Data
- 1.3 Organize Data
- 1.4 Scale Target Values
- Define Network
- Compile and Train Network
- Evaluate Network Performance
- Visualize Predictions
- Further Suggestions
Below, we have imported the necessary Python libraries and printed the versions of them that we have used in our tutorial.
from tensorflow import keras
print("Keras Version : {}".format(keras.__version__))
1. Prepare Data ¶
In this section, we have followed step by step process to prepare data for our time series regression task. We are following the below steps to prepare data for our LSTM network.
- Download Data
- Load Data into memory.
- Organize data by moving the window of size 30. We'll be looking back the 30 previous examples' data features (X) in order to make a prediction of the current target value (Y).
- Scale target values to bring them in the same range as data features for faster convergence.
The steps will become clear as we implement them one by one next.
1.1 Download Data¶
In this section, we have downloaded the [Tetouan City Power Consumption] dataset (available from UCI ML Repository) that we are going to use for our regression task. The dataset has power consumption information for three distribution networks of Tetouan city of Morocco. Next, we'll load it into memory to take a look at the data.
!wget https://archive.ics.uci.edu/ml/machine-learning-databases/00616/Tetuan%20City%20power%20consumption.csv
%ls
1.2 Load Data¶
In this section, we have loaded data into the main memory as Pandas dataframe using read_csv() method. The dataset has below data variables measured every 10 minutes.
- Date-time
- Temperature
- Humidity
- Wind Speed
- General diffuse flows
- Diffuse flows
- Zone 1 Power Consumption (units)
- Zone 2 Power Consumption
- Zone 3 Power Consumption
After loading data, we have set the DateTime column as an index of our dataframe. We have also displayed the first few rows of the dataset to give an idea about the contents.
For our purpose, we'll be using columns [Temperature, Humidity, Wind Speed, general diffuse flows, diffuse flows] as data features (X) and column Zone 1 Power Consumption as target column (Y).
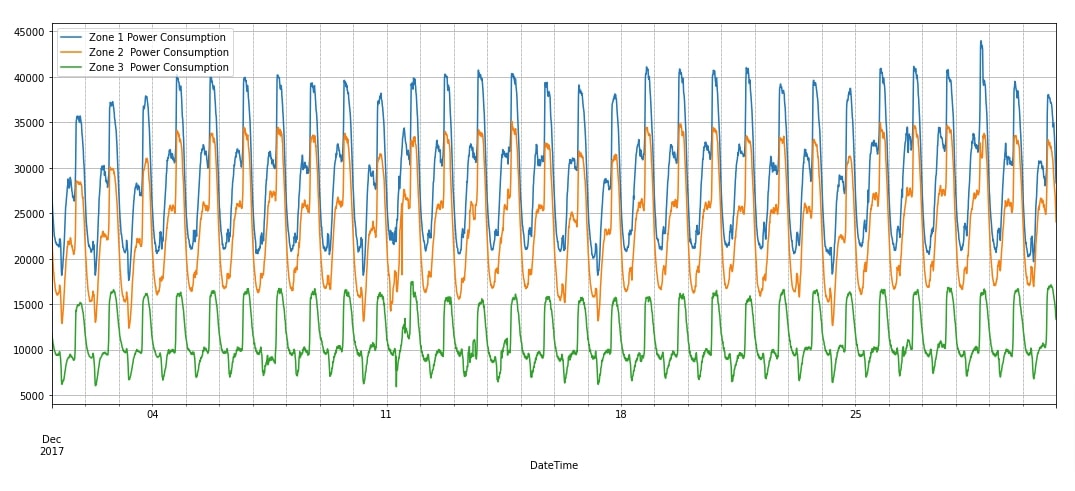
In the next cell after the below cell, we have plotted the power consumption of three zones for December 2017. We can notice from the chart that there is clear seasonality in the data.
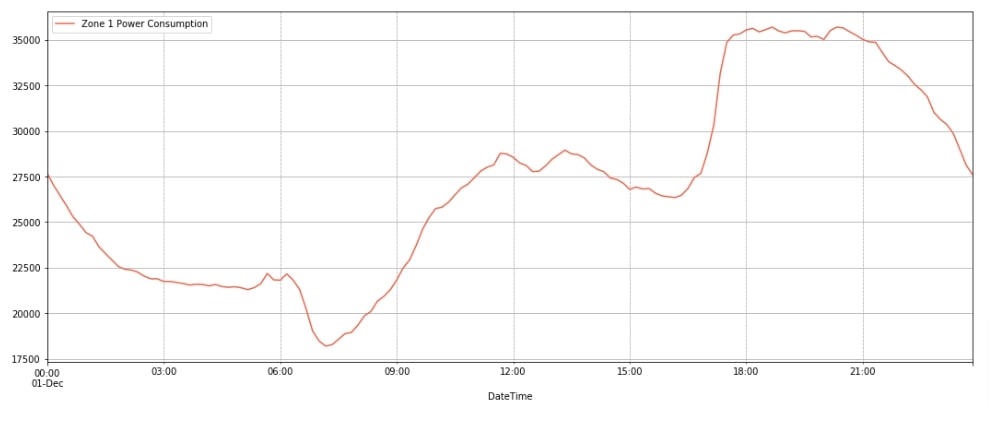
We have also plotted the power consumption for a single day (1st Dec 2017) to give an idea of how power demand varies throughout the day. We can notice from the chart that power requirement is less at the beginning of the day and keeps increasing till around 9 PM and then starts to drop again.
import pandas as pd
data_df = pd.read_csv("Tetuan City power consumption.csv")
data_df["DateTime"] = pd.to_datetime(data_df["DateTime"])
data_df = data_df.set_index('DateTime')
data_df.columns = [col.strip() for col in data_df.columns]
print("Columns : {}".format(data_df.columns.values.tolist()))
print("Dataset Shape : {}".format(data_df.shape))
data_df.head()
import matplotlib.pyplot as plt
data_df.loc["2017-12"].plot(y=["Zone 1 Power Consumption", "Zone 2 Power Consumption", "Zone 3 Power Consumption"], figsize=(18, 7), grid=True);
plt.grid(which='minor', linestyle=':', linewidth='0.5', color='black');
import matplotlib.pyplot as plt
data_df.loc["2017-12-1"].plot(y="Zone 1 Power Consumption", figsize=(18, 7), color="tomato", grid=True);
plt.grid(which='minor', linestyle=':', linewidth='0.5', color='black');
1.3 Organize Data¶
In this section, we have organized data for our network. As mentioned earlier, to make a prediction of any target value, we'll be using data features from the previous 30 examples. We have set the variable lookback to this value. As data is measured every 10 minutes, we'll be looking at the previous 5 hours of data to make a prediction of the current value.
We'll be using columns ['Temperature', 'Humidity', 'Wind Speed', 'general diffuse flows', 'diffuse flows'] as data features (X) and column Zone 1 Power Consumption as target value (Y). In order to prepare data, we are looping through the data moving window of size 30 through it. For each iteration, we add data features of examples that fall into a window in X_organized array and the value of the target column from the next example after the window into Y_organized. A window will move by a step size of 1 each time.
After organizing the dataset by moving the window of lookback size, we have divided data into the train (first 50k examples) and test sets (remaining examples till the end). We have also printed the shape of datasets for reference.
import numpy as np
feature_cols = ['Temperature', 'Humidity', 'Wind Speed', 'general diffuse flows', 'diffuse flows']
target_col = 'Zone 1 Power Consumption'
X = data_df[feature_cols].values
Y = data_df[target_col].values
n_features = X.shape[1]
lookback = 30 ## 5 hours lookback to make prediction
X_organized, Y_organized = [], []
for i in range(0, X.shape[0]-lookback, 1):
X_organized.append(X[i:i+lookback])
Y_organized.append(Y[i+lookback])
X_organized, Y_organized = np.array(X_organized), np.array(Y_organized)
X_train, Y_train, X_test, Y_test = X_organized[:50000], Y_organized[:50000], X_organized[50000:], Y_organized[50000:]
X_organized.shape, Y_organized.shape, X_train.shape, Y_train.shape, X_test.shape, Y_test.shape
1.4 Scale Target Values¶
If you have looked at the data values of various columns earlier, you can notice that values present in all three consumption columns are quite high compared to our data features columns. This can create problems for our network as it might need to move weights by big amounts to make such large predictions. This can prevent it from converging or can take a lot of time to converge.
To make it converge faster, we have normalized target values. We have recorded the mean and standard deviation of target values. Then, we subtracted the mean from train/test target values and divided subtracted values by standard deviation. This process has brought target values of train and test datasets into the lower range. When making predictions using our algorithm, we'll reverse this process to make an actual prediction of consumption units.
mean, std = Y_train.mean(), Y_train.std()
print("Mean : {:.2f}, Standard Deviation : {:.2f}".format(mean, std))
Y_train_scaled, Y_test_scaled = (Y_train - mean)/std , (Y_test-mean)/std
Y_train_scaled.min(), Y_train_scaled.max(), Y_test_scaled.min(), Y_test_scaled.max()
import gc
del X, Y
gc.collect()
2. Define Network ¶
Here, we have defined a neural network that we'll use for our time-series regression task using Keras. The network is simple and consists of 3 layers (two LSTM layers and one dense layer). Both LSTM layers have 256 output units. The first LSTM layer transforms input data shape from (batch_size, 30, 5) to (batch_size, 30, 256) after processing. The output of the first LSTM layer will be given to the second LSTM layer which will apply its processing. The shape of output data from the second LSTM layer is the same as the first because both have the same output units. The output of the second LSTM layer is given to a dense layer that has one output unit. The dense layer will process data and output processed data of shape (batch_size, 1). The output of the dense layer is a prediction of our network.
After defining a network, we have also printed a summary of the network showing the output shape and parameters (weights/biases) count of each layer.
Please make a note that we have assumed that the reader has background knowledge on RNNs and LSTM hence we have not covered the inner workings of them in detail here. Please feel free to check the below link if you are looking for a little background.
from keras.models import Sequential
from keras.layers import LSTM, Dense, Embedding
lstm_out = 256
model = Sequential([
LSTM(lstm_out, return_sequences=True, input_shape=(lookback, n_features)),
LSTM(lstm_out),
Dense(1)
])
model.summary()
3. Compile and Train Network ¶
Here, we have first compiled our network to use Adam optimizer, mean squared error (MSE) loss function, and mean absolute error (MAE) metric. After compiling the network, we performed the training process by calling fit() method. We have trained the network for 15 epochs. To train the network, we have provided train data for the method. The network will be trained by looping through train data in a batch size of 32. We can notice from the MSE loss getting printed after each epoch that our network is improving because loss is decreasing constantly. Next, we'll check the performance of our network by making predictions on the test dataset.
model.compile(optimizer="adam", loss="mse", metrics=["mae"])
history = model.fit(X_train, Y_train_scaled, batch_size=32, epochs=15, validation_data=(X_test, Y_test_scaled))
4. Evaluate Network Performance ¶
In this section, we have evaluated the performance of our network on the test dataset to see how it has been done.
Below, we have first made predictions on the test dataset using our trained network. After making a prediction, we have rescaled the prediction by multiplying it with the standard deviation and adding the mean of the target values calculated earlier. This will bring our predictions into an actual range of consumption units.
Then, we calculated R2 score on test predictions. The R2 score is a very common metric used to measure the performance of the network on regression tasks. We have calculated score using r2_score() function available from scikit-learn library. The score generally has values in the range 0-1 and values near 1 are considered signs of a good generalized model. We can notice from the r2 score in our case that our model has done a good job at the regression task.
Please feel free to check the below link if you want to understand how r2 score works internally. Sklearn provides many ML metrics. The majority of them are covered in detail.
test_preds = model.predict(X_test) ## Make Predictions on test dataset
test_preds = (test_preds*std) + mean
test_preds[:5]
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
print("Test MSE : {:.2f}".format(mean_squared_error(test_preds.squeeze(), Y_test)))
print("Test R^2 Score : {:.2f}".format(r2_score(test_preds.squeeze(), Y_test)))
print("Test MAE : {:.2f}".format(mean_absolute_error(test_preds.squeeze(), Y_test)))
5. Visualize Predictions ¶
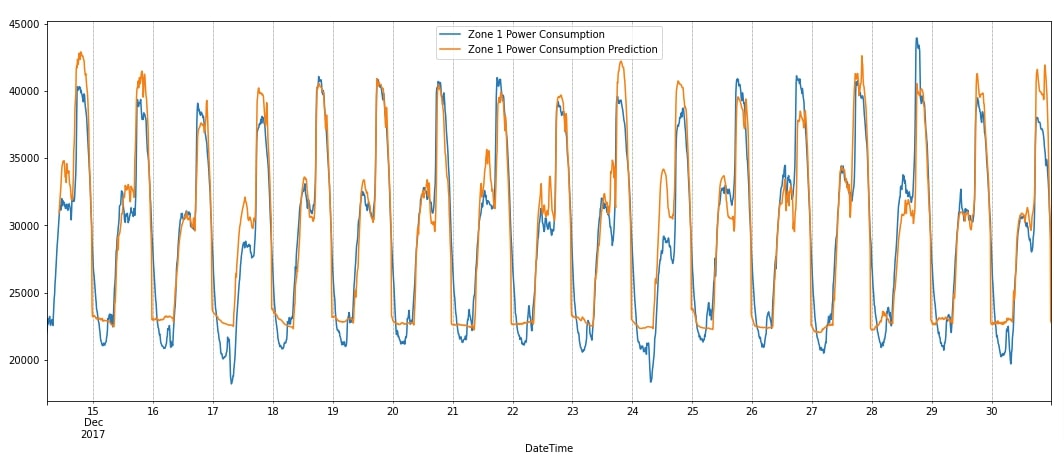
After making predictions, we have added them to the dataframe and also plotted them. We have plotted actual and predicted power consumption next to each other for verification purposes. We can notice from the chart that our model has done quite a good job at capturing the seasonality. It is properly able to capture upward movement. It is making little mistakes in downward movements. Next, we have suggested a few points which can be tried to further improve network performance.
data_df_final = data_df[50000:].copy()
data_df_final["Zone 1 Power Consumption Prediction"] = [None]*lookback + test_preds.squeeze().tolist()
data_df_final.tail()
data_df_final.plot(y=["Zone 1 Power Consumption", "Zone 1 Power Consumption Prediction"],figsize=(18,7));
plt.grid(which='minor', linestyle=':', linewidth='0.5', color='black');
6. Further Suggestions ¶
- Train network for more epochs.
- Make the network predict more than one future target value. In our case, we made the network predict only one future value. We can modify the network to simply predict the next 5 or more values as well. We'll need to organize data in that way as well.
- Try different output units for LSTM layers.
- Try stacking more LSTM layers though it can increase training time.
- Try adding more dense layers after LSTM layers.
- Try adding date-related features to data like a month, year, day, day of the week, month-end, month-start, quarter-end, quarter-start, year-end, year-start, etc.
- Try learning rate schedulers
 Sunny Solanki
Sunny Solanki
Sunny Solanki
Intro: Software Developer | Youtuber | Bonsai Enthusiast
About: Sunny Solanki holds a bachelor's degree in Information Technology (2006-2010) from L.D. College of Engineering. Post completion of his graduation, he has 8.5+ years of experience (2011-2019) in the IT Industry (TCS). His IT experience involves working on Python & Java Projects with US/Canada banking clients. Since 2020, he’s primarily concentrating on growing CoderzColumn.
His main areas of interest are AI, Machine Learning, Data Visualization, and Concurrent Programming. He has good hands-on with Python and its ecosystem libraries.
Apart from his tech life, he prefers reading biographies and autobiographies. And yes, he spends his leisure time taking care of his plants and a few pre-Bonsai trees.
Contact: sunny.2309@yahoo.in



![YouTube Subscribe]() Comfortable Learning through Video Tutorials?
Comfortable Learning through Video Tutorials?
If you are more comfortable learning through video tutorials then we would recommend that you subscribe to our YouTube channel.
![Need Help]() Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
 Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?When going through coding examples, it's quite common to have doubts and errors.
If you have doubts about some code examples or are stuck somewhere when trying our code, send us an email at coderzcolumn07@gmail.com. We'll help you or point you in the direction where you can find a solution to your problem.
You can even send us a mail if you are trying something new and need guidance regarding coding. We'll try to respond as soon as possible.
![Share Views]() Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?
 Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?If you want to
- provide some suggestions on topic
- share your views
- include some details in tutorial
- suggest some new topics on which we should create tutorials/blogs
 keras, lstm, time-series, regression
keras, lstm, time-series, regression