Scikit-Learn - Non-Linear Dimensionality Reduction: Manifold Learning¶
Table of Contents¶
- Introduction
- Isometric Mapping (Isomap)
- t-distributed Stochastic Neighbor Embedding (t-SNE)
- Spectral Embedding
- LocallyLinearEmbedding (LLE)
- Modified LLE
- Hessian LLE
- Local Tangent Space Alignment (LTSA)
- Multi-Dimensional Scaling (MDS)
- Testing Performance Of Various Dimensionality Reduction Algorithms
- References
Introduction ¶
Many real-life datasets contain non-linear features that PCA generally fails to properly detect. To solve this problem new class of algorithms called manifold learning were introduced which solves this problem of detecting non-linear features. As a part of this tutorial, we'll be introducing various manifold learning algorithms available through scikit-learn.
Below are list of manifold learning algorithms available through scikit-learn:
- Isometric Mapping (Isomap)
- t-distributed Stochastic Neighbor Embedding (t-SNE )
- Spectral Embedding
- LocallyLinearEmbedding (LLE)
- Modified LLE
- Hessian LLE
- Local Tangent Space Alignment (LTSA)
- Multi-Dimensional Scaling (MDS)
We'll be introducing the usage of each algorithm along with their important parameters, attributes, and methods available in sklearn estimators.
We'll start by importing all the necessary libraries.
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import warnings
import sys
warnings.filterwarnings('ignore')
%matplotlib inline
Load Datasets¶
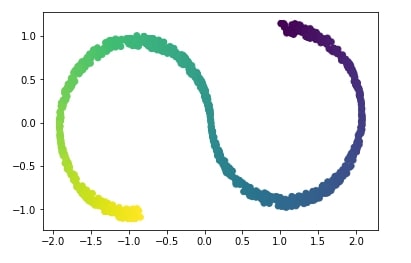
We'll start by making a s-curve dataset using the datasets module provided by scikit-learn. S-curve creates dataset in a way that 2-dimensional data is hidden into 3-dimension.
from sklearn.datasets import make_s_curve
X, Y = make_s_curve(n_samples=1000)
The second dataset that we'll be using is digits dataset which has images of size 8x8 for digits 0-5. We'll use digits data for classification tasks below.
Sklearn provides this dataset as a part of the datasets module. We can load it by calling load_digits() method. It returns dictionary-like object BUNCH which can be used to retrieve features and target.
from sklearn.datasets import load_digits
digits = load_digits(n_class=6)
X_digits, Y_digits = digits.data, digits. target
print('Dataset Size : ', X_digits.shape, Y_digits.shape)
Visualizing S-Curve Dataset¶
plt.figure(figsize=(12,8))
ax = plt.axes(projection='3d')
ax.scatter3D(X[:, 0], X[:, 1], X[:, 2], c=Y)
ax.view_init(10, -60);
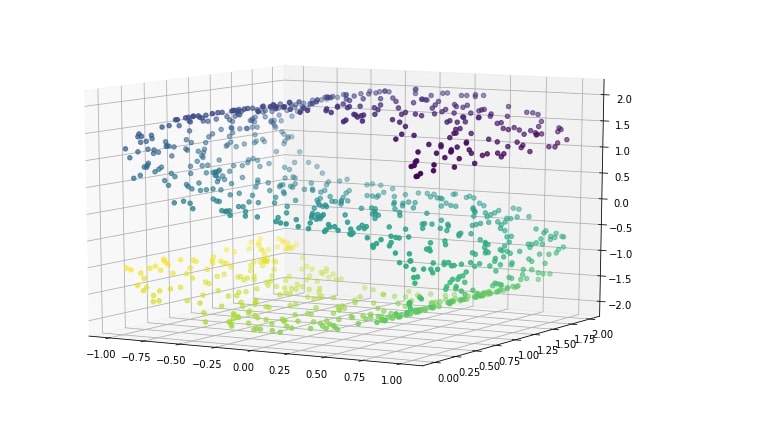
PCA Transformation Applied to S-Curve Data¶
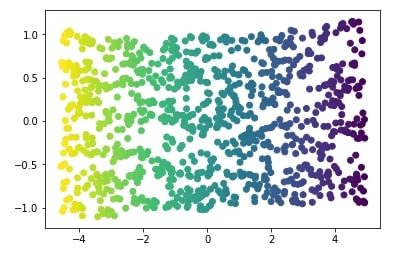
Above s-curve hides 2-dimensional data in a 3-dimension in such a way that PCA fails to identify the structure. Below visualization of s-curve shows that PCA fails to capture information in data.
from sklearn.decomposition import PCA
X_pca = PCA(n_components=2).fit_transform(X)
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=Y);
We'll try below non-linear dimensionality reduction technique called Isomap which successfully captures information in data.
Isometric Mapping (Isomap) ¶
It can be thought of as an extension of Multi-Dimensional Scaling(MDS) or Kernel PCA. It tries to find lower dimensional embedding of the original dataset while maintaining geodesic distances between all points in the original dataset. Isomap tries to get lower dimension representation of data where points maintain geodesic distance) between them like original representation. Scikit-learn provides an implementation of Isomap as a part of the manifold module.
Below is a list of important parameters of Isomap which can be tweaked to further improve performance:
- n_neighbors - It accepts integer specifying number of neighbors to consider for each point.
default=5 - n_components -It accepts integer value specifying number of features transformed dataset will have.
default=2 - eigen_solver -It accepts one of the below string specifying solver to use for transformation.
auto- Default.arpackdense
- path_method - It accepts one of the below string specifying method to use to find shortest path.
auto- Default.FW- Floyd-Warshall algorithmD- Dijkstra's Algorithm
- neighbors_algorithm - It accepts one of the below string specifying the algorithm to use for the nearest neighbor’s search.
auto- Defaultkd_treeball_treebrute
- metric - It accepts string or callable specifying metric to use when calculating distance between points. The default value is
minkowski.
We'll apply Isomap to S-Curve dataset and visualize the results below.
from sklearn import manifold
iso = manifold.Isomap(n_neighbors=15, n_components=2)
X_iso = iso.fit_transform(X)
plt.scatter(X_iso[:, 0], X_iso[:, 1], c=Y);
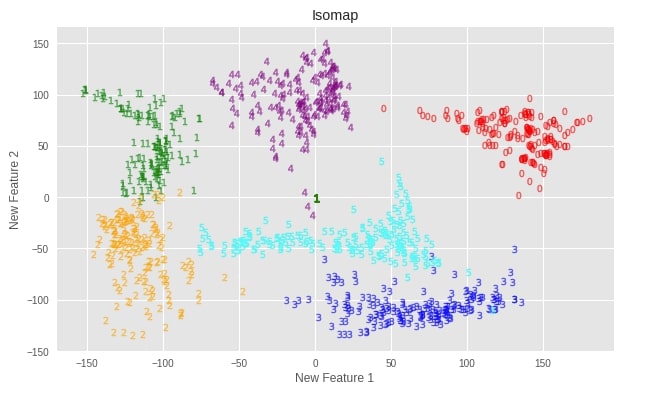
Apply Isomap to DIGITS Dataset¶
Let’s apply various manifold learning techniques to digits dataset we loaded earlier and visualize results.
Initialize Model and Transform Data¶
isomap = manifold.Isomap(n_neighbors=5, n_components=2)
X_digits_isomap = isomap.fit_transform(X_digits)
Plotting Transformed Dataset¶
def plot_digits(X, algo=""):
with plt.style.context(("seaborn", "ggplot")):
fig = plt.figure(1, figsize=(10, 6))
colors = ['red','green','orange','blue','purple','cyan','magenta', 'firebrick', 'lawngreen','indigo']
for digit in range(0,6):
plt.scatter(X[Y_digits==digit,0],X[Y_digits==digit,1], c = colors[digit], marker="$"+str(digit)+"$",s =50, alpha=0.5)
plt.xlabel("New Feature 1")
plt.ylabel("New Feature 2")
plt.title(algo)
plt.show()
plot_digits(X_digits_isomap, "Isomap")
Important Attributes of Isomap¶
Below are list of important attributes of trained Isomap instance which can provide meaningful insights:
embedding_- It returns embedding vector obtained through training.kernel_pca_- It returnsKernelPCAobject used for generating embedding.nbrs_- It returns nearest neighbor instance.dist_matrix_- It returns geodesic distance matrix for train data.
print("Embedding Shape : ",isomap.embedding_.shape)
isomap.kernel_pca_
isomap.nbrs_
print("Geodesic Distance Matrix For Training Data Shape : ", isomap.dist_matrix_.shape)
Transform DIGITS Dataset to 3-Components Dataset using Isomap¶
isomap = manifold.Isomap(n_neighbors=5, n_components=3)
X_digits_isomap3 = isomap.fit_transform(X_digits)
t-distributed Stochastic Neighbor Embedding (t-SNE) ¶
t-SNE transforms linking between point which is represented by Gaussian joint probabilities to student's t-distributions in embedded space. It's best suited to handle data with more than one fold whereas algorithms like Isomap, LLE, etc are best suited for single fold data. t-SNE tries to group samples based on their local structure. Scikit-learn provides the TSNE estimator as a part of the manifold module to use this algorithm in practice.
Below is a list of important parameters of TSNE which can be tweaked to improve performance of the default model:
- n_components -It accepts integer value specifying number of features transformed dataset will have.
default=2 - perplexity - It accepts float specifying a number of nearest neighbors used on other manifold learning algorithms. It's advised to use a value between
5-50.default=30 - early_exaggeration - It accepts float value specifying how far clusters are in embedded space.
default=12 - learning_rate - It accepts float specifying learning rate of t-SNE. It's advisable to use values between
10-1000.default=200 - metric - It accepts a string or callable specifying metric to use to measure the distance between data points.
default=euclidean.
Apply t-SNE to DIGITS Dataset¶
Initialize Model and Transform Data¶
tsne = manifold.TSNE(random_state=42, n_components=2)
X_digits_tsne = tsne.fit_transform(X_digits)
Plotting Transformed Dataset¶
plot_digits(X_digits_tsne, "t-SNE")
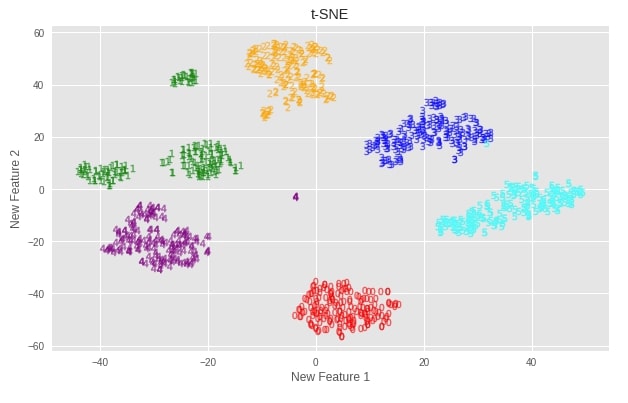
Important Attributes of t-SNE¶
Below is a list of important attributes of trained t-SNE instance which can provide meaningful insights:
embedding_- It returns embedding vector obtained through training.kl_divergence_- It returns Kullback-Leibler divergence after optimization.
print("Embedding Shape : ",tsne.embedding_.shape)
print("Kullback-Leibler divergence : ",tsne.kl_divergence_)
Transform DIGITS Dataset to 3-Components Dataset using t-SNE¶
tsne = manifold.TSNE(random_state=42, n_components=3)
X_digits_tsne3 = tsne.fit_transform(X_digits)
Spectral Embedding ¶
Spectral embedding finds a low dimensional representation of data using spectral decomposition of graph Laplacian. Scikit-Learn provides SpectralEmbedding implementation as a part of the manifold module.
Below is a list of important parameters of TSNE which can be tweaked to improve performance of the default model:
- n_components -It accepts integer value specifying number of features transformed dataset will have.
default=2 - affinity - It accepts a string or callable specifying how to calculate the affinity matrix of data. The affinity matrix has a size of (n_samples x n_samples). Below is a list of possible values for it.
nearest_neighbors- Default.rbfprecomputedprecomputed_nearest_neighbors
- gamma - It accepts float value specifying
gammaparameter to use whenaffinityis set torbf. - n_neighbors -It accepts integer value specifying number of neighbors to use when
affinityis set tonearest_neighbors.
Apply Spectral Embedding to DIGITS Dataset¶
Initialize Model and Transform Data¶
spectral_embedding = manifold.SpectralEmbedding(random_state=42, n_components=2)
X_digits_spectral = spectral_embedding.fit_transform(X_digits)
Plotting Transformed Dataset¶
plot_digits(X_digits_spectral, "Spectral Embedding")
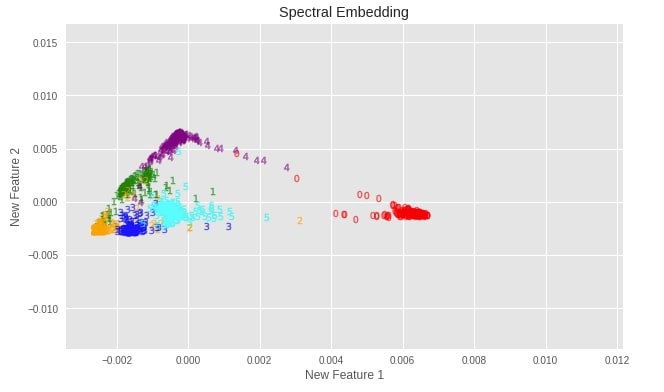
Important Attributes of Spectral Embedding¶
Below is a list of important attributes of trained Spectral Embedding instance which can provide meaningful insights:
embedding_- It returns embedding vector obtained through training.affinity_matrix_- It returns affinity matrix calculated.
print("Embedding Shape : ",spectral_embedding.embedding_.shape)
print("Affinity Matrix Shape : ",spectral_embedding.affinity_matrix_.shape)
Transform DIGITS Dataset to 3-Components Dataset using Spectral Embedding¶
spectral_embedding = manifold.SpectralEmbedding(random_state=42, n_components=3)
X_digits_spectral3 = spectral_embedding.fit_transform(X_digits)
LocallyLinearEmbedding (LLE) ¶
LLE tries to find the lower-dimensional projection of data while maintaining distances within local neighborhood points. It can be viewed as applying a series of local PCAs that are then compared globally to find the most suited non-linear embedding. As an algorithm based on neighborhood points, we need to provide a number of neighbors to consider for it as input parameter (n_neighbors). Scikit-learn provides an estimator named LocallyLinearEmbedding as a part of the manifold module for performing Locally Linear Embedding on data.
Below is a list of important parameters of LocallyLinearEmbedding which can be tweaked to further improve performance:
- n_neighbors - It accepts integer specifying number of neighbors to consider for each point.
default=5 - n_components -It accepts integer value specifying number of features transformed dataset will have.
default=2 - eigen_solver -It accepts one of the below string specifying solver to use for transformation.
auto- Default.arpackdense
- method - This parameter accepts string value specifying different variants of LLE. Below are list of possible values.
standard- Default.hessianmodifiedltsa
- neighbors_algorithm - It accepts one of the below string specifying algorithm to use for nearest neighbors search.
auto- Defaultkd_treeball_treebrute
Apply LLE to DIGITS Dataset¶
Initialize Model and Transform Data¶
linear_embedding = manifold.LocallyLinearEmbedding(random_state=42,n_neighbors=5, n_components=2)
X_digits_linear = linear_embedding.fit_transform(X_digits)
Plotting Transformed Dataset¶
plot_digits(X_digits_linear, "Locally Linear Embedding")
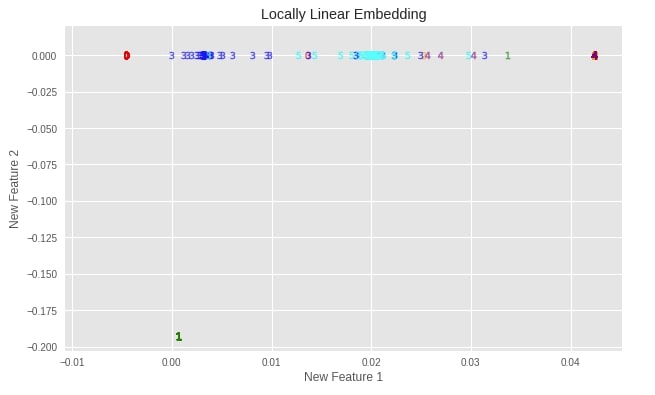
Important Attributes of LLE¶
Below is a list of important attributes of trained LLE instance which can provide meaningful insights:
embedding_- It returns embedding vector obtained through training.reconstruction_error_- It returns float value specifying reconstruction error associated with embedding.nbrs_- It returns nearest neighbor instance.
print("Embedding Shape : ",linear_embedding.embedding_.shape)
print("Reconstruction Error : ",linear_embedding.reconstruction_error_)
linear_embedding.nbrs_
Transform DIGITS Dataset to 3-Components Dataset using LLE¶
linear_mebedding = manifold.LocallyLinearEmbedding(random_state=42,n_neighbors=5, n_components=3)
X_digits_linear3 = linear_mebedding.fit_transform(X_digits)
Modified LLE ¶
LLE suffers from a regularization problem when a number of neighbors are greater than a number of input dimensions. To solve this problem and apply regularization sklearn provides a modified version of LLE as well. The developer needs to supply the method as "modified" to use this version of LLE when calling LocallyLinearEmbedding estimator of the manifold module.
It required a number of neighbors greater than a number of features.
The parameters of Modified LLE are the same as Standard LLE due to the usage of the same estimator from sklearn.
Apply Modified LLE to DIGITS Dataset¶
Initialize Model and Transform Data¶
linear_embedding = manifold.LocallyLinearEmbedding(random_state=42,n_neighbors=30, n_components=2, method="modified")
X_digits_linear_modified = linear_embedding.fit_transform(X_digits)
Plotting Transformed Dataset¶
plot_digits(X_digits_linear_modified, "Modified LLE")
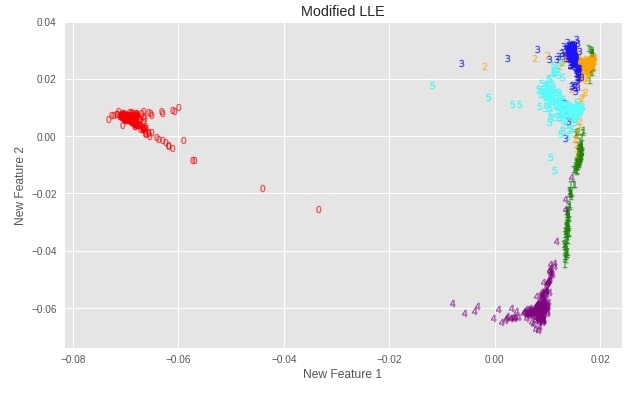
Important Attributes of Modified LLE¶
Modified LLE has the same attributes as standard LLE.
print("Embedding Shape : ",linear_embedding.embedding_.shape)
print("Reconstruction Error : ",linear_embedding.reconstruction_error_)
linear_embedding.nbrs_
Transform DIGITS Dataset to 3-Components Dataset using Modified LLE¶
linear_embedding = manifold.LocallyLinearEmbedding(random_state=42,n_neighbors=30, n_components=2,
method="modified")
X_digits_linear_modified3 = linear_embedding.fit_transform(X_digits)
Hessian LLE ¶
Hessian is another method available with LLE to solve the regularization problem. sklearn provides this variant by setting the method parameter as "hessian" in LocallyLinearEmbedding constructor.
It requires that (number of neighbors) > (number of features) * (number of features + 3) / 2
The parameters of Hessian LLE are the same as Standard LLE due to usage of the same estimator from sklearn.
Apply Hessian LLE to DIGITS Dataset¶
Initialize Model and Transform Data¶
linear_embedding = manifold.LocallyLinearEmbedding(random_state=42,n_neighbors=30, n_components=2, method="hessian")
X_digits_linear_hessian = linear_embedding.fit_transform(X_digits)
Plotting Transformed Dataset¶
plot_digits(X_digits_linear_hessian, "Hessian LLE")
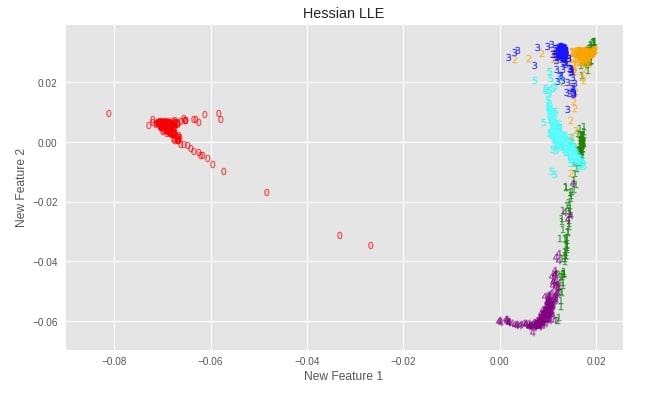
Important Attributes of Hessian LLE¶
Hessian LLE has the same attributes as standard LLE.
print("Embedding Shape : ",linear_embedding.embedding_.shape)
print("Reconstruction Error : ",linear_embedding.reconstruction_error_)
linear_embedding.nbrs_
Transform DIGITS Dataset to 3-Components Dataset using Hessian LLE¶
linear_embedding = manifold.LocallyLinearEmbedding(random_state=42,n_neighbors=30,
n_components=3, method="hessian")
X_digits_linear_hessian3 = linear_embedding.fit_transform(X_digits)
Local Tangent Space Alignment (LTSA) ¶
LTSA is not variant of LLE but it is the same algorithmically to LLE. Unlike LLE, LTSA tries to maintain local geometry at each neighborhood via its tangent space and then optimizes to align these tangent spaces to generate embeddings for data. Scikit-learn provides this variant by setting the method parameter as "ltsa" in LocallyLinearEmbedding constructor.
The parameters of LTSA are the same as Standard LLE due to usage of the same estimator from sklearn.
Apply LTSA to DIGITS Dataset¶
Initialize Model and Transform Data¶
linear_embedding = manifold.LocallyLinearEmbedding(random_state=42, n_neighbors=30, n_components=2, method="ltsa")
X_digits_linear_ltsa = linear_embedding.fit_transform(X_digits)
Plotting Transformed Dataset¶
plot_digits(X_digits_linear_ltsa, "Local Tangent Space Alignment")
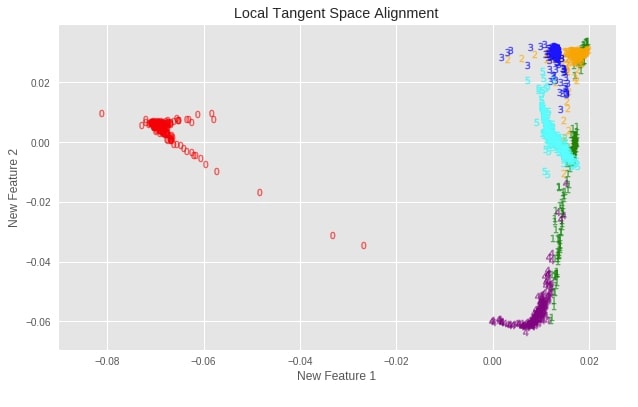
Important Attributes of LTSA¶
LTSA has the same attributes as standard LLE.
print("Embedding Shape : ",linear_embedding.embedding_.shape)
print("Reconstruction Error : ",linear_embedding.reconstruction_error_)
linear_embedding.nbrs_
Transform DIGITS Dataset to 3-Components Dataset using LTSA¶
linear_embedding = manifold.LocallyLinearEmbedding(random_state=42,n_neighbors=10,
n_components=3, method="ltsa")
X_digits_linear_lta3 = linear_embedding.fit_transform(X_digits)
Multi-Dimensional Scaling (MDS) ¶
Multi-Dimensional Scaling an algorithm used for analyzing similarity or dissimilarity in data. It tries to decide similarity or dissimilarity based on distances between data points in geometric spaces. It tries to find a low dimensional representation of data that maintains the same distance between data points in original high dimensional data. Scikit-learn provides an implementation of MDS as a part of manifold module.
Below is a list of important parameters of MDS which can be tweaked to further improve performance:
- n_components -It accepts integer value specifying number of features transformed dataset will have.
default=2 - metric - It accepts boolean value specifying to perform metric MDS if set to True else use nonmetric MDS.
- dissimilarity - It accepts string value specifying dissimilarity measure.
euclidean- Default.precomputed
- eps - It accepts float value specifying relative tolerance with respect to stress.
default=0.001
Apply MDS to DIGITS Dataset¶
Initialize Model and Transform Data¶
mds = manifold.MDS(random_state=42, n_components=2)
X_digits_mds = mds.fit_transform(X_digits)
Plotting Transformed Dataset¶
plot_digits(X_digits_mds, "Multi-Dimensional Scaling")
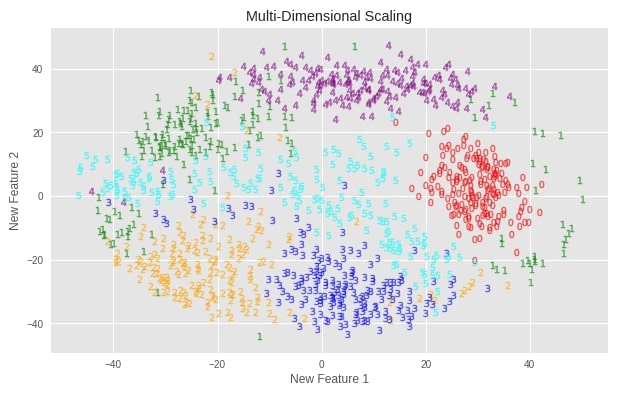
Important Attributes of MDS¶
Below is a list of important attributes of trained MDS instance which can provide meaningful insights:
embedding_- It returns embedding vector obtained through training.stress_- It returns the sum of squared distance for disparities and distances for all constrained points.
print("Embedding Shape : ", mds.embedding_.shape)
print("Final Stress Value : ", mds.stress_)
Transform DIGITS Dataset to 3-Components Dataset using MDS¶
mds = manifold.MDS(random_state=42, n_components=3)
X_digits_mds3 = mds.fit_transform(X_digits)
Please make a note that MDS & t-SNE btoh are time consuming algorithms and can take lot of time if used on dataset with millions of entries.
Testing Performance Of Various Dimensionality Reduction Algorithms ¶
Below we have designed a method named test_model which takes as input classifier, data, and labels as input. It then divides data into train/test sets, train a classifier on train data, and evaluate it on both train & test data. It prints the accuracy of the classifier on both train and test data.
The second method that we have declared tries classifier passed to it on all 2-component and 3-component transformation of the original digits dataset. It prints the classifier's accuracy on all transformed datasets to check which one performs well like original and succeeded in keeping as much information from original high-dimensional data. It also tries classifiers on original data.
We are calling compare_accuracy_of_various_techniques() method with 2 different classifiers:
- LogisticRegression
- KNeighborsClassifier
from sklearn.model_selection import train_test_split
def test_model(classifier, X, Y):
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, train_size=0.80, test_size=0.20, stratify=Y, random_state=123)
print("Dataset Size : ",sys.getsizeof(X),"bytes, Shape : ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
classifier.fit(X_train, Y_train)
print('Train Accuracy : %.2f, Test Accuracy : %.2f'%(classifier.score(X_train, Y_train), classifier.score(X_test, Y_test)))
def compare_accuracy_of_various_techniques(classifier):
print("Digits dataset performance without Transformation of Any Kind :")
test_model(classifier, X_digits, Y_digits)
print("\nDigits dataset performance with Isomap(2 components) :")
test_model(classifier, X_digits_isomap, Y_digits)
print("Digits dataset performance with Isomap(3 components) :")
test_model(classifier, X_digits_isomap3, Y_digits)
print("\nDigits dataset performance with TSNE(2 components) :")
test_model(classifier, X_digits_tsne, Y_digits)
print("Digits dataset performance with TSNE(3 components) :")
test_model(classifier, X_digits_tsne3, Y_digits)
print("\nDigits dataset performance with SpectralEmbedding(2 components) :")
test_model(classifier, X_digits_spectral, Y_digits)
print("Digits dataset performance with SpectralEmbedding(3 components) :")
test_model(classifier, X_digits_spectral3, Y_digits)
print("\nDigits dataset performance with LocallyLinearEmbedding(2 components) :")
test_model(classifier, X_digits_linear, Y_digits)
print("Digits dataset performance with LocallyLinearEmbedding(3 components) :")
test_model(classifier, X_digits_linear3, Y_digits)
print("\nDigits dataset performance with ModifiedLocallyLinearEmbedding(2 components) :")
test_model(classifier, X_digits_linear_modified, Y_digits)
print("Digits dataset performance with ModifiedLocallyLinearEmbedding(3 components) :")
test_model(classifier, X_digits_linear_modified3, Y_digits)
print("\nDigits dataset performance with HessianLocallyLinearEmbedding(2 components) :")
test_model(classifier, X_digits_linear_hessian, Y_digits)
print("Digits dataset performance with HessianLocallyLinearEmbedding(3 components) :")
test_model(classifier, X_digits_linear_hessian3, Y_digits)
print("\nDigits dataset performance with MDS(2 components) :")
test_model(classifier, X_digits_mds, Y_digits)
print("Digits dataset performance with MDS(3 components) :")
test_model(classifier, X_digits_mds3, Y_digits)
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(solver='newton-cg',multi_class='auto')
compare_accuracy_of_various_techniques(classifier)
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier()
compare_accuracy_of_various_techniques(classifier)
This ends our small tutorial explaining various estimators available for performing unsupervised manifold learning dimensionality reduction with sklearn. Please feel free to let us know your views in the comments section.
References ¶
 Sunny Solanki
Sunny Solanki
Sunny Solanki
Intro: Software Developer | Youtuber | Bonsai Enthusiast
About: Sunny Solanki holds a bachelor's degree in Information Technology (2006-2010) from L.D. College of Engineering. Post completion of his graduation, he has 8.5+ years of experience (2011-2019) in the IT Industry (TCS). His IT experience involves working on Python & Java Projects with US/Canada banking clients. Since 2020, he’s primarily concentrating on growing CoderzColumn.
His main areas of interest are AI, Machine Learning, Data Visualization, and Concurrent Programming. He has good hands-on with Python and its ecosystem libraries.
Apart from his tech life, he prefers reading biographies and autobiographies. And yes, he spends his leisure time taking care of his plants and a few pre-Bonsai trees.
Contact: sunny.2309@yahoo.in



![YouTube Subscribe]() Comfortable Learning through Video Tutorials?
Comfortable Learning through Video Tutorials?
If you are more comfortable learning through video tutorials then we would recommend that you subscribe to our YouTube channel.
![Need Help]() Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
 Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?When going through coding examples, it's quite common to have doubts and errors.
If you have doubts about some code examples or are stuck somewhere when trying our code, send us an email at coderzcolumn07@gmail.com. We'll help you or point you in the direction where you can find a solution to your problem.
You can even send us a mail if you are trying something new and need guidance regarding coding. We'll try to respond as soon as possible.
![Share Views]() Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?
 Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?If you want to
- provide some suggestions on topic
- share your views
- include some details in tutorial
- suggest some new topics on which we should create tutorials/blogs
 sklearn, manifold-learning
sklearn, manifold-learning