Keras: RNNs (LSTM) for Text Generation (Character Embeddings)¶
Text Generation is an area of natural language processing (NLP) where we train models on the existing corpus of data and then generate new data. The models used for text generation tasks as generally referred to as language models. The language models are commonly used for tasks like conversational systems (chatbots), text summarization, text translation, etc. With the rise of deep learning, language models are created as deep neural networks. Recurrent neural networks (RNNs) are generally preferred to create language models for text generation tasks. The RNNs and their variants (LSTM, GRU, etc) are quite good at remembering sequences in data. They take into consideration previously seen examples to make predictions for the current. This approach makes them a better choice for text generation as we want the model to take into consideration previous words/characters when making predictions of the next word/character.
As a part of this tutorial, we have explained how to create Recurrent Neural Networks (RNNs) consisting of LSTM layers for text generation tasks using Python deep learning library Keras. We have used character-based approach for text generation where our model takes a specified number of words as input and predicts the next character that it thinks should come after them. To encode text data to real-valued data for the network, we have used word embeddings approach where we assign a real-valued vector of specified length to each unique character of the corpus. For training purposes, we have used Wikipedia article dataset available from torchtext library. We have another tutorial on text generation using Keras which does not use character embeddings and is based on only a bag of words. Please feel free to check it from the below link.
Below, we have listed important sections of tutorial to give an overview of the material covered in it.
Important Sections Of Tutorial¶
- Prepare Dataset
- 1.1 Load Dataset
- 1.2 Populate Vocabulary
- 1.3 Organize Data
- Define Model
- Compile And Train Model
- Generate Text
- Train For More Epochs
- Generate Text
- Train Even More
- Generate Text
- Further Recommendations
Below, we have imported the necessary libraries that we have used in our tutorial and printed their versions as well.
import tensorflow
from tensorflow import keras
print("Keras Version : {}".format(keras.__version__))
import torchtext
print("TorchText Version : {}".format(torchtext.__version__))
import gc
1. Prepare Dataset ¶
In this section, we are preparing data to be given to the neural network for processing. As we said earlier, we'll use character-based approach for text generation which means that we'll give a specified number of characters to the neural network and make it predict the next character after them. We have decided that we'll give 100 characters sequence to network and make it predict the next character after them. For encoding characters, we'll use character embeddings approach. Below, we have listed steps in short that we'll follow to prepare data.
- Load data.
- Loop through each text example of data and prepare a vocabulary of unique characters. A vocabulary is a simple mapping from a character to an integer index. Each unique character is assigned an index starting from 0.
- Move window of size 100 through text example taking 100 characters as data features (X) next character after them as target value (Y). To explain with an example.
- Characters 1-100 will be data features (X) and character 101 will be the target value (Y).
- Move the window by one character.
- Characters 2-101 will be data features (X) and character 102 will be target value (Y).
- Move the window by one character.
- Characters 3-102 will be data features (X) and character 103 will be target value (Y).
- Move the window by one character.
- ... and so on.
- Retrieve the index for characters present in data features (X) and target values (Y) from our populated vocabulary. This step will transform data from text to integer format.
- For each character index present in data features (X), retrieve embeddings of those characters.
In short, we'll first transform data from text to integer index and then retrieve embeddings for the characters using those indexes. Steps 1-4 will be performed in this section whereas steps will be implemented in the neural network as an embedding layer. We'll update those character embeddings during the training process so that they are learned. Steps will become more clear as we implement them below one by one.
Below, we have included an image for word embeddings which is the same as character embeddings with the only difference being that words are considered tokens instead of characters. It'll give you an idea about embeddings. Embeddings give more representation power to tokens (character/n-gram/word).
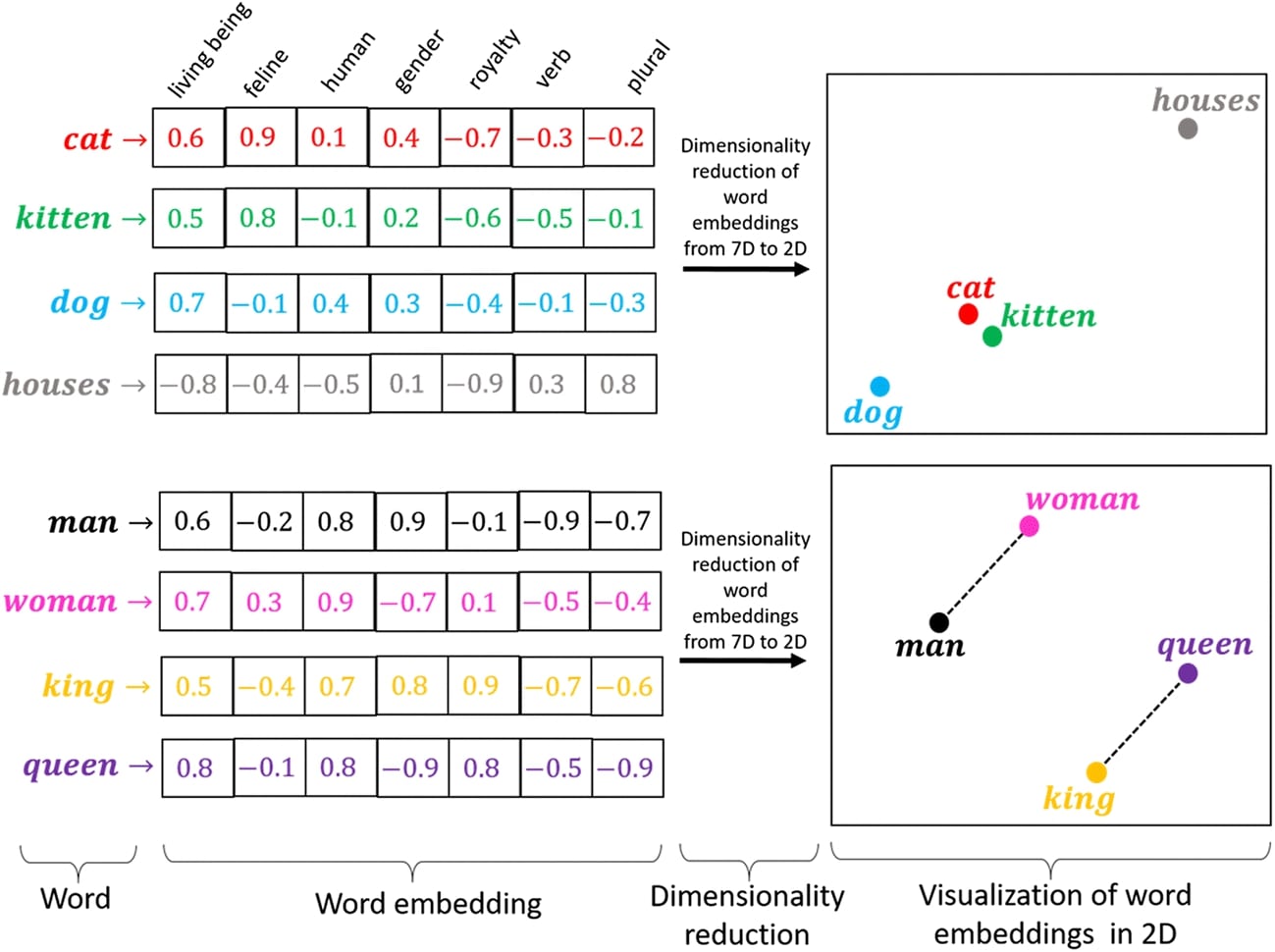
1.1 Load Dataset¶
In this section, we have loaded Wikipedia dataset that we are going to use for our task. The dataset has a bunch of well-curated Wikipedia articles. The dataset is already divided into the train, validation, and test sets. We'll be using a training dataset for our case.
train_dataset, valid_dataset, test_dataset = torchtext.datasets.WikiText2()
X_train_text = [text for text in train_dataset]
len(X_train_text)
1.2 Populate Vocabulary¶
In this section, we have populated the vocabulary of unique characters. In order to populate vocabulary, we have created an instance of Tokenizer available from preprocessing.text module of keras. We have set parameter char_level to True to inform the tokenizer to take characters as tokens. By default, it splits text into words. After defining the tokenizer, we have called fit_on_texts() method on the tokenizer with text examples to populate the vocabulary of unique characters. The vocabulary is available through word_index attribute of the tokenizer object.
After populating vocabulary, we have also printed it for reference purposes.
from keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer(char_level=True)
tokenizer.fit_on_texts(X_train_text)
print(tokenizer.word_index)
1.3 Organize Data¶
In this section, we are readying data for the network. The code loops through the sequence of text examples and move a window of 100 characters through them, adding 100 characters in data features (X_train) and a character after them in target values (Y_train).
Please make a NOTE that we have used fewer text examples for training purposes. The dataset has ~36k text examples and using all of them can take a lot of time.
After organizing data into data features (X_train) and target values (Y_train), we have retrieved the index of characters present in them using populated vocabulary. This index sequences now represents characters and will be given to the network for the training process.
Below, we have explained the data preparation process with a simple example.
vocab = {
'h':1,
'e':2,
'l':3,
'o':4,
' ':5,
',':6,
'w',7,
'a':8,
'r':9,
'y':10,
'u':11,
'?':12,
'c':13,
'm':14,
't':15,
'd':16,
'z':17,
'n':18
}
text_example = "Hello, How are you? Welcome to coderzcolumn?"
seq_length = 10
X_train = [
['h','e','l','l','o',',',' ', 'h','o','w'],
[,'e','l','l','o',',',' ', 'h','o','w',' '],
['l','l','o',',',' ', 'h','o','w', ' ', 'a'],
['l','o',',',' ', 'h','o','w',' ', 'a', 'r'],
...
['d','e','r','z','c','o','l', 'u','m','n']
]
Y_train = ['e','l','l','o',',',' ', 'h','o','w',' ',..., '?']
X_train_vectorized = [
[1,2,3,4,5,6,1,4,7],
[2,3,4,5,6,1,4,7,5],
[3,4,5,6,1,4,7,5,1],
...
[16,2,9,17,13,4,3,11,14,18]
]
Y_train_vectorized = [1,2,3,4,5,6,1,4,7,5,1,...., 12]
%%time
import numpy as np
train_dataset, valid_dataset, test_dataset = torchtext.datasets.WikiText2()
seq_length = 100 ## Network Hyperparameter to tune
X_train, Y_train = [], []
for text in X_train_text[:6000]:## Using few text examples
for i in range(0, len(text)-seq_length):
inp_seq = text[i:i+seq_length].lower()
out_seq = text[i+seq_length].lower()
X_train.append(inp_seq)
Y_train.append(tokenizer.word_index[out_seq]) ## Retrieve index for characters from vocabulary
X_train = tokenizer.texts_to_sequences(X_train) ## Retrieve index for characters from vocabulary
X_train, Y_train = np.array(X_train, dtype=np.int32), np.array(Y_train)
X_train.shape, Y_train.shape
gc.collect()
2. Define Model ¶
In this section, we have defined a model that we'll use for our task. Our task will be considered a classification task as we are predicting one new character from a list of possible vocabulary characters. The network consists of 4 layers.
- Embedding Layer (Embedding Length = 50)
- LSTM Layer (Output Size = 256)
- LSTM Layer (Output Size = 256)
- Dense Layer (Output Units = vocab_size)
The first layer of the network is the embedding layer. We have created a layer using Embedding() constructor. We have provided vocabulary length as the input dimension and embedding length of 50 as the output dimension. This will create a weight matrix of shape (vocab_len, embed_len). This weight matrix has embeddings for each character of the vocabulary. We have already retrieved the index of characters from vocabulary which will be used to index this array to retrieve the embedding of characters. E.g, If index of character 'a' is 1 then weight_matrix[1] will return real-valued vector of shape (embed_len,) = (50,) representing embedding of character 'a'. The input shape to the layer is (batch_size, seq_length) and output data shape is (batch_size, seq_length, embed_len). This output will be given to the first LSTM layer for processing.
The first LSTM layer has 256 output units. It'll process the output of the embedding layer and output processed data of shape (batch_size, seq_length, 256). This output will be given to the second LSTM layer for the processing which will process it and output processed data of shape (batch_size, 256). The second LSTM layer does return the output of all processed sequences because we have not set return_sequences to True. It'll return an output of the last sequence (100th) for each example.
The output of the second LSTM layer is given to a dense layer for processing. The dense layer has the same output units as the length of vocabulary. The softmax activation function is applied to the output of the dense layer to convert them to probabilities.
After initializing the network, we have also printed a summary stating network layer output shapes and parameter counts.
Please make a NOTE that we have not covered embeddings and LSTM layer in deep here. If you are interested to learn about them then please check the below links. They cover topics in little detail for text classification tasks.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Embedding
embed_len = 50
lstm_out = 256
model = Sequential([
Embedding(input_dim=len(tokenizer.word_index)+1, output_dim=embed_len,
input_length=seq_length),
LSTM(lstm_out, return_sequences=True),
LSTM(lstm_out),
Dense(len(tokenizer.word_index)+1, activation="softmax")
])
model.summary()
3. Compile And Train Model ¶
Here, we have first compiled our network to use Adam optimizer and cross entropy loss. After compiling the network, we have trained it for 50 epochs. We have used a batch size of 1024 during training. We can notice from the loss value getting printed after each epoch that our network seems to be doing a good job at the task.
from tensorflow.keras.optimizers import Adam
from keras import backend as K
model.compile(optimizer=Adam(learning_rate=0.001), loss="sparse_categorical_crossentropy")
model.fit(X_train, Y_train, batch_size=1024, epochs=50)
4. Generate Text ¶
In this section, we are generating new text using our trained network. We are starting with randomly selecting an example from our dataset. After selecting an example, we have also printed the characters of the example. Then, we executed a loop 100 times to generate 100 new characters. The first iteration of the loop will start with characters of a randomly selected example. It'll then generate a new character, add it at the end of the selected example and remove the first character from the example to keep the length of sequence 100 characters. This process will be repeated for all iterations where we add a new character at the end and remove an existing first character. After generating 100 new characters, we have also printed them.
We can notice from the results that the network is able to spell words correctly and is also forming sentences. It is also generating punctuation marks. Though the sentences generated does not make much sense but it looks like English language sentence.
import random
random.seed(123)
idx = random.randint(0, len(X_train))
pattern = X_train[idx].flatten().tolist()
print("Initial Pattern : {}".format("".join([tokenizer.index_word[idx] for idx in pattern])))
generated_text = []
for i in range(100):
X_batch = np.array(pattern, dtype=np.int32).reshape(1, seq_length) ## Design Batch
preds = model.predict(X_batch) ## Make Prediction
predicted_index = preds.argmax(axis=-1)[0] ## Retrieve token index
generated_text.append(predicted_index) ## Add token index to result
pattern.append(predicted_index) ## Add token index to original pattern
pattern = pattern[1:] ## Resize pattern to bring again to seq_length length.
print("Generated Text : {}".format("".join([tokenizer.index_word[idx] for idx in generated_text])))
5. Train For More Epochs ¶
In this section, we are training the network for another 50 epochs. We have set the learning rate to 0.0003 for training epochs. We can notice from the loss value getting printed after epochs that the network seems to be improving further.
K.set_value(model.optimizer.learning_rate, 0.0003)
model.fit(X_train, Y_train, batch_size=1024, epochs=50)
6. Generate Text ¶
In this section, we have again generated 100 new characters using our more trained network. Our network is now trained for a total of 100 epochs. We have started with the same example that we used earlier. We can notice from the results that our network is generating new words this time. Though it seems to be repeating some words. We'll train it further for more epochs to see whether it helps improve further.
import random
random.seed(123)
idx = random.randint(0, len(X_train))
pattern = X_train[idx].flatten().tolist()
print("Initial Pattern : {}".format("".join([tokenizer.index_word[idx] for idx in pattern])))
generated_text = []
for i in range(100):
X_batch = np.array(pattern, dtype=np.int32).reshape(1, seq_length) ## Design Batch
preds = model.predict(X_batch) ## Make Prediction
predicted_index = preds.argmax(axis=-1)[0] ## Retrieve token index
generated_text.append(predicted_index) ## Add token index to result
pattern.append(predicted_index) ## Add token index to original pattern
pattern = pattern[1:] ## Resize pattern to bring again to seq_length length.
print("Generated Text : {}".format("".join([tokenizer.index_word[idx] for idx in generated_text])))
7. Train Even More ¶
In this section, we have reduced the learning rate to 0.0001 and trained the network for another 50 epochs. We can notice that loss is reducing further after each epoch which hints that the network is improving further.
K.set_value(model.optimizer.learning_rate, 0.0001)
model.fit(X_train, Y_train, batch_size=1024, epochs=50)
8. Generate Text ¶
In this section, we have again generated new 100 characters using our trained network. We can notice from the results that the network is able to generate English words correctly. It has generated a new-line character as well this time. Next, we'll give some suggestions on how to improve network performance further.
import random
random.seed(123)
idx = random.randint(0, len(X_train))
pattern = X_train[idx].flatten().tolist()
print("Initial Pattern : {}".format("".join([tokenizer.index_word[idx] for idx in pattern])))
generated_text = []
for i in range(100):
X_batch = np.array(pattern, dtype=np.int32).reshape(1, seq_length) ## Design Batch
preds = model.predict(X_batch) ## Make Prediction
predicted_index = preds.argmax(axis=-1)[0] ## Retrieve token index
generated_text.append(predicted_index) ## Add token index to result
pattern.append(predicted_index) ## Add token index to original pattern
pattern = pattern[1:] ## Resize pattern to bring again to seq_length length.
print("Generated Text : {}".format("".join([tokenizer.index_word[idx] for idx in generated_text])))
9. Further Recommendations ¶
- Try training the network for more epochs.
- Try different embedding lengths. We tried embedding a length of 50.
- Try different sequence lengths. We tried a sequence of 100 characters.
- Try different LSTM layers. Please make a NOTE that adding more LSTM layers will increase training time a lot.
- Try different output sizes for LSTM layers.
- Try adding more dense layers after LSTM layers.
- Try n-gram/word based models instead of character-based.
- Try learning rate schedulers
- Try other RNN layers (Vanilla RNN, GRU, etc) for processing sequences.
- Add little randomness to the prediction of the next character. REFERENCE
 Sunny Solanki
Sunny Solanki
Sunny Solanki
Intro: Software Developer | Youtuber | Bonsai Enthusiast
About: Sunny Solanki holds a bachelor's degree in Information Technology (2006-2010) from L.D. College of Engineering. Post completion of his graduation, he has 8.5+ years of experience (2011-2019) in the IT Industry (TCS). His IT experience involves working on Python & Java Projects with US/Canada banking clients. Since 2020, he’s primarily concentrating on growing CoderzColumn.
His main areas of interest are AI, Machine Learning, Data Visualization, and Concurrent Programming. He has good hands-on with Python and its ecosystem libraries.
Apart from his tech life, he prefers reading biographies and autobiographies. And yes, he spends his leisure time taking care of his plants and a few pre-Bonsai trees.
Contact: sunny.2309@yahoo.in



![YouTube Subscribe]() Comfortable Learning through Video Tutorials?
Comfortable Learning through Video Tutorials?
If you are more comfortable learning through video tutorials then we would recommend that you subscribe to our YouTube channel.
![Need Help]() Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
 Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?When going through coding examples, it's quite common to have doubts and errors.
If you have doubts about some code examples or are stuck somewhere when trying our code, send us an email at coderzcolumn07@gmail.com. We'll help you or point you in the direction where you can find a solution to your problem.
You can even send us a mail if you are trying something new and need guidance regarding coding. We'll try to respond as soon as possible.
![Share Views]() Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?
 Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?If you want to
- provide some suggestions on topic
- share your views
- include some details in tutorial
- suggest some new topics on which we should create tutorials/blogs
 keras, LSTM, text-generation, embeddings
keras, LSTM, text-generation, embeddings