MXNet (GluonCV): Object Detection using Pre-Trained Models¶
Object detection is a technology used to detect and label objects present in an image or a video. We show bounding boxes around detected objects and also label (with confidence probability of model for an object being right). It is an active area of research in computer vision and image processing. Over the years, many different approaches have been developed to solve object detection problems. Some of those recently developed approaches use deep neural networks. The majority of these networks use convolution layers in their architecture to capture the features of objects. Many deep learning libraries (PyTorch, Tensorflow, MXNet(GluonCV), OpenCV, etc) provide pre-trained networks that can be used directly to detect objects in images. These can be useful if individuals don't have enough images as well as resources to train such complicated architectures consisting of many layers.
As a part of this article, we explain how to use pre-trained models available from MXNet GluonCV library for object detection. GluonCV is a helper library created by the MXNet team to specifically provide functionalities for computer vision tasks. Currently, GluonCV provides a list of pre-trained models listed below.
- Faster R-CNN
- SSD (Single Shot MultiBox Detector)
- YOLO-v3 (You Only Look Once)
- CenterNet
These networks are generally trained on COCO or Pascal VOC datasets. GluonCV provides two versions of models based on which dataset they are trained. Models use different pre-trained image classification networks like ResNet, VGG, MobileNet, etc for retrieving object features. There are more than one versions of models based on which classification network they are using as the backbone. We have listed below various versions of models available through GluonCV for reference purposes.
Below, we have listed important sections of the tutorial to give an overview of the material covered.
Important Sections Of Tutorial¶
- Load Images
- 1.1 Download and Display Images
- 1.2 Load Images in Memory as MXNet ND Arrays
- Load Pre-Trained Network
- Make Predictions
- Visualize Results
- Try Other Pre-Trained Models
Below, we have imported the necessary Python libraries that we have used in our tutorial and printed the versions of it.
MXNet and GluonCV Installation¶
- !pip install --upgrade mxnet gluoncv
import mxnet
print("MXNet Version : {}".format(mxnet.__version__))
import gluoncv
print("GluonCV Version : {}".format(gluoncv.__version__))
device = mxnet.gpu() if mxnet.test_utils.list_gpus() else mxnet.cpu()
device
1. Load Images ¶
In this section, we have downloaded a few random images from Internet, loaded them in memory using Python Pillow library, and then converted them to MXNet ND Arrays as required by MXNet models.
1.1 Download and Display Images¶
In this section, we have downloaded three images from the Internet that we'll use for our tutorial. GluonCV provides a utility function named download that accepts URLs and downloads files to a local computer. After downloading images, we have loaded them in memory using Python module Pillow and displayed them for reference purposes. We'll look for the presence of objects in these three images. All three images have people and a few other objects which we hope that our pre-trained MXNet model will be able to capture.
from gluoncv import utils
img1 = utils.download("https://www.luxurytravelmagazine.com/files/593/2/80152/luxury-travel-instagram_bu.jpg", "image1.jpg")
img2 = utils.download("https://www.akc.org/wp-content/uploads/2020/12/training-behavior.jpg", "image2.jpg")
img3 = utils.download("https://images.squarespace-cdn.com/content/v1/519bd105e4b0c8ea540e7b36/1555002210238-V3YQS9DEYD2QLV6UODKL/The-Benefits-Of-Playing-Outside-For-Children.jpg", "image3.jpg")
from PIL import Image
Image.open("image1.jpg")

Image.open("image2.jpg")

Image.open("image3.jpg")

1.2 Load Images in Memory as MXNet ND Arrays¶
In this section, we have converted our images to MXNet ND arrays using preprocessing function available from GluonCV.GluonCV provides different types of preprocessing functions based on the MXNet model that we use. We'll be loading a Faster R-CNN model hence we need to pre-process the image and make it ready according to its needs.
GluonCV provides us with method named load_test() from rcnn sub-module which accepts list of Pillow images. It resizes them and returns original as well as resized images. Faster R-CNN can process images with a maximum height of 600 pixels and maximum width of 1000 pixels. The load_test() method will try to bring all images in this range if they have more height/width then can be processed by the model. It'll try to the main aspect ratio of an image. It also normalizes images by subtracting mean ((0.485, 0.456, 0.406)) and dividing by standard deviation ((0.229, 0.224, 0.225)).
Please make a NOTE that we need to use pre-processing function based on a model that we use. If we are using SSD models then we should use ssd sub-module of GluonCV to transform images. It has preprocessing sub-modules for all models.
from gluoncv.data.transforms.presets import rcnn, ssd, center_net, yolo
from mxnet import nd
normalized_batched_imgs, orig_imgs = rcnn.load_test([img1,img2, img3])
for img in orig_imgs:
print(img.shape)
normalized_batched_imgs[0].dtype, orig_imgs[0].dtype
2. Load Pre-Trained Network ¶
GluonCV provides models through model_zoo sub-module. We can retrieve a list of all possible available models by calling get_model_list() method. Below, we have first retrieved all models and then printed versions of Faster R-CNN available. The models that end with coco are trained with COCO dataset and those ending with voc are trained with Pascal VOC dataset. There are feature detection models mentioned as inner string like ResNet50, RestNet101, ResNest101, etc.
Then, in the next cell, we have loaded Faster R-CNN version (faster_rcnn_resnet50_v1b_coco) trained on COCO dataset with ResNet50 as backbone model (responsible for detecting object features). We can load models using get_model() method of model_zoo sub-module by giving model name to it. We have provided pretrained parameter as True because we want to load pre-trained weights. You can set it False if you want to train the model and have enough data for it.
from gluoncv import model_zoo
models_list = model_zoo.get_model_list()
list([model_name for model_name in models_list if "faster_rcnn" in model_name])
faster_rcnn_resnet_coco = model_zoo.get_model("faster_rcnn_resnet50_v1b_coco",
pretrained=True,
ctx=mxnet.Context(device))
3. Make Predictions ¶
Below, we have made predictions on our images using the model loaded in the previous section. In order to make a prediction, we just need to call the model with the preprocessed image we created earlier. The model returns 3 arrays as a prediction.
- box_ids - This array has a list of ids specifying the detected object id. We can transform this id to an object name using mapping available in classes attribute of the model. E.g, box id 1 can be mapped to 'person' object.
- scores - This array has probabilities specifying the confidence of the model in predicting objects. It has one probability for each detected object.
- bboxes - This array has bounding boxes detail for each detected object. It has 4 floats for each object specifying the bounding box (top-x, top-y, bottom-x, bottom-y).
We have made predictions on all three images. Next, we'll visualize original images with bounding boxes to see detected objects. It'll help us check the performance of our model.
%%time
box_ids1, scores1, bboxes1 = faster_rcnn_resnet_coco(normalized_batched_imgs[0])
box_ids1.shape, scores1.shape, bboxes1.shape
box_ids2, scores2, bboxes2 = faster_rcnn_resnet_coco(normalized_batched_imgs[1])
box_ids3, scores3, bboxes3 = faster_rcnn_resnet_coco(normalized_batched_imgs[2])
4. Visualize Results ¶
GluonCV provides us with method named plot_bbox() through viz sub-module that let us visualize bounding boxes around detected objects. It also includes the object target label and probability at the top of the bounding box to show us how confident the model was in detecting this object.
In order to visualize an image with the bounding box, we need to provide the original image, box ids, scores, bounding boxes, and class labels to plot_bbox() method. We can also provide thresh parameter with a value in the range 0-1 specifying a threshold that selects an object whose score is above this threshold.
We can notice from the visualization that our model is able to detect objects like 'person', 'backpack', and 'kite'. It is detecting hot-air balloons as kites and also not detecting all of them in the sky.
from gluoncv.utils import viz
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(14,8))
ax = fig.add_subplot(111)
plt.xticks([]);plt.yticks([]);
viz.plot_bbox(orig_imgs[0],
bboxes=bboxes1[0],
scores=scores1[0],
labels=box_ids1[0],
class_names=faster_rcnn_resnet_coco.classes,
thresh=0.8, fontsize=16, linewidth=2.0,
ax=ax
);
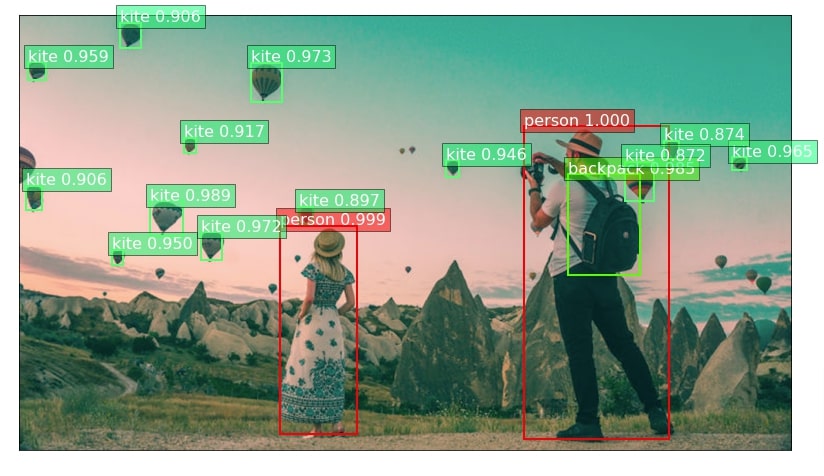
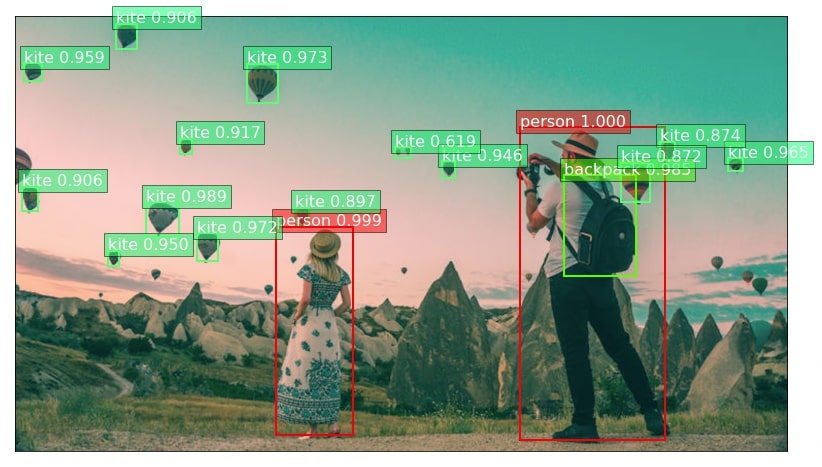
In the below cell, we are again plotting first image with bounding boxes but this time we have kept threshold at 0.5 hence it is detecting few more kites.
from gluoncv.utils import viz
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(14,8))
ax = fig.add_subplot(111)
plt.xticks([]);plt.yticks([]);
viz.plot_bbox(orig_imgs[0],
bboxes=bboxes1[0],
scores=scores1[0],
labels=box_ids1[0],
class_names=faster_rcnn_resnet_coco.classes,
thresh=0.5, fontsize=16, linewidth=2.0,
ax=ax
);
Here, our model is correctly detecting objects 'person', 'sports ball' and 'dog'. It is mistaking person sandal with baseball glove.
from gluoncv.utils import viz
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(14,8))
ax = fig.add_subplot(111)
plt.xticks([]);plt.yticks([]);
viz.plot_bbox(orig_imgs[1],
bboxes=bboxes2[0],
scores=scores2[0],
labels=box_ids2[0],
class_names=faster_rcnn_resnet_coco.classes,
thresh=0.8, fontsize=16, linewidth=2.0,
ax=ax
);

For our third image, model is correctly detecting person and sports ball objects.
from gluoncv.utils import viz
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(14,8))
ax = fig.add_subplot(111)
plt.xticks([]);plt.yticks([]);
viz.plot_bbox(orig_imgs[2],
bboxes=bboxes3[0],
scores=scores3[0],
labels=box_ids3[0],
class_names=faster_rcnn_resnet_coco.classes,
thresh=0.8, fontsize=16, linewidth=2.0,
ax=ax
);
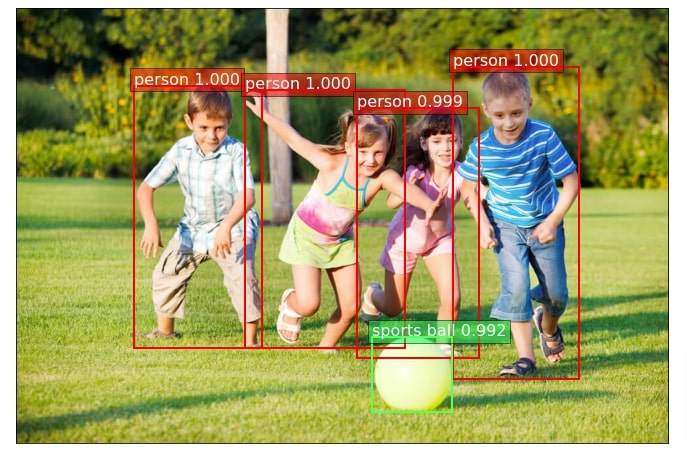
5. Try Other Pre-Trained Models ¶
As we had listed earlier, MXNet GluonCV provides an implementation of many models. If Faster R-CNN model is not giving good results then you can try versions of models like SSD, CenterNet and Yolo as well.
[model for model in models_list if "ssd" in model]
[model for model in models_list if "center" in model]
[model for model in models_list if "yolo" in model]
References¶
 Sunny Solanki
Sunny Solanki
Sunny Solanki
Intro: Software Developer | Youtuber | Bonsai Enthusiast
About: Sunny Solanki holds a bachelor's degree in Information Technology (2006-2010) from L.D. College of Engineering. Post completion of his graduation, he has 8.5+ years of experience (2011-2019) in the IT Industry (TCS). His IT experience involves working on Python & Java Projects with US/Canada banking clients. Since 2020, he’s primarily concentrating on growing CoderzColumn.
His main areas of interest are AI, Machine Learning, Data Visualization, and Concurrent Programming. He has good hands-on with Python and its ecosystem libraries.
Apart from his tech life, he prefers reading biographies and autobiographies. And yes, he spends his leisure time taking care of his plants and a few pre-Bonsai trees.
Contact: sunny.2309@yahoo.in



![YouTube Subscribe]() Comfortable Learning through Video Tutorials?
Comfortable Learning through Video Tutorials?
If you are more comfortable learning through video tutorials then we would recommend that you subscribe to our YouTube channel.
![Need Help]() Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
 Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?When going through coding examples, it's quite common to have doubts and errors.
If you have doubts about some code examples or are stuck somewhere when trying our code, send us an email at coderzcolumn07@gmail.com. We'll help you or point you in the direction where you can find a solution to your problem.
You can even send us a mail if you are trying something new and need guidance regarding coding. We'll try to respond as soon as possible.
![Share Views]() Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?
 Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?If you want to
- provide some suggestions on topic
- share your views
- include some details in tutorial
- suggest some new topics on which we should create tutorials/blogs
 object-detection, mxnet, pre-trained-models
object-detection, mxnet, pre-trained-models