difflib - Simple Way to Find Out Differences Between Sequences/File Contents using Python¶
> Why Compare Sequences?¶
Many times a Python developer needs to compare two sequences (list of numbers, list of strings, list of characters, etc.) to find matching subsequences in between them. These subsequences can help us understand how much two sequences are similar and how different they can have different applications.
The algorithm which does can be useful in various situations like comparing contents of the files, contents of a single string, etc.
> What Solution Python Offers for Comparing Sequences?¶
Python provides us with a module named difflib which can compare sequences of any type for us so that we don't need to write complicated algorithms to find common subsequences between two sequences.
The difflib module provides different classes and methods to perform a comparison of two sequences and generate a delta.
> What Can You Learn From This Article?¶
As a part of this tutorial, we'll be explaining how to use Python module "difflib" to compare sequences of different types with simple and easy-to-understand examples. Apart from basic comparison, Tutorial explains how to generate match ratios of sequences, handle junk characters, generate one sequence from another, etc. It even explains different ways of formatting (HTML, ContextDiff, Differ, etc) different between two sequences. Tutorial covers total API of "difflib" module.
> How "difflib" Works?¶
At the core of the difflib module is SequenceMatcher class which implements an algorithm responsible for comparing two sequences. It requires that all the elements of both sequences be "hashable" in order for them to work.
First, It finds the longest common subsequence between two sequences and then divides both sequences into left parts of both original sequences (left subsequences of original sequences) and right parts of both original sequences (right subsequences of original sequences) based on that common subsequence.
Then, It recursively performs the same function of finding the longest common subsequence on the left parts of both original sequences and the right parts of both original sequences.
The algorithm takes quadratic time for the worst case and linear time for the best case. The expected case time is dependent on the size of sequences and is better than worst-case quadratic time.
The algorithm also automatically takes care of junk elements which are the most commonly occurring elements. If an element appears for more than 1% time of the total elements of the sequence then it's considered a junk element and ignored for subsequence finding.
If you are just interested in comparing the list of files/directories and preparing a report about them then please feel free to check our tutorial on Python module filecmp.
Below, we have listed important sections of tutorial to give an overview of the material covered.
Important Sections Of Tutorial¶
- Simple Sequence Match (SequenceMatcher)
- Sequence Match with Match Ratios (SequenceMatcher)
- String Sequence Match with Junk Characters Removed (SequenceMatcher)
- Operations to Generate Second Sequence from First Sequence (SequenceMatcher)
- Compare List of Strings (Differ)
- Compare File Contents (Differ)
- Generate HTML of Difference Between Files (HtmlDiff)
- Generate HTML Table of Difference Between Files (HtmlDiff)
- Compare List of Strings and Return Difference Context Diff Format (context_diff())
- Compare List of Strings and Return Differ Style Difference (ndiff())
- Compare List of Strings and Return Difference in Unified Diff Format (unified_diff())
- Retrieve Original File Contents/Strings from Difference (restore())
- Find Words from the List which Nearly Matches Given Input Word (get_close_matches())
Example 1: Simple Sequence Match (SequenceMatcher) ¶
As a part of our first example, we'll explain how we can compare two sequences with numbers using SequenceMatcher instance and its methods.
- SequenceMatcher(isjunk=None,a='', b='', autojunk=True) - It accepts two sequences and returns an instance of SequenceMatcher which can be used to find common subsequences.
- isjunk - This parameter accepts a function that takes as input a single element of the sequence and returns True if it junk else False. We can provide function if we want junk elements by ourselves. The default is None.
- autojunk - This parameter accepts boolean value. If set to True, it enables auto junk finding functionality of the algorithm which we described in the introduction section. We can disable it by setting this parameter to False. The default is True.
Important Methods of SequenceMatcher Instance¶
- find_longest_match(alo=0, ahi=None, blo=0, bhi=None) - This method accepts the starting and ending indices of both sequences and returns longest common matching subsequence between two sequences as Match instance.
- The Match instance is a named tuple and has three attributes namely a, b, and size. The a and b attributes specify indices in first and second sequences from where the common sequence starts. The size specifies the length of the subsequence.
- get_matching_blocks() - It returns a list of Match instances which has information about the list of matching subsequences between two sequences.
Our code for this example first creates an instance of SequenceMatcher using two sequences of integers. It then finds out the longest common subsequence using find_longest_match() and prints it. It then finds out the list of common subsequences using get_matching_blocks() and prints them.
import difflib
l1 = [1,2,3,5,6,7, 8,9]
l2 = [2,3,6,7,8,10,11]
seq_mat = difflib.SequenceMatcher(a=l1, b=l2)
match = seq_mat.find_longest_match(alo=0, ahi=len(l1), blo=0, bhi=len(l2))
print("============ Longest Matching Sequence ==================")
print("\nMatch Object : {}".format(match))
print("Matching Sequence from l1 : {}".format(l1[match.a:match.a+match.size]))
print("Matching Sequence from l2 : {}\n".format(l2[match.b:match.b+match.size]))
print("============ All Matching Sequences ==================")
for match in seq_mat.get_matching_blocks():
print("\nMatch Object : {}".format(match))
print("Matching Sequence from l1 : {}".format(l1[match.a:match.a+match.size]))
print("Matching Sequence from l2 : {}".format(l2[match.b:match.b+match.size]))
Example 2: Sequence Match with Match Ratios (SequenceMatcher)¶
As a part of our second example, we'll be explaining various methods of SequenceMatcher instance.
Important Methods of SequenceMatcher Instance¶
- set_seqs(a,b) - It accepts two sequences and sets them as first and second sequence of the SequenceMatcher instance.
- set_seq1(a) - It accepts a single sequence and sets that sequence as the first sequence of the SequenceMatcher instance.
- set_seq2(b) - It accepts single sequence and sets that sequence as second sequence of the SequenceMatcher instance.
- ratio() - It returns float in the range 0-1, specifying similarity between two sequences.
- quick_ratio() - It returns a float in the range 0-1, specifying the upper bound on the similarity between two sequences quickly.
- real_quick_ratio() - It returns a float in the range 0-1, specifying the upper bound on the similarity between two sequences very quickly.
Our code for this example starts by creating an instance of SequenceMatcher without setting any sequences. We have then set both sequences using set_seqs() methods. We have then printed the longest common subsequence and ratios of similarity between two sequences.
We have then set two different sequences as first and second sequence of the SequenceMatcher using set_seq1() and set_seq2() methods. We have then again printed the longest common subsequence and similarity ratios between these two new sequences.
import difflib
l1 = [1,2,3,5,6,7, 8,9]
l2 = [2,3,6,7,8,10,11]
seq_mat = difflib.SequenceMatcher()
seq_mat.set_seqs(l1, l2)
match = seq_mat.find_longest_match(alo=0, ahi=len(l1), blo=0, bhi=len(l2))
print("============ Longest Matching Sequence (l1,l2) ==================")
print("\nMatch Object : {}".format(match))
print("Matching Sequence from l1 : {}".format(l1[match.a:match.a+match.size]))
print("Matching Sequence from l2 : {}".format(l2[match.b:match.b+match.size]))
print("\n=========== Similarity Ratios ==============")
print("Similarity Ratio : {}".format(seq_mat.ratio()))
print("Similarity Ratio Quick : {}".format(seq_mat.quick_ratio()))
print("Similarity Ratio Very Quick : {}".format(seq_mat.real_quick_ratio()))
#####################################################
l3 = [0,1,2,3,4,6,7,8,9]
l4 = [2,3,6,7,8,9,10,11,12,13]
seq_mat.set_seq1(l3)
seq_mat.set_seq2(l4)
match = seq_mat.find_longest_match(alo=0, ahi=len(l3), blo=0, bhi=len(l4))
print("\n\n\n============ Longest Matching Sequence (l3,l4) ==================")
print("\nMatch Object : {}".format(match))
print("Matching Sequence from l3 : {}".format(l3[match.a:match.a+match.size]))
print("Matching Sequence from l4 : {}".format(l4[match.b:match.b+match.size]))
print("\n=========== Similarity Ratios ==============")
print("Similarity Ratio : {}".format(seq_mat.ratio()))
print("Similarity Ratio Quick : {}".format(seq_mat.quick_ratio()))
print("Similarity Ratio Very Quick : {}".format(seq_mat.real_quick_ratio()))
Example 3: String Sequence Match with Junk Characters Removed (SequenceMatcher)¶
As a part of our third example, we are explaining how we can compare strings using SequenceMatcher. We are also explaining how we can use a function with isjunk parameter which will decide which characters to consider as junk. We are also explaining which characters will be considered junk elements when the size of the sequences is greater than 200 elements. Apart from this, we have also explained few important attributes of the SequenceMatcher instance.
Important Attributes of SequenceMatcher Instance¶
- bjunk - It returns a list of characters that are junk in our sequences according to the function supplied to isjunk.
- bpopular - It returns a list of characters that are considered junk in our sequences according to autojunk parameter.
- b2j - It returns a dictionary that has a mapping from elements of second sequences to their position in the sequence. It does not include junk elements.
Our code first creates two sequences that have string data. It then creates an instance of SequenceMatcher. It provides a function to isjunk parameter which considers comma and dot as junk elements. It then finds out the longest common subsequence and prints it. It also prints a list of all subsequences between both strings. It then prints attributes bjunk, bpopular, and b2j of SequenceMatcher instance.
Our code then modifies the second-string further by adding 150 e characters to it. This is done so that the string size becomes more than 200 characters. This will activate the auto junk functionality of the algorithm. We have then again printed attributes bjunk, bpopular, and b2j of SequenceMatcher instance. We can clearly notice a difference in values of the attributes which is now giving results for bpopular attribute.
import difflib
l1 = "Hello, Welcome to CoderzColumn."
l2 = "Welcome to CoderzColumn, Have a Great Learning Day."
seq_mat = difflib.SequenceMatcher(isjunk=lambda x: x in [",", "."], a=l1, b=l2, autojunk=True)
match = seq_mat.find_longest_match(alo=0, ahi=len(l1), blo=0, bhi=len(l2))
print("============ Longest Matching Sequence ==================")
print("\nMatch Object : {}".format(match))
print("Matching Sequence from l1 : {}".format(l1[match.a:match.a+match.size]))
print("Matching Sequence from l2 : {}\n".format(l2[match.b:match.b+match.size]))
print("============ All Matching Sequences ==================")
for match in seq_mat.get_matching_blocks():
if match.size > 0:
print("\nMatch Object : {}".format(match))
print("Matching Sequence from l1 : {}".format(l1[match.a:match.a+match.size]))
print("Matching Sequence from l2 : {}".format(l2[match.b:match.b+match.size]))
print("\nSequence B Junk : {}".format(seq_mat.bjunk))
print("Sequence B Popular : {}".format(seq_mat.bpopular))
print("Sequence B Junk : {}".format(seq_mat.b2j))
l2 = l2 + "e"*150 ### Added 150 e character to make string of lengh more than 200 to make autojunk work.
seq_mat.set_seq2(l2)
print("\nSequence B Junk : {}".format(seq_mat.bjunk))
print("Sequence B Popular : {}".format(seq_mat.bpopular))
print("Sequence B Junk : {}".format(seq_mat.b2j))
Example 4: Operations to Generate Second Sequence from First Sequence (SequenceMatcher)¶
As a part of our fourth example, we'll explain how we can perform list of operations on first sequence to transform it to second sequence using get_opcodes() and get_grouped_opcodes() methods of SequenceMatcher instances.
Important Methods of SequenceMatcher Instance¶
- get_opcodes() - It returns a list of tuples where each tuple has 5 elements (operation, i1, i2, j1, j2) specifying how to transform first sequence to second. The first element is a string specifying one of the operations that should be performed on the first sequence to transform it to seconds. The other four values are 2 indices from the first sequence and 2 indices from the second sequence specifying where operations should be applied. Below are operations that will be returned.
- replace - It specifies that a[i1:i2] should be replaced by b[j1:j2].
- delete - It specifies that a[i1:i2] should be deleted.
- insert - It b[j1:j2] should be inserted at a[i1].
- equal - It means that a[i1:i2] and b[j1:j2] are same and no action is needed.
- get_grouped_opcodes(n=3) - This method returns a generator instance where the individual element is a list of groups specifying operations to be performed to transform the first sequence to the second. It does that with n lines of context.
4.1: Using get_opcodes() Method¶
Our code for this part starts by creating an instance of SequenceMatcher with the same sequence which we had used in the previous example. We then create a third list which is a copy of the first list and has elements as a list of characters. We then loop through each operation returned by get_opcodes() method and perform that operation on the third sequence (which is a copy of the first sequence) to transform it to the second sequence.
import difflib
l1 = "Hello, Welcome to CoderzColumn."
l2 = "Welcome to CoderzColumn, Have a Great Learning Day."
seq_mat = difflib.SequenceMatcher(a=l1, b=l2, autojunk=True)
l3 = list(l1)
for operation, i1,i2,j1,j2 in seq_mat.get_opcodes():
if operation == "delete":
print("Deleting Sequence : '{}' from l1".format(l1[i1:i2]))
l3[i1:i2] = [""] * len(l1[i1:i2])
elif operation == "replace":
print("Replacing Sequence : '{}' in l1 with '{}' in l2".format(l1[i1:i2], l2[j1:j2]))
l3[i1:i2] = [""] * len(l1[i1:i2])
l3.insert(i1, l2[j1:j2])
elif operation == "insert":
print("Inserting Sequence : '{}' from l2 at {} in l1".format(l2[j1:j2], i1))
l3.insert(i1, l2[j1:j2])
elif operation == "equal":
print("Equal Sequences. '{}' No Action Needed.".format(l1[i1:i2]))
print("\nFinal Sequence : {}".format("".join(l3)))
4.2: Using get_grouped_opcodes() Method¶
Our code for this part starts by creating an instance of SequenceMatcher with the same sequence which we had used in previous examples. We then create a third list which is a copy of the first list and has elements as a list of characters. We then loop through each group returned by get_grouped_opcodes() method and perform operations specified in each group on the third sequence (which is a copy of the first sequence) to transform it to the second sequence.
import difflib
l1 = "Hello, Welcome to CoderzColumn."
l2 = "Welcome to CoderzColumn, Have a Great Learning Day."
seq_mat = difflib.SequenceMatcher(a=l1, b=l2, autojunk=True)
l3 = list(l1)
for groups in seq_mat.get_grouped_opcodes(n=8):
for operation, i1,i2,j1,j2 in groups:
if operation == "delete":
print("Deleting Sequence : '{}' from l1".format(l1[i1:i2]))
l3[i1:i2] = [""] * len(l1[i1:i2])
elif operation == "replace":
print("Replacing Sequence : '{}' in l1 with '{}' in l2".format(l1[i1:i2], l2[j1:j2]))
l3[i1:i2] = l2[j1:j2]
elif operation == "insert":
print("Inserting Sequence : '{}' from l2 at {} in l1".format(l2[j1:j2], i1))
l3.insert(i1, l2[j1:j2])
elif operation == "equal":
print("Equal Sequences. '{}' No Action Needed.".format(l1[i1:i2]))
print("\nFinal Sequence : {}".format("".join(l3)))
Example 5: Compare List of Strings (Differ) ¶
As a part of our fifth example, we'll explain how we can compare the list of strings using Differ class of difflib module.
- Differ(linejunk=None, charjunk=None) - It accepts two parameters which specify which accepts functions specifying which lines should be considered as junk and which character should be considered as junk. The default is None for both parameters hence nothing is considered junk.
The Differ internally uses SequenceMatcher for finding sequence on the list of strings to find common subsequences between two original sequences and then on a list of characters to find subsequences between individual elements of both original subsequences.
Our code for this part starts by creating two strings from the contents of zen of Python (import this). We have then created an instance of Differ which has a method named compare() which accepts two lists of strings and compares them. We have then compared two strings using compare() methods and printed their result. We have split strings into a list of strings using splitlines() method of string which splits strings based on a new line character.
We can notice from the output that there are four kinds of lines in the output.
- The lines starting with character '-' are lines present in sequence 1.
- The lines starting with character '+' are lines present in sequence 2.
- The lines starting with character ' ' are lines present in both sequences.
- The lines starting with character '?' are lines present in neither sequences but have characters that hint which characters were changed (added/removed) between two sequences.
import difflib
a = '''
1. Readability counts.
2. Special cases aren't special enough to break the rules.
3. Errors should never pass silently.
4. In the face of ambiguity, refuse the temptation to guess.
5. There should be one-- and preferably only one --obvious way to do it.
6. Although that way may not be obvious at first unless you're Dutch.
7. Now is better than never.
8. Although never is often better than *right* now.
9. If the implementation is hard to explain, it's a bad idea.
10. If the implementation is easy to explain, it may be a good idea.
'''
b = '''
1. Simplicy counts as well.
2. Special cases aren't that special enough to break the rules.
3. Errors shall never pass ever.
4. In the face of ambiguity, refuse the temptation to guess.
5. There should be one obvious way to do it.
6. Although that way may not be obvious at first unless you're Dutch.
7. Now is better than never.
8. Although never is often better than immediately.
9. If the implementation is hard to code, it's most probably a bad idea.
'''
difference = difflib.Differ()
for line in difference.compare(a.splitlines(keepends=True), b.splitlines(keepends=True)):
print(line, end="")
Example 6: Compare File Contents (Differ) ¶
As a part of our sixth example, we are again using Differ to explain how we can compare the contents of two files.
We have saved our strings from previous examples in files named original.txt and modified.txt. We have then read the contents of both files and compared them using Differ. We can notice from the result that it is exactly the same as the previous example.
import difflib
a = open("original.txt", "r").readlines()
b = open("modified.txt", "r").readlines()
difference = difflib.Differ(charjunk=lambda x: x in [",", ".", "-", "'"])
for line in difference.compare(a, b):
print(line, end="")
Example 7: Generate HTML of Difference Between Files (HtmlDiff)¶
As a part of our seventh example, we'll explain how we can generate a difference between two sequences in HTML format where the table shows the difference between two sequences side by side using different colors. The difflib provides a class named HtmlDiff for this purpose.
- HtmlDiff(tabsize=8,wrapcolumn=None,linejunk=None,charjunk=IS_CHARACTER_JUNK) - This constructor creates an instance of HtmlDiff which we can then use to generate difference between two list of strings in an HTML format. The tabsize parameter specifies the size of the tab. The wrapcolumn parameter accepts the number and specifies after how many characters, the string should be wrapped on the next line.
Important Methods of HtmlDiff Instance¶
- make_file() - This method returns a string that has HTML showing differences between two lists of strings where each line is shown side by side between two lists and the difference is highlighted with different colors.
Our code for this part reads two files which we used in our previous example. We are then creating an instance of HtmlDiff to compare the list of strings. We then call make_file() method of HtmlDiff to compare two sequences and return comparison result in HTML format. We are then storing the result in compare.html file.
We are using display module of IPython to display an HTML file in jupyter notebook. The output presented in this format is easy to understand and interpret.
If you are interested in learning about how contents of different types like HTML, audio, video, etc can be displayed in the Jupyter notebook then please feel free to check our tutorial on the same.
import difflib
from IPython import display
a = open("original.txt", "r").readlines()
b = open("modified.txt", "r").readlines()
difference = difflib.HtmlDiff(tabsize=2)
with open("compare.html", "w") as fp:
html = difference.make_file(fromlines=a, tolines=b, fromdesc="Original", todesc="Modified")
fp.write(html)
display.HTML(open("compare.html", "r").read())
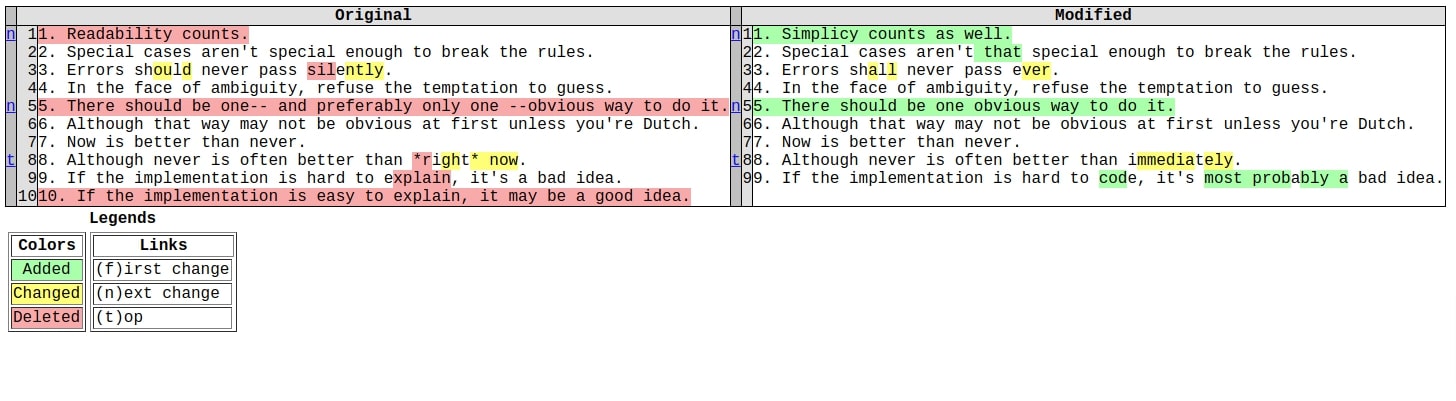
Example 8: Generate HTML Table of Difference Between Files (HtmlDiff)¶
We are using our eighth example again to show differences between two lists of strings in HTML format. We are explaining usage of make_table() method of HtmlDiff instance this time. This can be useful when we only want difference as an HTML table so that we can include it in some HTML of our own. We might now always need the whole HTML ready if we want to include a table in some rich HTML of our own.
Important Methods of HtmlDiff Instance¶
- make_table() - This method returns a string that has an HTML table showing differences between two lists of strings where each line is shown side by side between two lists and the difference is highlighted with different colors.
Our code for this example is exactly the same as our previous example with the only change that we are using make_table() method instead of make_file().
import difflib
from IPython import display
a = open("original.txt", "r").readlines()
b = open("modified.txt", "r").readlines()
difference = difflib.HtmlDiff(tabsize=2)
with open("compare.html", "w") as fp:
html = difference.make_table(fromlines=a, tolines=b, fromdesc="Original", todesc="Modified")
fp.write(html)
display.HTML(open("compare.html", "r").read())
Example 9: Compare List of Strings and Return Difference Context Diff Format (context_diff())¶
As a part of our ninth example, we'll be demonstrating how we can show the difference between two lists of strings in a contextual difference format using context_diff() method. The contextual difference is a simple way of showing which lines are changed along with few other lines around them to show context.
- context_diff(a,b,fromfile='',tofile='',fromfiledate='',tofiledate='') - It compares two list of strings and returns difference between them in contextual difference format. It even let us set file names and dates for two sequences.
Our code for this example reads the content of two files that we had created in one of our previous examples. It then finds out the contextual differences between them using context_diff() function and prints difference. The output has lines starting with the character '!' to show that it has the difference between the two sequences.
import difflib
a = open("original.txt", "r").readlines()
b = open("modified.txt", "r").readlines()
difference = difflib.context_diff(a, b,
fromfile="original.txt", tofile="modified.txt",
fromfiledate="2021-02-19", tofiledate="2021-02-20")
for diff in difference:
print(diff, end="")
Example 10: Compare List of Strings and Return Differ Style Difference (ndiff())¶
As a part of our tenth example, we'll explain the usage of function ndiff() of module difflib which gives the same functionality that is available through Differ instance.
- ndiff(a,b,linejunk=None,charjunk=IS_CHARACTER_JUNK) - This method accepts two lists of strings as input and returns a generator that has a list of lines showing the difference between two lists. It also lets us specify linejunk and charjunk parameters which accept functions for finding out which lines and characters to consider as junk.
Our code for this example is pretty self-explanatory which uses files that we have been using for many examples. It finds out the difference between the contents of the files using ndiff() method and prints it.
import difflib
a = open("original.txt", "r").readlines()
b = open("modified.txt", "r").readlines()
for diff in difflib.ndiff(a, b):
print(diff, end="")
Example 11: Compare List of Strings and Return Difference in Unified Diff Format (unified_diff())¶
As a part of our eleventh example, we are demonstrating how we can show the difference between two lists of strings in a unified format using unified_diff() method of difflib module. The unified difference format just shows lines that are changed plus a few lines around them to show context.
- unified_diff(a,b,fromfile='',tofile='',fromfiledate='',tofiledate='',n=3,lineterm='\n') - This method compares two list of strings and returns their difference in unified format. It also let us specify file names and dates for both lists. The n parameter accepts integer specifying number of lines to show around the lines which are changed for contextual purpose.
Our code for this example like many of our previous examples starts by reading two text files created earlier. It uses unified_diff() method this time to find out the difference and print it.
import difflib
a = open("original.txt", "r").readlines()
b = open("modified.txt", "r").readlines()
diff = difflib.unified_diff(a,b,
fromfile="original.txt", tofile="modified.txt",
fromfiledate="2020-02-19", tofiledate="2020-02-20"
)
for line in diff:
print(line, end="")
Example 12: Retrieve Original File Contents/Strings from Difference (restore())¶
As a part of our twelfth example, we are demonstrating how we can generate an original list of strings based on the difference that we found out between them. The difflib module provides method named restore() for this purpose. The restore() method can generate original list of strings from difference generated from Differ instance or ndiff() method only.
- restore(difference, which) - It accepts the difference between sequences as the first parameter and an integer 1 or 2 as the second parameter specifying which sequence it wants to retrieve.
12.1: From Difference Generated from Differ Instance¶
Our code for this example first finds the difference between the contents of two files using Differ instance. It then uses this difference to find our contents of the first and second files both using restore() method. We have been using both files since many of our last examples.
import difflib
a = open("original.txt", "r").readlines()
b = open("modified.txt", "r").readlines()
difference = difflib.Differ()
diff = difference.compare(a, b)
original_file_contents = difflib.restore(diff, 1)
print("============== Original File Contents ====================\n")
for line in original_file_contents:
print(line, end="")
difference = difflib.Differ()
diff = difference.compare(a, b)
modified_file_contents = difflib.restore(diff, 2)
print("\n\n============== Modified File Contents ====================\n")
for line in modified_file_contents:
print(line, end="")
12.2: From Difference Generated from ndiff() Method¶
Our code for this example first finds the difference between the contents of two files using ndiff() method. It then uses this difference to find our contents of the first and second files both using restore() method.
import difflib
a = open("original.txt", "r").readlines()
b = open("modified.txt", "r").readlines()
diff = difflib.ndiff(a, b)
original_file_contents = difflib.restore(diff, 1)
print("============== Original File Contents ====================\n")
for line in original_file_contents:
print(line, end="")
diff = difflib.ndiff(a, b)
modified_file_contents = difflib.restore(diff, 2)
print("\n\n============== Modified File Contents ====================\n")
for line in modified_file_contents:
print(line, end="")
Example 13: Find Words from the List which Nearly Matches Given Input Word (get_close_matches())¶
We'll use our thirteenth example to demonstrate how we can find out the list of words from the given list of words that somewhat matches (not compulsory 100% match ) a particular word given as input. We can do this using get_close_matches() method of difflib.
- get_close_matches(word,list_of_strings,n=3,cutoff=0.6) - This method accepts word and list of words as input and returns a list that has words that somewhat matches the input word.
- The parameter n accepts integer value specifying a maximum number of matching words to return. The returned list's length can be less than or equal to this number.
- The cutoff parameter accepts float in the range 0-1 specifying how much matching a word should be matched to the given input word to be considered as matching.
Our code for this example simply tries different values of parameters of method get_close_matches() to see how they impact the results.
import difflib
matches = difflib.get_close_matches("micro", ["macro", "crow", "cream", "nonsense", "none"])
print(matches)
matches = difflib.get_close_matches("micro", ["macro", "crow", "cream", "nonsense", "none"], n=1)
print(matches)
matches = difflib.get_close_matches("micro", ["macro", "crow", "cream", "nonsense", "none"], n=3, cutoff=0.4)
print(matches)
matches = difflib.get_close_matches("micro", ["macro", "crow", "cream", "nonsense", "none"], n=2, cutoff=0.4)
print(matches)
This ends our small tutorial explaining how we can compare sequences with different types of data using difflib module.
 Sunny Solanki
Sunny Solanki
Sunny Solanki
Intro: Software Developer | Youtuber | Bonsai Enthusiast
About: Sunny Solanki holds a bachelor's degree in Information Technology (2006-2010) from L.D. College of Engineering. Post completion of his graduation, he has 8.5+ years of experience (2011-2019) in the IT Industry (TCS). His IT experience involves working on Python & Java Projects with US/Canada banking clients. Since 2020, he’s primarily concentrating on growing CoderzColumn.
His main areas of interest are AI, Machine Learning, Data Visualization, and Concurrent Programming. He has good hands-on with Python and its ecosystem libraries.
Apart from his tech life, he prefers reading biographies and autobiographies. And yes, he spends his leisure time taking care of his plants and a few pre-Bonsai trees.
Contact: sunny.2309@yahoo.in



![YouTube Subscribe]() Comfortable Learning through Video Tutorials?
Comfortable Learning through Video Tutorials?
If you are more comfortable learning through video tutorials then we would recommend that you subscribe to our YouTube channel.
![Need Help]() Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
 Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?When going through coding examples, it's quite common to have doubts and errors.
If you have doubts about some code examples or are stuck somewhere when trying our code, send us an email at coderzcolumn07@gmail.com. We'll help you or point you in the direction where you can find a solution to your problem.
You can even send us a mail if you are trying something new and need guidance regarding coding. We'll try to respond as soon as possible.
![Share Views]() Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?
 Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?If you want to
- provide some suggestions on topic
- share your views
- include some details in tutorial
- suggest some new topics on which we should create tutorials/blogs
 difflib, sequence-comparison
difflib, sequence-comparison