Recurrent Neural Network(RNN)¶
Recurrent Neural Network is a kind of artificial neural network which are ideal for solving problem which involves temporal data or data with context. By temporal/contextual data, we mean that predicting the current value of some target variable has a dependency on the value of few or all previous target variables. We can consider time series data where we need to predict the stock price based on prices from previous days or language processing where we need to predict the next word in sequence based on previous words as temporal/contextual data. When we are faced with a problem that involves working with this kind of data, then we need models that provide some memory to store information about context/temporal information. RNN's architecture provides us with that kind of setup. RNNs are also ideal for a situation where input is a variable-length sequence like language processing. RNN models work well when traditional CNN and feed-forward neural networks fail at accurately solving problems involving temporal/contextual data. We'll be explaining below in-depth about how RNN works as well as basic information about its variants along with few applications where RNN excels.
How RNN Works(RNN Architecture)?¶
We'll take a simple example of the next character prediction to form a sentence based on previous characters. Let's say for example you have 2 characters of a sentence and you want to predict 3rd character in the sequence. We can design a simple feed-forward network that can do it as shown in the below image.
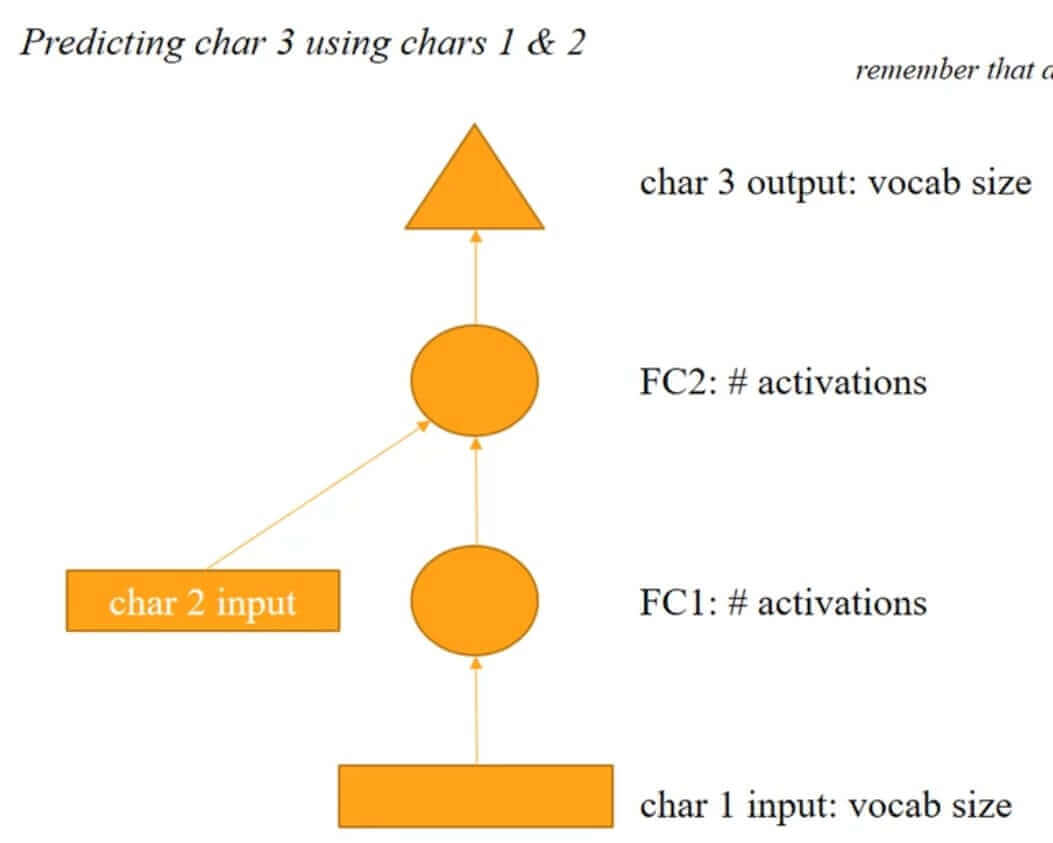
Note: Triangle represents output, the circle represents the hidden layer and the rectangle represents the input layer. FC refers to a fully connected layer(Dense layer of Keras/Linear layer in Pytorch).
We can see from the above image that the first character will be given as input to the first hidden layer. The output of the first hidden layer along with 2nd character will be given as input to the second hidden layer which will produce output after applying the activation function. Please make a note that the output of the first hidden layer and 2nd character will be merged before giving input to the second hidden layer. We are ignoring the use of activation functions and a number of nodes in layers as of now to understand the concept of RNN. We'll update layer weights based on the comparison of output with actual output. We can then move one character further taking the next 2 characters to predict character after it and keep on updating weights in the whole training process. But this network can only handle 2 characters to produce 3rd character which is a limitation of this architecture. What if we want to use 3 characters to predict the 4th character or generate the whole sentence?
We can extend the above architecture as depicted in the image below.
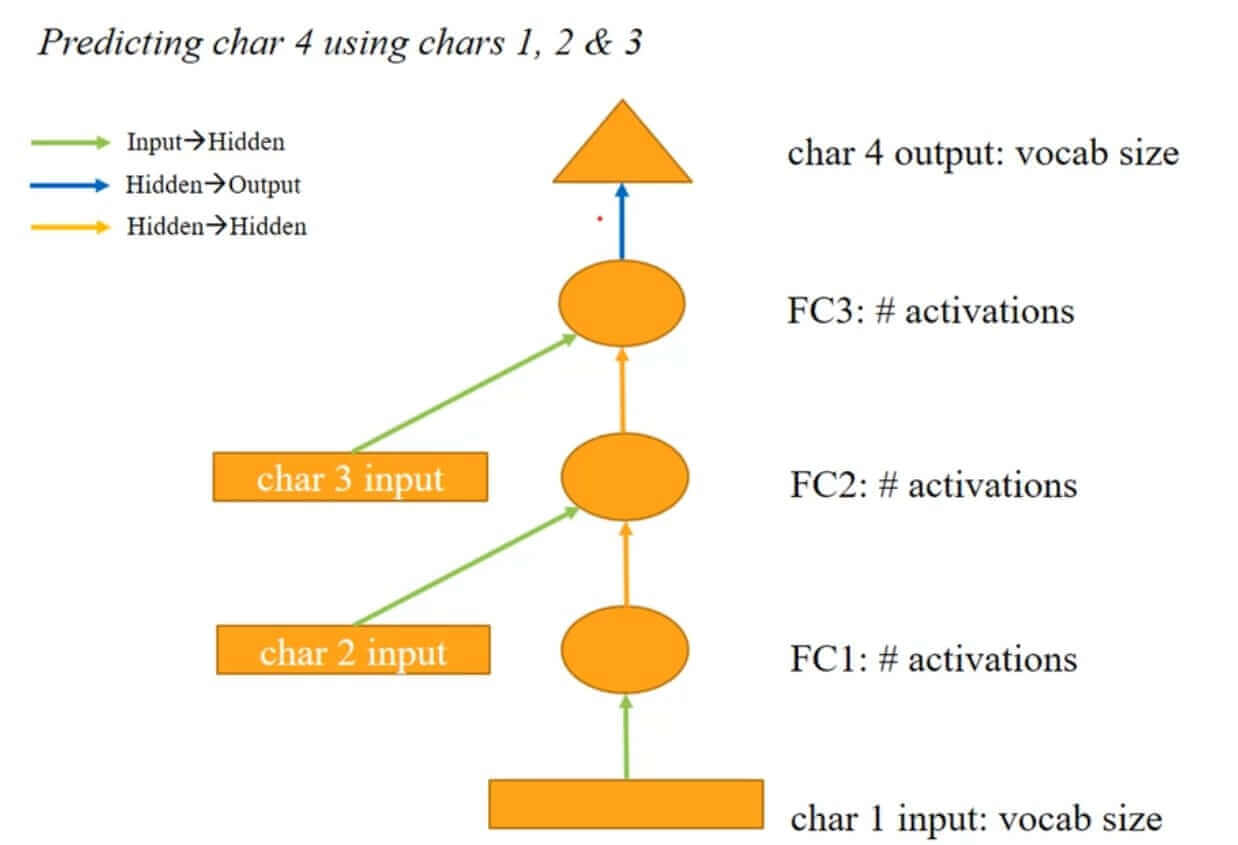
We can notice from the above image that it has almost the same architecture as that of 2 characters network but with one more layer for memorizing information about the third character. We can use this network to predict the 4th character based on the previous 3 characters. This network also has the same limitation as that of the previous network. We can not extend it hence this proves the point that our traditional feedforward networks are not ideal for handling variable-length sequences of input which is quite common in natural language processing.
To solve this problem and maintaining information about context/temporal (memory) RNNs are designed. We have depicted below simple RNN architecture which can replace both previous models.
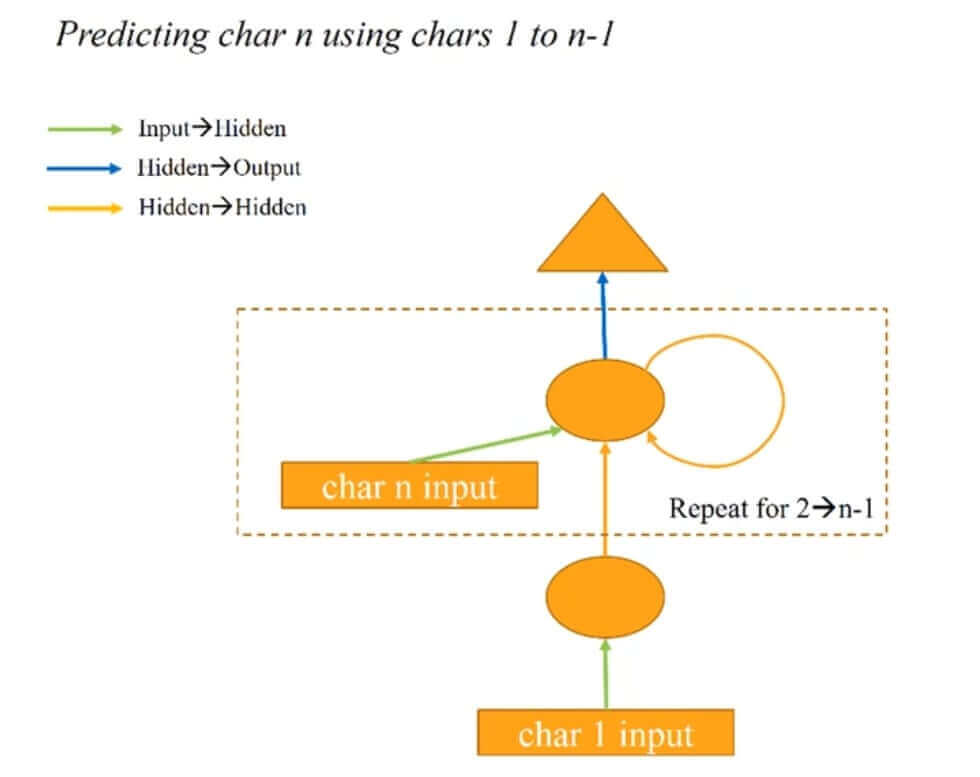
We can see from the above architecture that there is a ring arrow that points to the same layer for the 2nd hidden layer. RNN has typically only one hidden layer which maintains information about the context and only it's weights are updated during the training process rather than maintaining different weights for many possible hidden layers. Due to this architecture, RNN has a number of parameters quite less compared to any CNN or feed-forward network. We can further extend the above architecture and remove the first hidden layer by initializing first input with zeros instead of giving the first character there. The below image depicts the architecture of RNN.
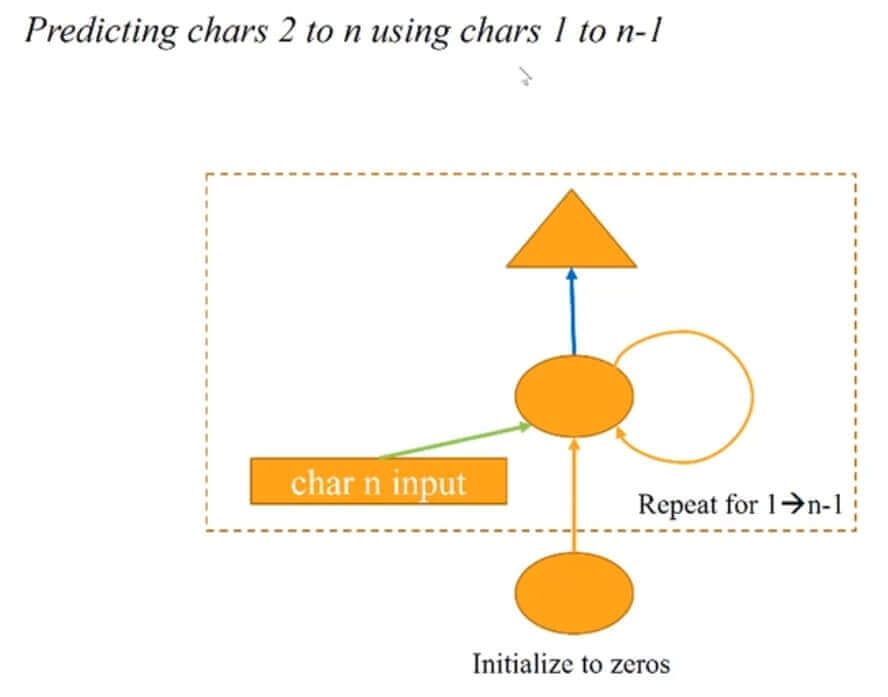
One can implement above architecture using simple dense/linear layers available in libraries like Keras/Pytroch/Tensorflow but these libraries also provide a ready layer for RNNs which can be used for the purpose.
When updating weights for the RNN layer, the backpropagation algorithm used in the feed-forward network will not work and one needs to use another variant of it called backpropogation through time. It unfolds the RNN layer through time to find out gradients. RNN architectures commonly use tanh, relu and sigmoid as activation functions.
Training RNNs is a very difficult task as one needs to perform various trial and error to come to decision about model effectiveness. RNNs also suffer from exploding and vanishing gradient problems. The gradient clipping technique is commonly used to keep limits on gradients to prevent it from exploding. Simple RNNs can not hold information from a very long time ago (Ex: Predictions are based on the last few observations and not all last observations). There are different variants of RNN which do not suffer from all limitations of simple RNNs. We'll now give a short overview of a few variants of RNNs.
Types of RNNs¶
Below we'll be giving a short overview of some of the famous RNN variants. We'll be covering each one in-depth in future blogs.
1. Stacked RNN¶
Simple RNN consists of a single hidden RNN layer that maintains the memory part of the model followed by a feed-forward dense layer. Stacked RNN consist of multiple RNN layers stacked together with each having its memory unit. The output sequence of one RNN layer is given as input to another RNN layer as part of this architecture. A deeper network is better at memorizing context/temporal data than architecture with one RNN layer.
2. Bidirectional RNN¶
Bidirectional RNN consist of putting two RNN together with inputting sequence in normal time order for one RNN and reverse time order for another RNN.This kind of structure allows a neural network to have forward and backward information about sequence at the same time. It kind of uses the future and past to predict the current label. Two RNN works in reverse direction and later their output is combined.
3. LSTM (Long Short-Term Memory) Networks¶
LSTM is a kind of neural network architecture that tries to solve a problem with training normal RNN like exploding/vanishing gradients. It can also take more observations into consideration for predicting the target variables than simple RNNs. There are various architectures of LSTM but quite common is one containing cell(memory of LSTM) and three gates(input gate, output gate and forget gate) which helps with maintaining memory part. The logistic sigmoid function is commonly used as activation function of LSTM. LSTMs can also be stacked together to create stacked LSTM which will perform quite better than a network with one LSTM layer.
4. GRU (Gated Recurring Unit) Networks¶
Gated Recurring Unit is a kind of recurrent neural network which has the almost the same architecture as LSTM with forget gate but has fewer parameters than LSTM because of an absence of output gate.LSTM generally outperforms GRU on large datasets.
Applications of RNNs:¶
- LSTMs can be used for time-series data like stock price prediction.
- Natural Language processing
- Music Generation
- Handwriting Recognition
- Sentiment Classification
- Speech Recognition
- Machine translation (The task of converting source text in one language to text in another language.)
- LSTMs cab be used to detect anomaly in network traffic.
- LSTMs can be used to understand language grammar.
- HTML start-end tag detection.
- LSTMs can be used to detect malicious URLs as well.
References¶
This blog is inspired from below mentioned sources:
- fast.ai - Blog is inspired by lectures of fast.ai course and images are taken from course materials as well.
- Recurrent Neural Network Wikipedia
 Sunny Solanki
Sunny Solanki
Sunny Solanki
Intro: Software Developer | Youtuber | Bonsai Enthusiast
About: Sunny Solanki holds a bachelor's degree in Information Technology (2006-2010) from L.D. College of Engineering. Post completion of his graduation, he has 8.5+ years of experience (2011-2019) in the IT Industry (TCS). His IT experience involves working on Python & Java Projects with US/Canada banking clients. Since 2020, he’s primarily concentrating on growing CoderzColumn.
His main areas of interest are AI, Machine Learning, Data Visualization, and Concurrent Programming. He has good hands-on with Python and its ecosystem libraries.
Apart from his tech life, he prefers reading biographies and autobiographies. And yes, he spends his leisure time taking care of his plants and a few pre-Bonsai trees.
Contact: sunny.2309@yahoo.in



![]() Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?
 Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?If you want to
- provide some suggestions on topic
- share your views
- include some details in tutorial
- suggest some new topics on which we should create tutorials/blogs
 rnn, lstm, gru, neural-net
rnn, lstm, gru, neural-net