Basics of Machine Learning¶
Machine Learning is the process of extracting some kind of knowledge from data and later on, using this knowledge to make predictions about new unseen data.
The main aim behind machine learning is to automate decision making from data without developers manually specifying rules about the decision-making process and progress towards Artificial General Intelligence. The process of manually specifying rules will be exhausting and developers won't be able to specify all rules explicitly covering all scenarios.
As a part of the machine learning process, developers are given data which is generally historical data and fields for which prediction needs to be made in the future. If historical data provided is not clean then developers need to spend time cleaning data doing various activities like taking a decision on NAs, removing duplicate entries, converting data into the proper format for doing analysis and using Machine Learning Algorithm/Model. Developers then spend time analyzing data doing exploratory data analysis, analyzing the relationship between the target and other variables, making visualization explaining relationships. Once developers are done with initial analysis, they divide data generally into 3 sets (1. Train Set 2. Validation Set 3. Test Set ). After that developer spends time finding outright algorithm/model on which he/she trains a model and tests its performance on the validation set in parallel. Once the developer finds out that the algorithm/model is performing well on Train & Validation Set then a final round of testing is performed on Test Set. If the algorithm/model performs well on Test Set as well then the developer can be sure that the model generalizes well. If algorithms do not perform well on Validation/Test Set then the developer generally modifies few parameters of algorithm/model and then trains again. If that does not work as well then developers generally need to resort to designing another algorithm/model. The process is repeated from the designing model till the end until developers find the right algorithm/model which generalizes well. Once developers find a right algorithm that generalizes when then it's put into production for making predictions on future unseen data.
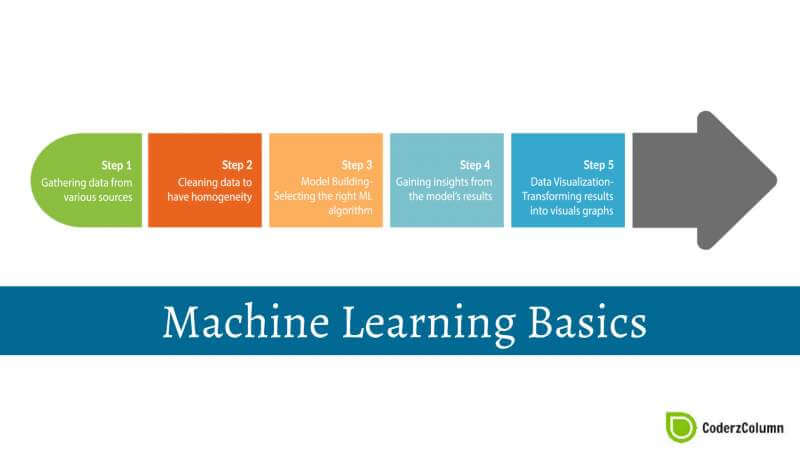
Whole Machine Learning Process has below mentioned stages generally performed by most of developers:
- Data Collection.
- Data Cleaning.
- Exploratory Data Analysis / Visualising Data .
- Feature Extraction / Feature Selection
- Designing Machine Learning Model based on Task context.
- Diving Data into Train,Validation, Test Sets.
- Training Model on Train Set and verifying on Validation Set
- Final testing on Test Set to check Generalization of Model.
- Deploy well Generalized Model to production for doing future prediction on unseen data.
Types of Machine Learning:¶
Supervised Machine Learning: In supervised machine learning, developers are given which target variable they need to predict in the future upon completion of building successful ML Algorithm/Model. The task of learning for algorithm/model is supervised by telling it what to predict hence called supervised machine learning.
Regression: Refers to the type of supervised machine learning where the predicted output variable is continuous.
Examples of regression:
* Based on persons age, education and few other personal attributes, predict his/her salary. * Based on attributes of apartment, predict its expected sale price.Classification: Refers to the type of supervised machine learning where the predicted output variable is discrete/categorical (nominal variable, not ordinal).
Examples of classification:
* Given list of images of flowers, determine flower name * Given data about few tumor patients data, predict for future patient whether he/she has a malignant tumor or not. * Determine comment on quora is toxic or not.
Unsupervised Machine Learning: In unsupervised machine learning, developers are not given any insight into data like supervised and they need to design algorithm/model which can help find out some insight/structure from data without any prior knowledge about data.
Clustering: Refers to a type of unsupervised machine learning where algorithm/model tries to divide data into clusters where each cluster has data of same type/characteristics.
Examples of clustering:
* Given the mixture of sound from different sources, separate sounds from different sources. * Cluster bunch of PDFs into clusters based on their contents. * Clusters students into a cluster based on their performances through various exams to design custom coaching plans as per the performance of a student.Dimensionality Reduction : Refers to type of unsupervised machine learning where algorithm/model tries to represent original data as lower dimension data hence resulting in taking less space but still does have the same meaning/characteristics of original data. Also refers to as
data compressionby some in ML community.Examples of dimensionality reduction:
* Data compression which will be used by other Machine Learning Models.
- Reinforcement Machine Learning: It's a type of machine learning where the ML algorithm/model takes action in an environment in a way that maximizes cumulative reward.
 Sunny Solanki
Sunny Solanki
Sunny Solanki
Intro: Software Developer | Youtuber | Bonsai Enthusiast
About: Sunny Solanki holds a bachelor's degree in Information Technology (2006-2010) from L.D. College of Engineering. Post completion of his graduation, he has 8.5+ years of experience (2011-2019) in the IT Industry (TCS). His IT experience involves working on Python & Java Projects with US/Canada banking clients. Since 2020, he’s primarily concentrating on growing CoderzColumn.
His main areas of interest are AI, Machine Learning, Data Visualization, and Concurrent Programming. He has good hands-on with Python and its ecosystem libraries.
Apart from his tech life, he prefers reading biographies and autobiographies. And yes, he spends his leisure time taking care of his plants and a few pre-Bonsai trees.
Contact: sunny.2309@yahoo.in



![]() Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?
 Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?If you want to
- provide some suggestions on topic
- share your views
- include some details in tutorial
- suggest some new topics on which we should create tutorials/blogs
 machinelearning
machinelearning